

Una guía sobre la Plantilla Universal y cómo optimizar su experiencia con las funciones.
La {{glosario.Plantilla.Universal}} es una experiencia única para construir análisis sin problemas. Te permite cambiar entre tipos de visualización desacoplando la consulta y la visualización de los datos. La plantilla universal es compatible con todos los tipos de análisis y fuentes de datos de Tulip (finalizaciones, datos de tabla y datos de máquina).

Uso de consultas y visualizaciones
La consulta es como una instrucción que le das al sistema detallando lo que quieres que haga con tus datos "brutos" de una App, una máquina o en una tabla Tulip. El resultado de la consulta es una representación tabular de los datos creados por Tulip Analytics en función de la configuración de la consulta. La consulta se configura en el panel lateral izquierdo del Analytics Editor.
Puede visualizar los datos de esa consulta con diferentes visualizaciones, mostrando todos o sólo partes seleccionadas de los mismos. La visualización se selecciona en la parte superior del Editor de análisis y se configura en el panel lateral derecho del Editor de análisis.
Siempre puede ver el resultado de la consulta debajo de la visualización si hace clic en Mostrar resultado de la consulta, a menos que tenga seleccionada la visualización "Tabla".
Construcción de la consulta
Fuente de datos
Una fuente de datos es aquello sobre lo que se construye el análisis. Puede elegir entre los datos de finalización de una aplicación, datos de tabla o datos de máquina.
Si está creando un análisis para los datos de finalización de una aplicación, puede seleccionar varias aplicaciones. Esto hará que el análisis considere los registros de finalización de todas las aplicaciones seleccionadas.
Tenga en cuenta que si se seleccionan varias aplicaciones, los datos no se unirán, sino que cada finalización se tratará como una fila independiente. Esto significa que podrá analizar conjuntamente los "Campos" de las finalizaciones (por ejemplo, Usuario, Hora de inicio y Estación). Otros datos, como las variables de aplicación, se tratarán por separado para cada aplicación y tendrán "null" como valor para los registros de finalización de todas las demás aplicaciones.
Si está creando un análisis para máquinas, puede seleccionar uno o varios tipos de máquinas. Si desea crear un análisis para una máquina específica, añada un filtro adicional.
Agrupaciones y operaciones
Las agrupaciones y operaciones son las áreas centrales de la construcción de su consulta. Aquí es donde usted define cuáles de sus opciones de datos desea mostrar y en qué forma.
Agrupaciones
Las agrupaciones dan una instrucción para combinar los grupos tanto como sea posible. Si está familiarizado con la función GROUP BY de las herramientas habituales de QL y BI, el proceso de agrupación se comporta de forma casi idéntica. Las agrupaciones determinan los campos y tipos de datos para encontrar valores similares. Le permiten obtener una visión cada vez más granular de los datos que desea ver.
Las agrupaciones dan más control para definir qué filas deben combinarse. Una agrupación puede ser cualquier campo de cualquier tipo. Dependiendo de las operaciones que haya configurado, la adición de una o varias agrupaciones dará lugar a resultados diferentes.
Veamos algunas combinaciones de agrupaciones.
| | Una Agrupación | Múltiples Agrupaciones | | --- | --- | --- | | Sólo valores distintos | Una fila por cada fila de los datos de origen que muestre los valores del campo de agrupación y los valores distintos de esa fila | Una fila por cada fila de los datos de origen que muestre los valores de los campos de agrupación y los valores distintos de esa fila | | Sólo agregaciones | Una fila por cada entrada distinta del campo de agrupación con ese valor para la agrupación y los valores agregados de todas las filas de los datos de origen con ese Una fila por cada combinación de entradas distintas de los campos de agrupación con los respectivos valores de las agrupaciones y los valores agregados de todas las filas de los datos fuente con los respectivos valores de agrupación | Valores distintos y agregaciones | Una fila por cada fila de los datos fuente que muestre los valores de las agrupaciones y los valores distintos y los valores agregados de todas las filas de los datos fuente con ese valor de agrupación (es decir, los valores agregados son los valores de todas las filas de los datos fuente con ese valor de agrupación).es decir, los valores agregados son los mismos en todas las filas con el mismo valor de agrupación) | Una fila por cada fila de los datos de origen que muestre los valores de las agrupaciones y los valores agregados de todas las filas de los datos de origen con los respectivos valores de agrupación (es decir, los valores agregados son los mismos en todas las filas con los mismos valores de agrupación).
Es importante tener en cuenta que los datos sólo se mostrarán si existe una fila con información relevante. Si no hay datos en los datos de origen para un día concreto, el análisis aparecerá en blanco.
Veamos un ejemplo de cómo funcionan las agrupaciones: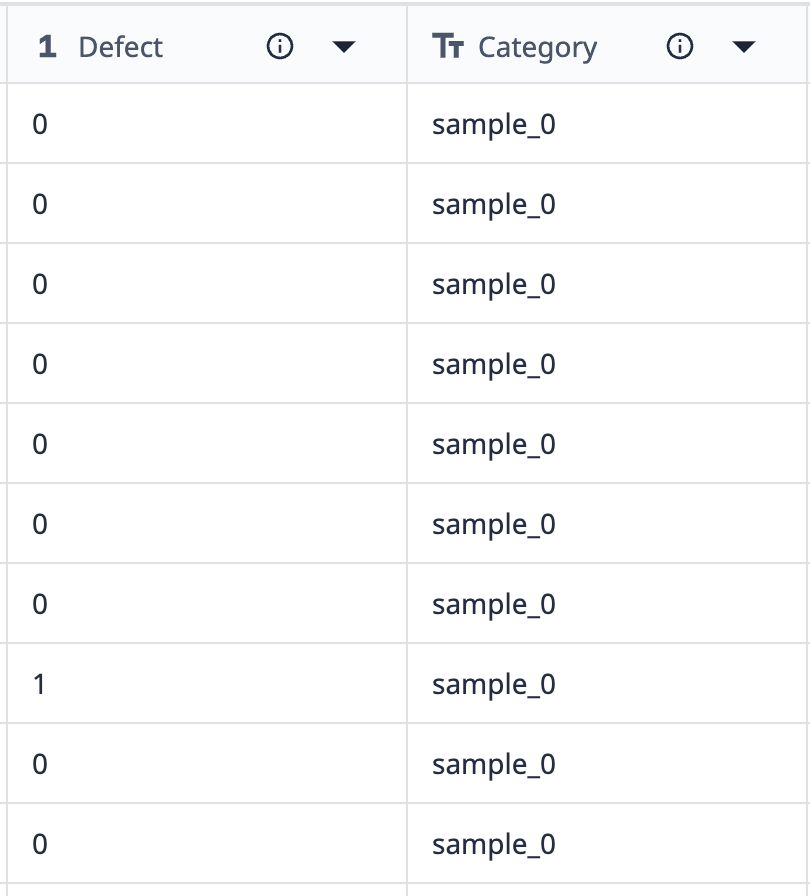
Los datos de esta tabla muestran que hay 10 registros etiquetados como "muestra_0". Si queremos agrupar estos datos en una visualización que sólo muestre los diferentes puntos de muestra_0 en los que el recuento de defectos difiere, podemos utilizar agrupaciones para combinar conjuntos de datos similares.
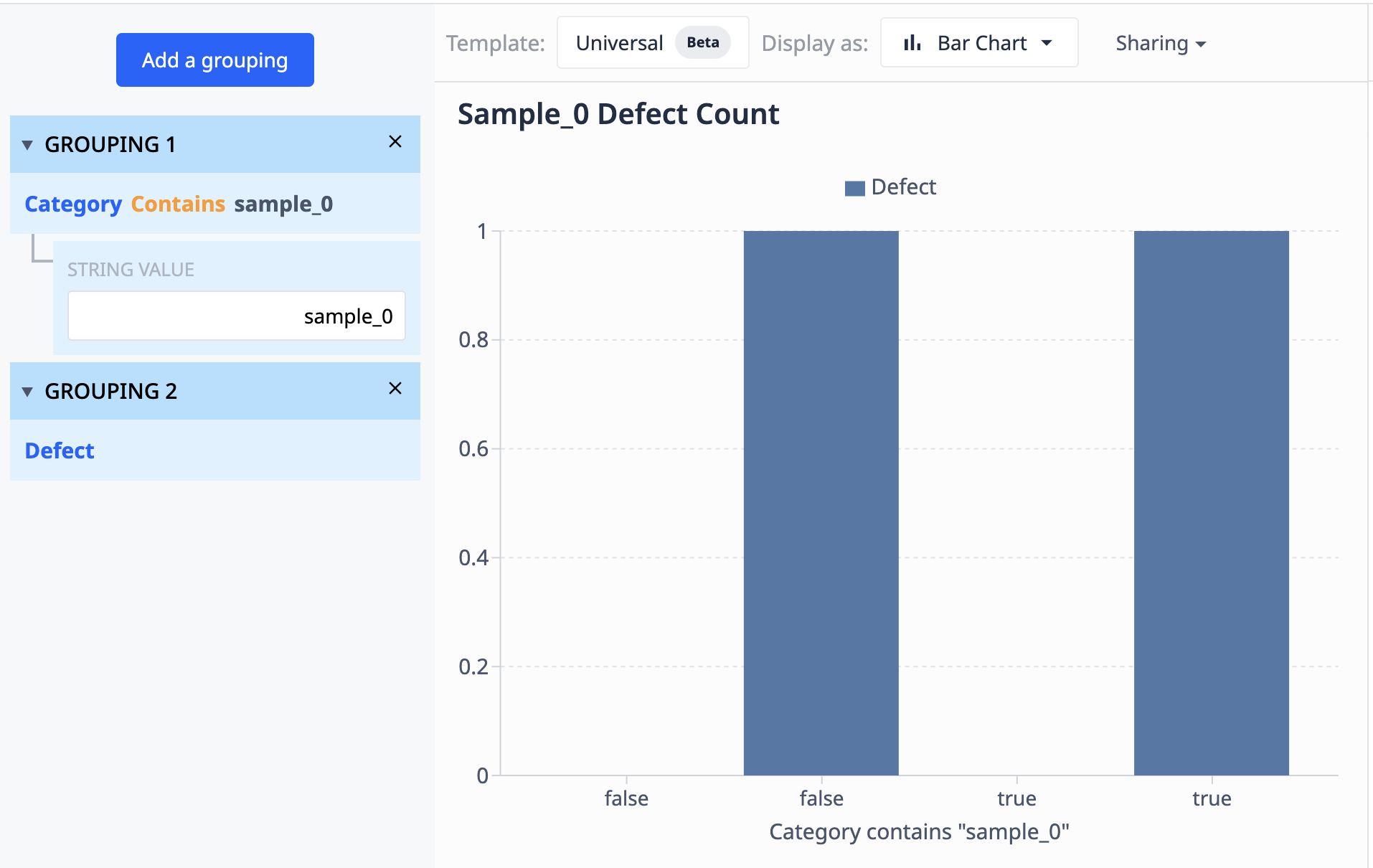
Operaciones
Las operaciones pueden ser una agregación que combina varios registros o un campo, que no lo hace.
Las operaciones se dividen en dos categorías generales Valores distintos Los valores distintos representan puntos de datos individuales de los datos de origen. En el caso más sencillo, se trata de un valor de una variable de un registro de finalización, un campo de una tabla o un atributo de una máquina.
Pero también puede tratarse de un punto de datos más avanzado, como la suma de dos campos del mismo registro, una combinación de varias cadenas o una expresión que no incluya una función de agregación.
Utilizando una tabla que contenga un campo de valores (numéricos) y un campo de marcas de tiempo (datetime), podemos visualizar los valores por marca de tiempo para que aparezcan como tales:
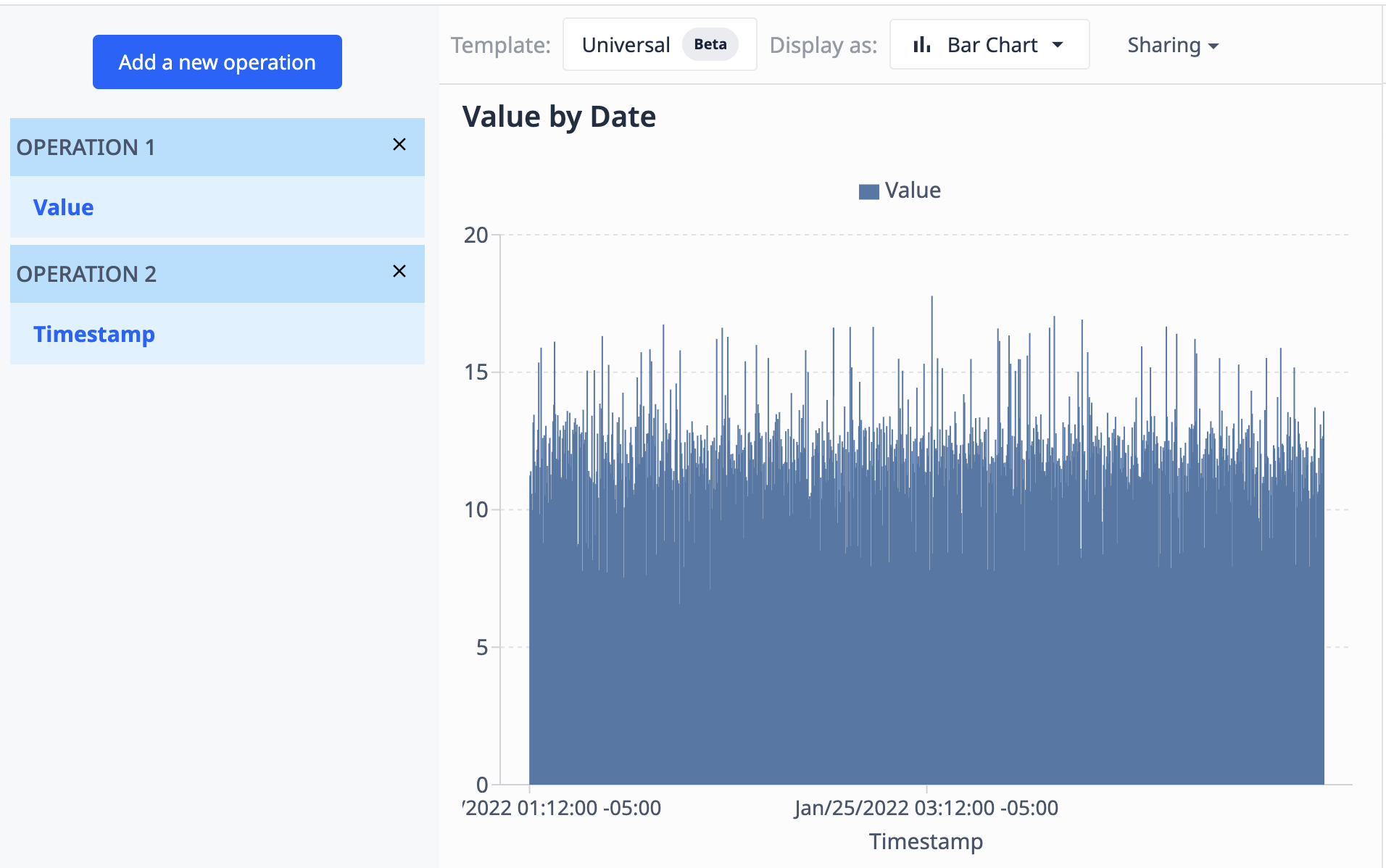
- Agregaciones
Las agregaciones son funciones que toman datos de varias filas y los combinan basándose en una lógica de conjunto. Hay un conjunto de funciones de agregación disponibles como selecciones preconfiguradas, o también puede utilizar funciones de agregación dentro del editor de expresiones para construir sus propias agregaciones avanzadas. Diferentes funciones de agregación funcionan para diferentes tipos de datos. Vea a continuación qué funciones están disponibles y qué tipos de datos admiten.
Funciones de agregacióndirectamente accesiblesPermiten combinar filas:
- Media
- Mediana
- Suma
- Mínimo
- Máximo
- Moda
- Desviación típica
- Percentil 95
- 5º percentil
- Ratio
- Ratio Complemento
Funciones de agregación disponibles en el editor de expresiones
Las funciones de agregación en el editor de expresiones pueden proporcionar datos más granulares basados en sus requisitos específicos. Para obtener una guía completa de todas las expresiones disponibles que puede utilizar en sus análisis, consulte Lista completa de expresiones en el editor de análisis.
Límite y ordenación
Puede definir el número máximo de filas que contiene el resultado de la consulta añadiendo un límite. Con los límites, puede centrarse en datos específicos o limitar la cantidad de datos mostrados en un gráfico. Por ejemplo, puede añadir un límite para mostrar las tres líneas de producción que han tenido más defectos en el último mes.
Los datos de clasificación definen qué filas se incluyen al evaluar el límite. Puede añadir una ordenación ascendente o descendente para cualquier campo que forme parte del resultado de la consulta. Si añade varios campos para la ordenación, los datos se ordenarán primero por el primero. Los grupos resultantes para cada valor del primer campo se ordenarán después por el segundo, etc.
Tenga en cuenta que si no define la ordenación explícitamente, la ordenación del resultado de la consulta puede variar en función de los datos disponibles. Cuando se utilizan límites o gráficos con ejes ordinales, esto puede dar lugar a visualizaciones variables. Recomendamos añadir una ordenación adecuada en esos casos.
El siguiente ejemplo utiliza el gráfico que vimos utilizando Operaciones. Aquí, limitamos los resultados a 100 puntos de datos y los ordenamos en orden descendente en función de su fecha y hora.
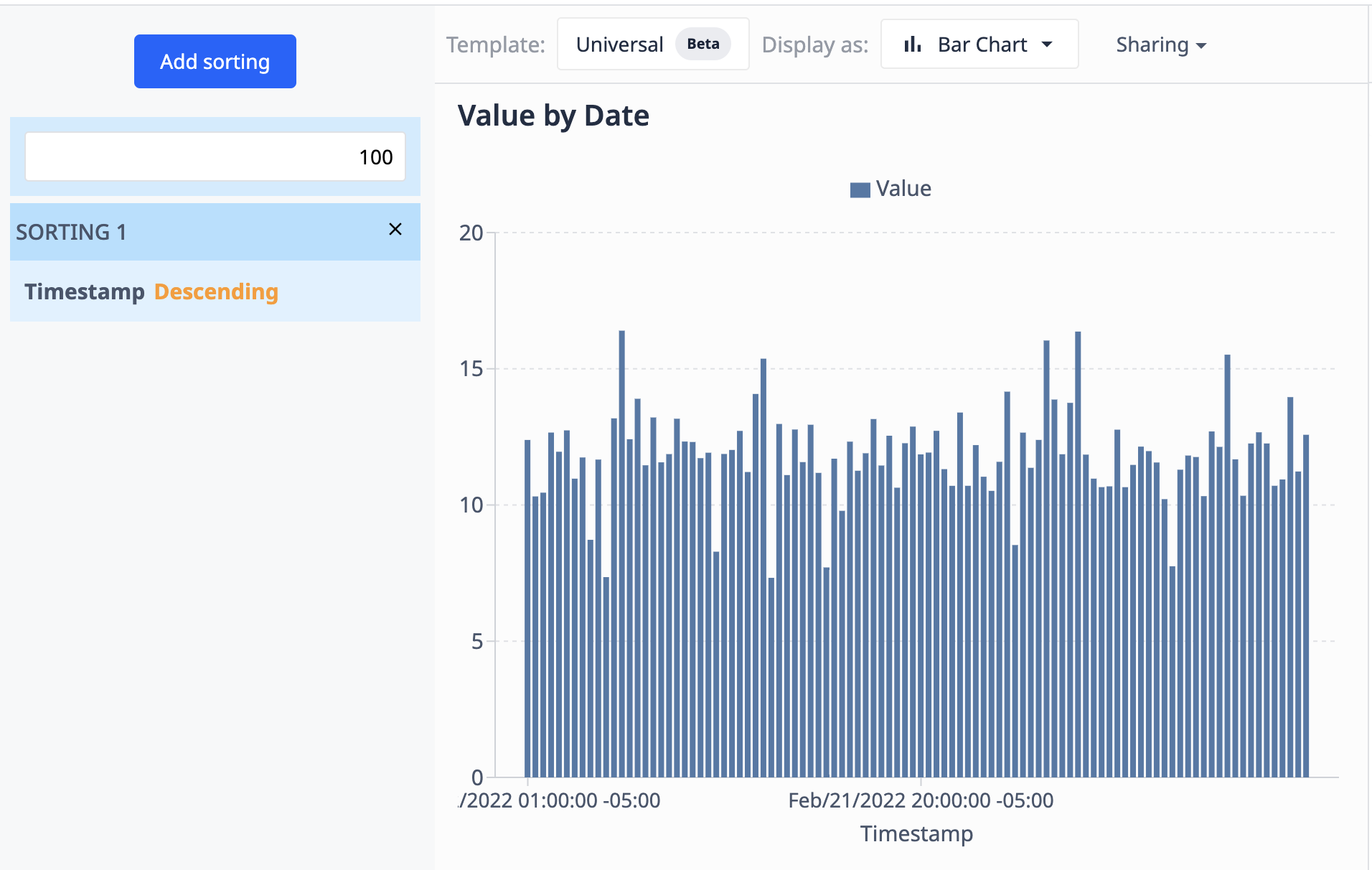
Como la fuente de datos (la tabla) se actualiza con nuevos registros, la visualización sólo mostrará los 100 más recientes.
Intervalo de fechas
El intervalo de fechas define qué datos se incluyen en la evaluación del análisis. Piense en esto como un filtro para un valor de fecha-hora en el conjunto de datos. El intervalo de fechas restringe el análisis a los datos que son relevantes para un periodo de tiempo especificado. Por razones de rendimiento, recomendamos utilizar el intervalo de fechas más corto posible para su caso de uso en lugar de añadir filtros adicionales más adelante para acotar el tiempo.
Se utilizan los siguientes valores de fecha y hora para el intervalo de fechas de las distintas fuentes de datos: * Datos de finalización de la aplicación * "Hora de inicio" de la finalización de la aplicación * Fecha de la tabla, seleccionable por el usuario * Fecha de creación * Fecha de actualización * Datos de la máquina * Hora de inicio de la entrada de actividad de la máquina
Filtros
Los filtros definen qué datos incluir en el resultado de la consulta. Los casos de uso típicos incluyen: * Mostrar datos sólo para una línea de producción específica * Excluir una máquina específica de un análisis * Mostrar sólo puntos de datos con un valor superior a un umbral específico.
Los filtros se configuran como una condición. Todos los datos que cumplen la condición se incluyen en el análisis. Veamos algunos ejemplos:
- Línea de producción igual a A
- Incluirá todos los registros que tengan "A" en el campo "Línea de producción
- El ID de la máquina no es igual a "Máquina 1
- Incluirá todas las máquinas que no sean iguales a "Máquina 1".
- Duración de la prueba > 55
- Incluirá todos los registros en los que la prueba haya durado más de 55 segundos.
Los filtros pueden definirse de dos formas distintas 1. Utilizando las funciones de filtro preconfiguradas en combinación con un campo de los datos de origen. 2. Configurando una expresión que se evalúe como un booleano.
Visualizaciones
Cuando se crea un nuevo análisis utilizando la Plantilla Universal, se selecciona por defecto la visualización Tabla. En cualquier momento se puede cambiar a otro tipo de visualización utilizando el ajuste Visualizar como en la parte superior de la pantalla. Las opciones además de "Tabla" son:
- Barra
- Línea
- Dispersión
- Histograma
- Donut
- Indicador
- Caja
- Valor único
- Presentación de diapositivas
- Pareto
Configuración de una visualización
Para la mayoría de los tipos de visualización puede seleccionar libremente qué campos del resultado de su consulta desea visualizar y de qué manera. Esto se hace en el panel Datos situado a la derecha del Editor de análisis. Cuando se cambia a una visualización diferente por primera vez, la configuración está vacía. Puede configurar su visualización manualmente en el panel Datos o comenzar con una sugerencia haciendo clic en el botón Comenzar con sugerencia en el centro de la pantalla.
Los requisitos previos para poder configurar una visualización son:
- Hay datos en el resultado de su consulta
- Dispone de los campos adecuados para la visualización. Por ejemplo, un gráfico de barras requiere al menos un campo numérico
Si no se cumplen estos dos requisitos, el Editor de análisis mostrará un mensaje de advertencia.
Opciones del panel de datos
La siguiente lista ofrece una visión general de las opciones de configuración para los distintos tipos de visualización:
Barra, Línea, Dispersión
- Eje X
- El campo cuyos valores deben mostrarse en el Eje X
- Eje Y
- Uno o varios campos numéricos cuyos valores deben mostrarse en el eje Y.
- Comparar por
- El campo utilizado para mostrar valores de la misma serie en el gráfico
Si desea mostrar varias series, puede hacerlo seleccionando varios campos para el Eje Y o un campo para el Eje Y y un campo para Comparar por. No es posible combinar varios campos para el Eje Y y Comparar por.
El modo "Comparar valores de campo" está disponible para estos tipos de visualización en el menú "..." de la configuración del Eje X. Esto permite visualizar valores numéricos de múltiples campos uno al lado del otro. Cuando la opción está activada, están disponibles las siguientes opciones:
- Eje X
- Los campos numéricos a comparar
- Comparar por
- El campo utilizado para mostrar los valores como la misma serie en el gráfico
- Por defecto el índice de fila de los datos
Histograma
- Valores
- Campo numérico que contiene los valores para los que se muestra el histograma
- Este campo debe contener todos los valores de forma no agregada. La visualización se encarga de calcular los valores del histograma.
- Comparar por
- El campo utilizado para dividir los "Valores" en múltiples series, cada una mostrada como un histograma separado en la visualización
Donut
- Valores
- Los campos numéricos que contienen los valores a visualizar
- Etiquetas
- El campo utilizado para las etiquetas de los diferentes segmentos del donut. Aparecerán en la descripción emergente y en la leyenda.
- Por defecto es el índice de fila de los datos visualizados
Valor único, Indicador
- Valor
- Los campos numéricos que contienen el valor a visualizar
Nota: Se visualizará el valor de la primera fila del resultado de la consulta. Si su consulta devuelve varias filas, puede añadir una ordenación para cambiar de qué valor se trata. Le recomendamos que utilice el botón "Mostrar resultado de la consulta" de la parte inferior para comprobar los datos si no ve el valor esperado en la visualización.
Cuadro
- Eje X
- El campo cuyos valores deben mostrarse en el Eje X.
- Se visualizará una "caja" separada para cada valor de este campo
- Eje Y
- Se muestra el campo numérico que contiene los valores que se visualizarán en el gráfico de caja
- Este campo debe contener todos los valores de forma no agregada. La visualización se encarga de calcular los valores de la caja.
Pareto
- Eje X
- El campo cuyos valores deben mostrarse en el Eje X
- Eje Y
- El campo numérico cuyos valores deben mostrarse en el Eje Y.
La línea de porcentaje acumulado se calcula automáticamente en la visualización.
Cambio entre tipos de visualización
Cuando se cambia entre cualquiera de los tipos de visualización configurados en el panel de datos, se mantiene cualquier configuración compatible. Esto minimiza el esfuerzo para cambiar y le permite probar fácilmente diferentes opciones de visualización para sus datos.
Tabla y Presentación
Las visualizaciones Tabla y Pase de diapositivas no tienen panel de datos y se configuran automáticamente.
La Tabla muestra todas las agrupaciones y operaciones configuradas en la consulta. Están ordenadas en la secuencia en que aparecen en el constructor de consultas de la izquierda.
La Presentación de diapositivas muestra todas las imágenes que se encuentran en cualquier campo de imagen del resultado de la consulta como diapositivas individuales. Cualquier campo adicional configurado en la consulta se muestra en una tabla debajo de la imagen.
¿Ha encontrado lo que buscaba?
También puedes dirigirte a community.tulip.co para publicar tu pregunta o ver si otras personas se han enfrentado a una pregunta similar.