
This feature is only available on "Enterprise" plans and above.
Diagramme d'exportation et d'importation
Vous trouverez ci-dessous l'ensemble du flux de transfert pour les tables, les requêtes et les agrégations de Tulip. Ce document fournira une explication détaillée de ce flux.
Champs d'utilisateur personnalisés et tables d'activité des machines
Le flux décrit ci-dessous s'applique également à l'exportation et à l'importation des tables de champs d'utilisateurs personnalisés et des tables de champs d'activité de la machine.
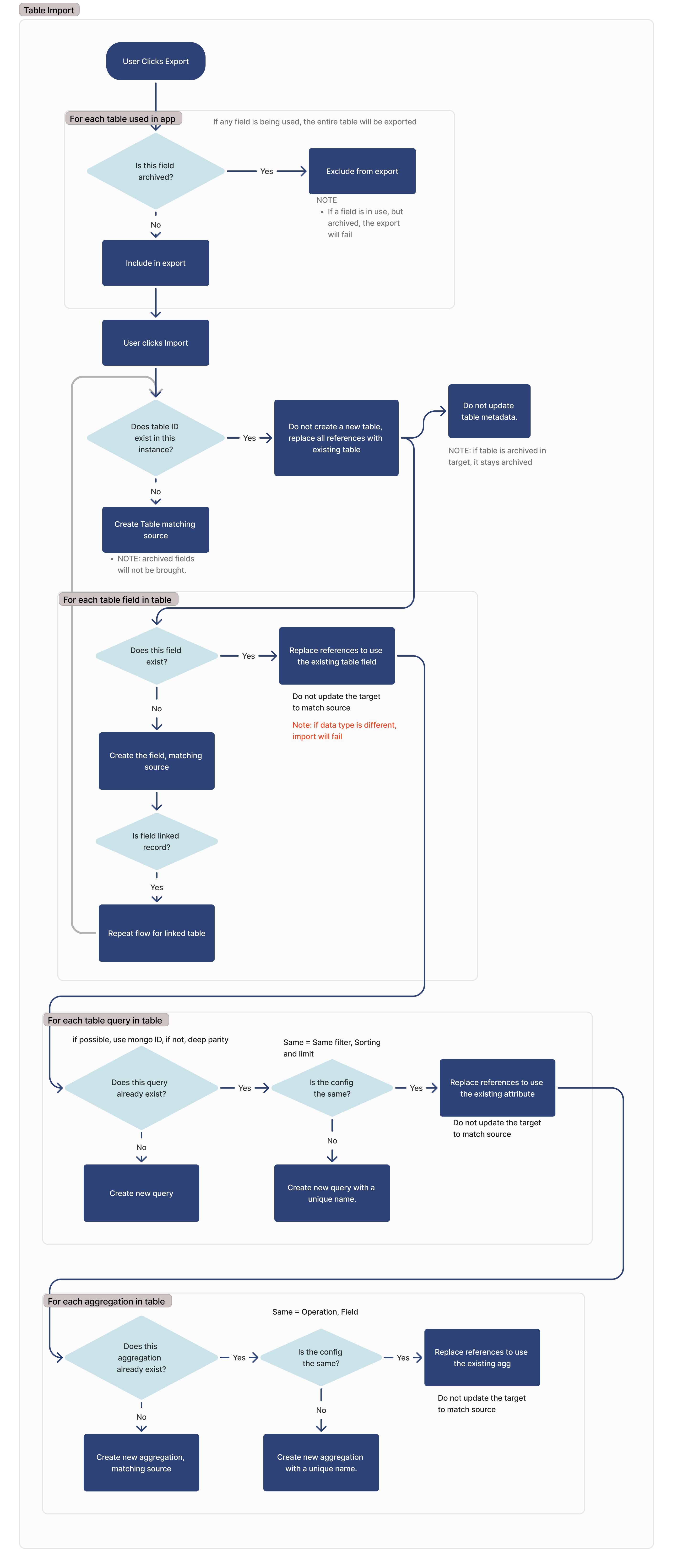
Exportation
Au cours du processus d'exportation, l'application ou l'automatisation exportée signale toutes les tables utilisées dans cette application. Une table est considérée comme utilisée si l'une des conditions suivantes est remplie :
- affichée dans un widget "Enregistrement de tableau
- Utilisé dans un widget de saisie
- affiché dans un tableau interactif
- Utilisé dans un déclencheur
- Utilisé dans une action d'automatisation
- Utilisé dans un bloc d'événement d'automatisation
- Utilisé dans un filtre pour une requête de tableau, un tableau interactif ou un widget d'analyse
- Utilisé comme entrée ou sortie d'un widget personnalisé
Si un champ est archivé, il ne sera pas exporté. Si un champ est archivé mais en cours d'utilisation, l'exportation échouera.
Importer
Archived table fields will not be exported, and any references to those fields within applications will need to be remapped on import.
Recherche d'une table identique
Pour identifier les tables correspondantes lors de l'importation, nous recherchons les identifiants correspondants. Si une table avec le même identifiant est trouvée, nous ne créons pas de nouvelle table et nous nous appuyons sur la table existante.
Si la table du site d'importation est archivée, elle le restera.
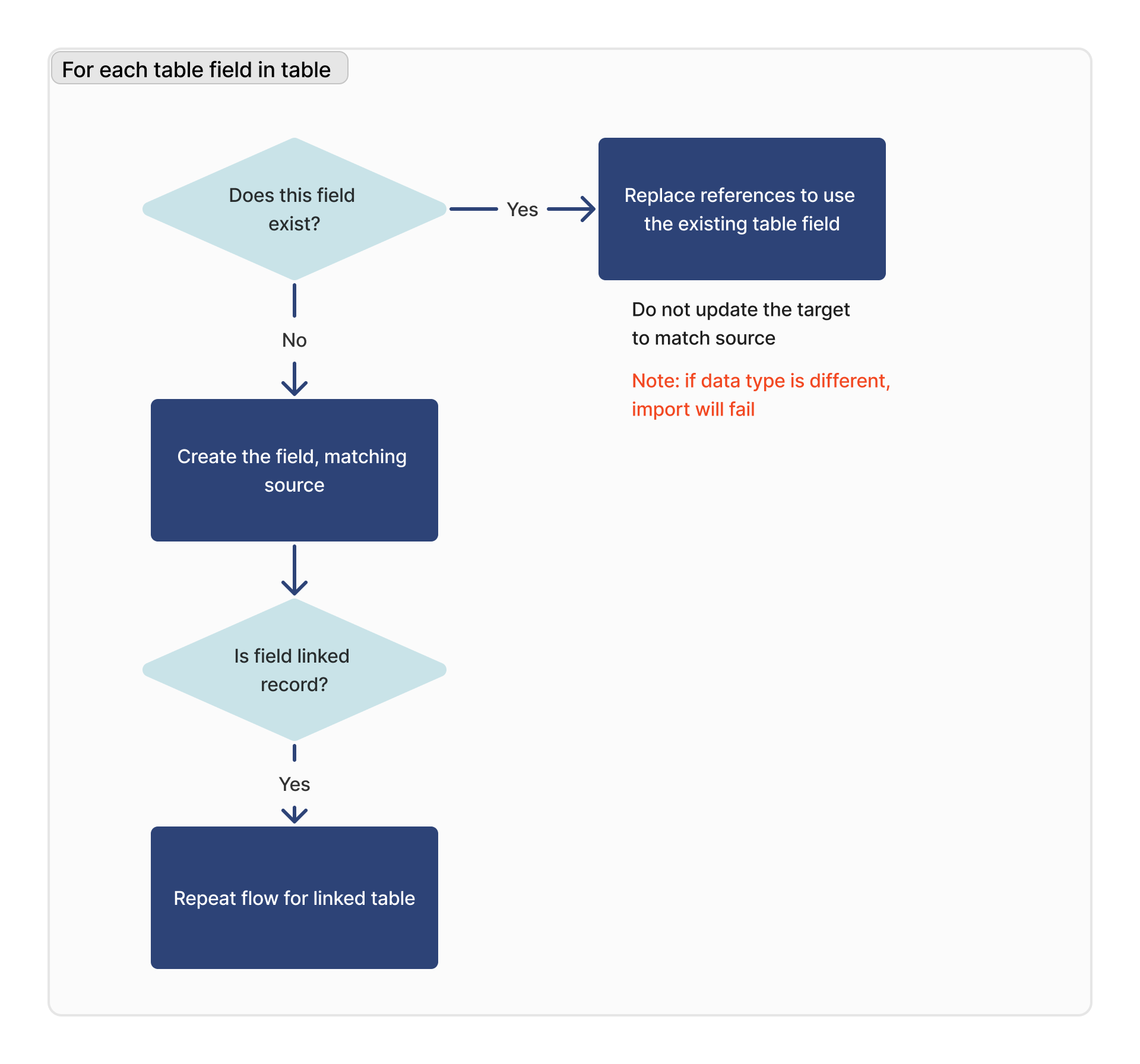
Pour chaque champ de table
Pour chaque champ de table, nous recherchons un champ correspondant sur la base de l'ID de colonne de ce champ.
Si le type de données du champ correspondant est différent, l'importation échoue.
Si le champ est un champ d'enregistrement lié, la table liée sera ajoutée à la liste des dépendances pour l'importation, et ce flux sera répété pour cette table.
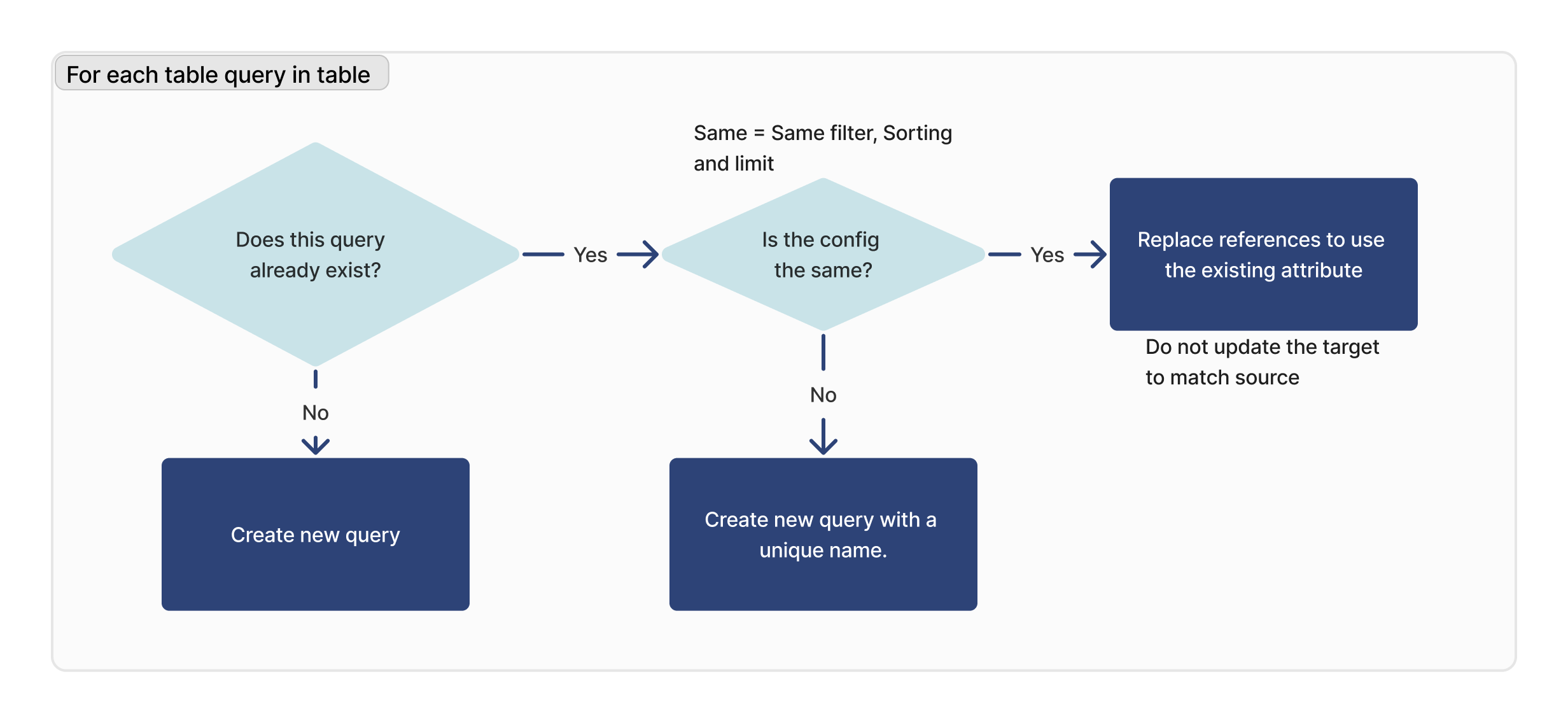
Pour chaque requête
Pour chaque requête de la table importée, nous vérifions si cette requête existe. Si un ID correspondant est trouvé, nous vérifions que la configuration est identique (limite, tri et filtrage) entre la cible et la source.
Si aucune requête correspondante n'est trouvée, une nouvelle requête est créée. Si une requête correspondante est trouvée, mais qu'elle n'est pas identique à l'instance cible, une nouvelle requête sera créée avec un nouveau nom.
Remarque : cela ne s'applique pas aux champs d'utilisateur personnalisés ni aux tables d'activité des machines.
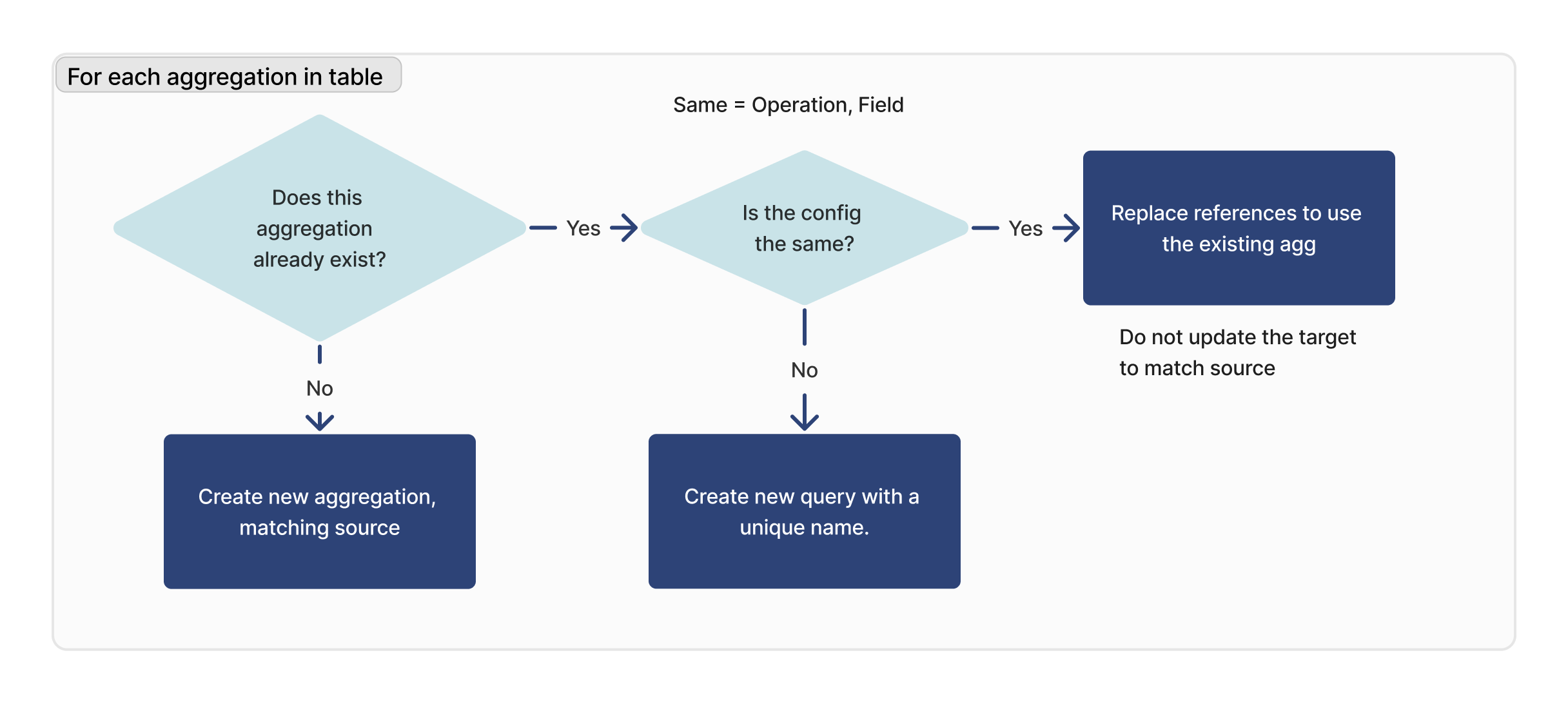
Pour chaque agrégation
Pour chaque agrégation dans la table importée, nous vérifions si cette requête existe. Si un ID correspondant est trouvé, nous vérifions que la configuration est identique (opération, champ) entre la cible et la source.
Si la requête correspondante est introuvable, une nouvelle requête est créée. Si une requête correspondante est trouvée, mais qu'elle n'est pas identique à l'instance cible, une nouvelle requête sera créée avec un nouveau nom.
Remarque : cela ne s'applique pas aux champs d'utilisateur personnalisés ni aux tables d'activité des machines.