

通用模板指南以及如何优化功能体验。
Universal Template 是无缝构建分析的单一体验。通过解耦数据查询和可视化,您可以在可视化类型之间进行切换。通用模板支持所有分析类型和 Tulip 数据源(完成度、表数据和机器数据)。

使用查询和可视化
查询就像你给系统下达的指令,详细说明你希望系统如何处理来自应用程序、机器或 Tulip 表的 "原始 "数据。查询结果是 Tulip Analytics 根据你的查询配置创建的数据表格。您可以在分析编辑器的左侧面板上配置查询。
您可以用不同的可视化方式将该查询的数据可视化,显示数据的全部或部分内容。可视化在分析编辑器顶部选择,并在分析编辑器右侧面板进一步配置。
除非选择了 "表格 "可视化,否则点击 "显示查询结果"可在可视化下方看到查询结果。
建立查询
数据源
数据源是分析的基础。您可以选择应用程序的完成数据、表数据或机器数据。
如果要为应用程序完成数据建立分析,可以选择多个应用程序。 这将使分析考虑所有选定应用程序的完成记录。
请注意,如果选择了多个应用程序,数据将不会被连接,但每个完成将被视为单独的一行。这意味着您可以联合分析完成的 "字段"(如用户、开始时间和站点)。其他数据(如应用程序变量)将针对每个应用程序单独处理,并以 "空 "作为所有其他应用程序完成记录的值。
如果要对机器进行分析,可以选择一种或多种机器类型。如果要对特定机器进行分析,请添加额外的过滤器。
分组和操作
分组和操作是建立查询的核心部分。在这里,您可以定义要以何种形式显示哪些数据选项。
分组
分组提供了一个指令,以便尽可能多地组合分组。如果你熟悉常用 QL 和 BI 工具中的 GROUP BY 功能,那么分组过程几乎是相同的。分组决定了查找相似值的数据字段和类型。通过分组,您可以获得想要查看的数据的越来越细的视图。
分组提供了更多控制,可以定义哪些行应该合并。分组可以是任何类型的任何字段。根据所配置的操作,添加一个或多个分组将导致不同的结果。
下面我们来看看几种分组组合。
| 一个分组 | 多个分组 | | --- | --- | ---只显示不同值 | 源数据中的每一行都有一行显示分组字段的值和该行的不同值 | 源数据中的每一行都有一行显示分组字段的值和该行的不同值 | 只显示聚合 | 分组字段中的每个不同条目都有一行显示该分组值,源数据中的所有行都有该分组值的聚合值 | 只显示聚合 | 源数据中的每一行都有一行显示该分组值,源数据中的所有行都有该分组值的聚合值 | 只显示聚合 | 源数据中的每一行都有一行显示该分组值。分组值 | 分组字段中每个不同条目的组合(包括各自的分组值)和源数据中所有具有各自 分组值的行的聚合值各一行 | 不同值和聚合 | 源数据中显示分组值和不同值的每一行和源数据中所有具有该分组值的行的聚合 值各一行(即聚合值是源数据中所有具有该分组值的行的聚合值)。例如,具有相同分组值的所有行的汇总值相同)源数据中的每一行都有一行显示分组值,以及源数据中具有相应分组值的所有行的聚合值(即具有相同分组值的所有行的聚合值相同) | 源数据中的每一行都有一行显示分组值,以及源数据中具有相应分组值的所有行的聚合值(即具有相同分组值的所有行的聚合值相同) | 源数据中的每一行都有一行显示分组值。
值得注意的是,只有存在包含相关信息的行时,数据才会显示出来。如果源数据中没有特定日期的数据,分析结果将显示为空白。
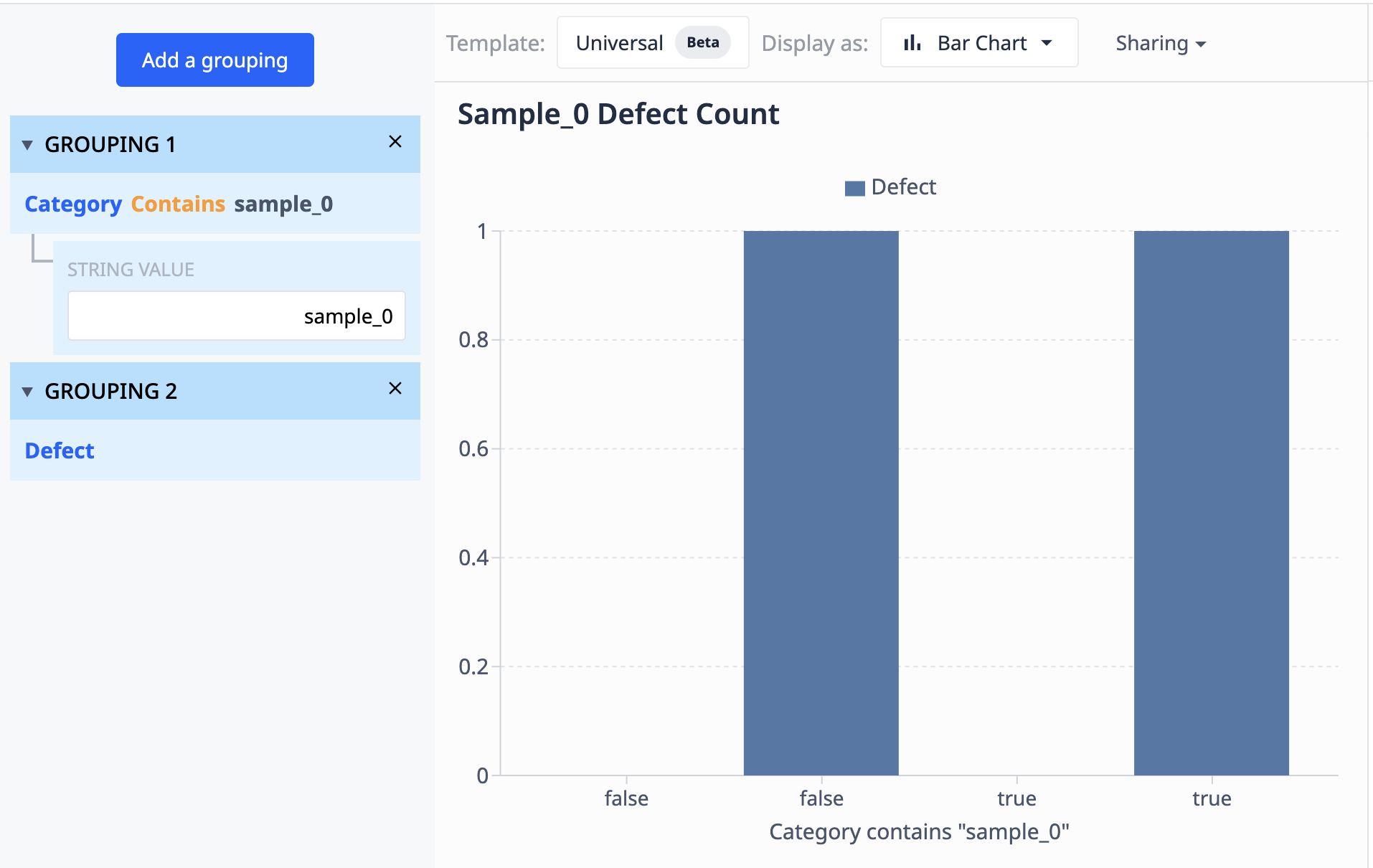
让我们来看一个分组工作原理的示例: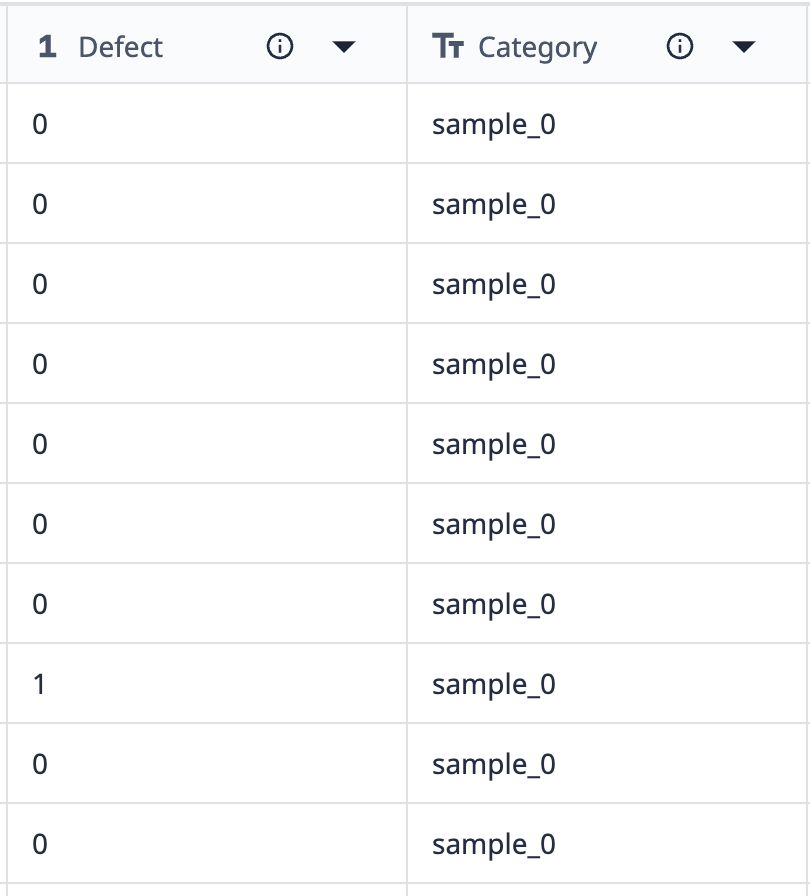
该表的数据显示有 10 条标有 "样本_0 "的记录。除了一个 sample_0 数据点之外,其他所有数据点都没有缺陷。 如果我们想将这些数据分组,使可视化效果只显示缺陷计数不同的不同 sample_0 点,就可以使用分组来组合类似的数据集。
操作
操作既可以是将多条记录合并在一起的聚合,也可以是不将多条记录合并在一起的字段。
操作一般分为两类: 1.不同值 不同值代表源数据中的单个数据点。最简单的情况是完成记录中变量的一个值、表中的一个字段或机器属性。
但这也可以是更高级的数据点,如同一记录中两个字段的总和、多个字符串的组合或不包含聚合函数的表达式。
使用包含一个数值字段(数字)和一个时间戳字段(日期)的表格,我们可以按时间戳将数值可视化为这样的结果:
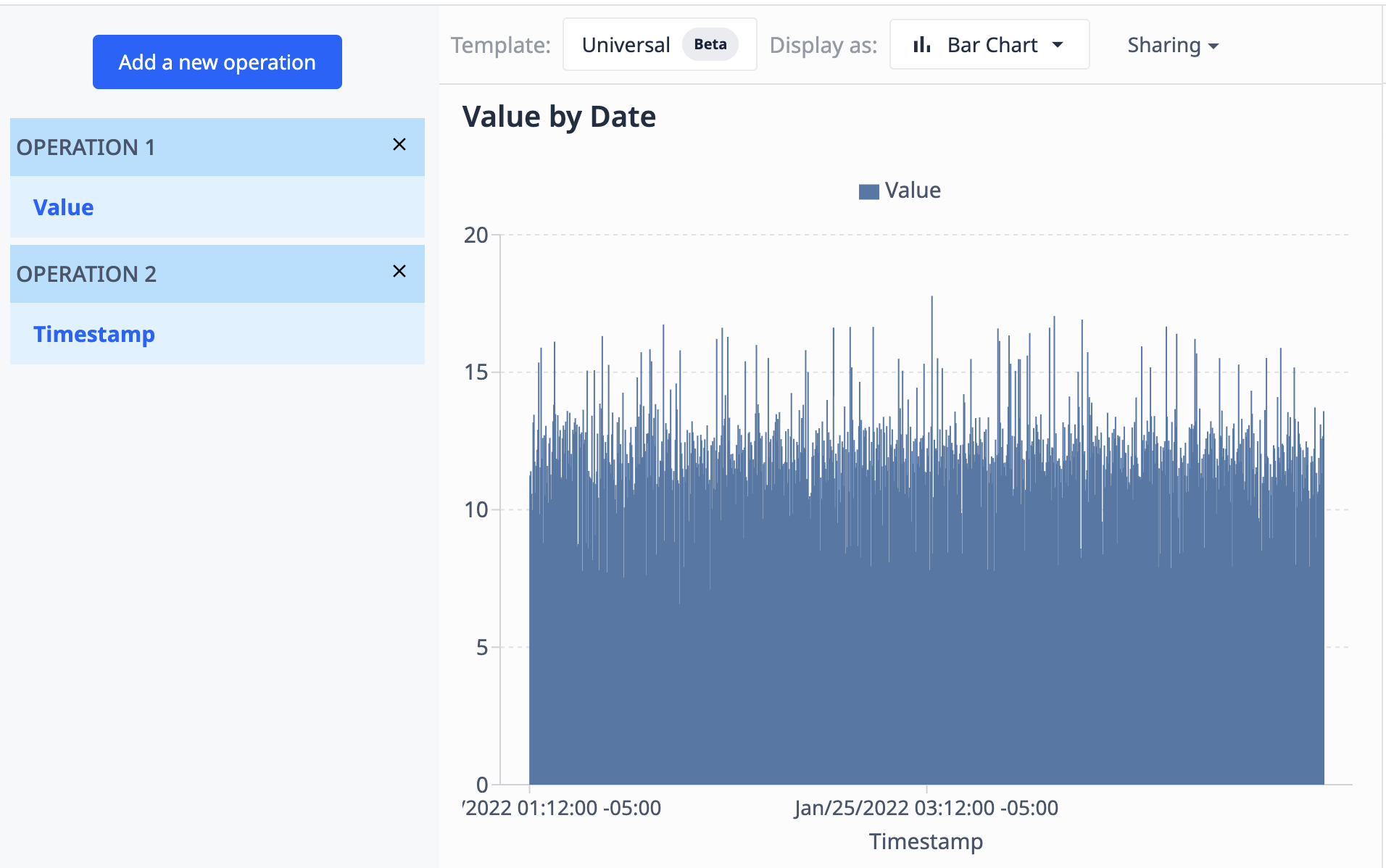
- 聚合
聚合是一种从多行中提取数据并根据设定逻辑将其组合的函数。有一组聚合函数可作为预配置选择使用,你也可以在表达式编辑器中使用聚合函数来创建自己的高级聚合。不同的聚合函数适用于不同的数据类型。请参阅下面的可用函数及其支持的数据类型。
可直接访问的聚合函数这些函数允许合并行:
- 平均值
- 中位数
- 总和
- 最小值
- 最大值
- 模式
- 标准偏差
- 第 95 百分位数
- 第 5 百分位数
- 比率
- 比率 补充
表达式编辑器中可用的聚合函数
表达式编辑器中的聚合函数可以根据您的具体要求提供更细粒度的数据。有关您可以在分析中使用的所有可用表达式的完整指南,请参阅分析编辑器中的表达式完整列表。
限制和排序
您可以通过添加限制来定义查询结果包含的最大行数。通过限制,您可以关注特定数据或限制图表中显示的数据量。例如,您可以添加限制来显示上个月缺陷最多的三条生产线。
排序数据定义了评估限制时包括哪些行。您可以为查询结果中的任何字段添加升序或降序排序。如果添加了多个排序字段,数据将先按第一个字段排序。第一个字段的每个值所产生的组将按第二个等排序。
请注意,如果您没有明确定义排序,查询结果的排序可能会根据可用数据而有所不同。在使用带序数轴的限制或图表时,这可能会导致不同的可视化效果。在这种情况下,我们建议添加适当的排序。
下面的示例使用了我们使用运算看到的图表。在这里,我们将结果限制为 100 个数据点,并根据日期时间以降序排序。
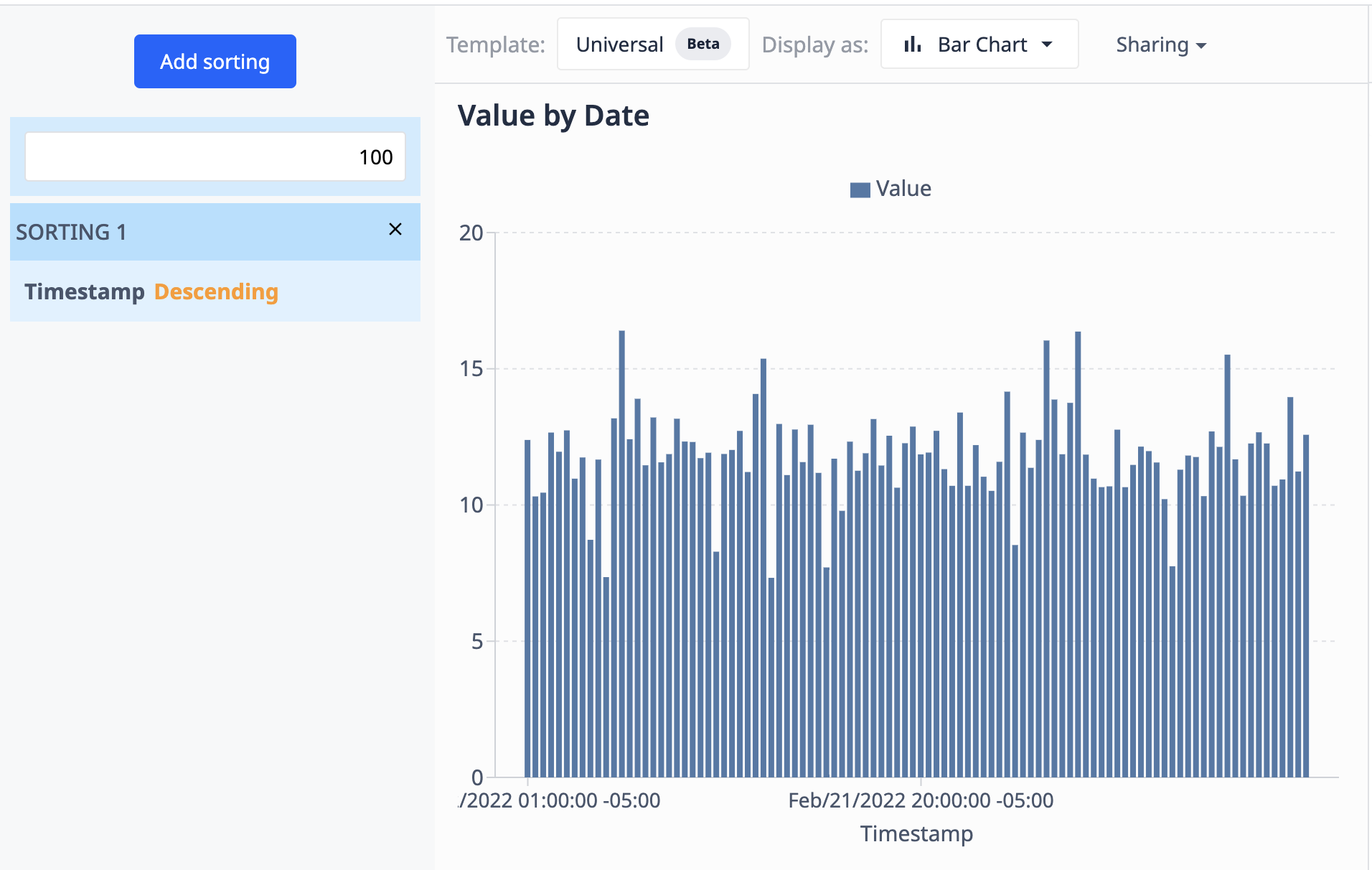
当数据源(表)更新新记录时,可视化将只显示最近的 100 条记录。
日期范围
日期范围定义了哪些数据包含在分析评估中。可以把它想象成数据集中日期时间值的过滤器。日期范围将分析限制在指定时间段内的相关数据。 出于性能方面的考虑,我们建议您尽可能使用最短的日期范围,而不是稍后添加额外的筛选器来缩小时间范围。
以下日期时间值用于各种数据源的日期范围: * 应用程序完成数据 * 应用程序完成的 "开始时间" * 表日期,用户可选 * 创建日期 * 更新日期 * 机器数据 * 机器活动条目的开始时间
过滤器
过滤器定义查询结果中包含哪些数据,典型用例包括: * 仅显示特定生产线的数据 * 从分析中排除特定机器 * 仅显示值高于特定阈值的数据点
过滤器的配置类似于条件。所有满足条件的数据都会包含在分析中。我们来看几个例子:
- 生产线等于 A
- 将包括 "生产线 "字段中有 "A "的所有记录
- 机器 ID 不等于 "机器 1
- 将包括不等于 "机器 1 "的所有机器
- 测试时间 > 55
- 包括测试时间超过 55 秒的所有记录
可通过两种不同方式定义过滤器: 1.结合源数据中的字段使用预配置的过滤器函数 2.配置求值为布尔值的表达式。
可视化
使用通用模板创建新分析时,默认选择的是表格可视化。您可以使用屏幕顶部的 "显示为"设置随时切换到不同的可视化类型。除 "表格 "外,还有以下选项
- 条形图
- 线形
- 散点图
- 柱状图
- 甜甜圈
- 仪表
- 方框
- 单值
- 幻灯片
- 帕累托
配置可视化
对于大多数可视化类型,您可以自由选择要以何种方式可视化查询结果中的哪些字段。这可以在分析编辑器右侧的数据面板中完成。首次切换到不同的可视化时,配置是空的。您可以在数据面板中手动设置可视化,也可以点击屏幕中央的 "从建议开始"按钮从建议开始。
配置可视化的前提条件是
- 查询结果中有数据
- 可视化有正确的可用字段。例如,条形图至少需要一个数字字段
如果这两个条件都不满足,分析编辑器将显示一条警告信息。
数据面板选项
以下列表概述了不同可视化类型的配置选项:
条形图、折线图、散点图
- X 轴
- 其值应显示在 X 轴上的字段
- Y 轴
- 数值应显示在 Y 轴上的一个或多个数字字段。
- 比较方式
- 用于在图表中显示同一系列值的字段
如果要显示多个序列,可以为 Y 轴选择多个字段,或者为 Y 轴选择一个字段,再为比较对象选择一个字段。无法将 Y 轴和比较对象的多个字段组合在一起。
在 X 轴设置的"... "菜单中,可为这些可视化类型提供 "比较字段值 "模式。这样就可以并排显示多个字段的数值。打开该选项后,可使用以下选项:
- X 轴
- 要比较的数值字段
- 比较对象
- 用于在图表中显示同一系列数值的字段
- 默认为数据的行索引
直方图
- 值
- 数字字段,包含显示直方图的值
- 该字段应包含未汇总的所有值。可视化程序会计算直方图值。
- 比较对象
- 用于将 "数值 "拆分为多个系列的字段,每个系列在可视化中显示为单独的直方图
甜甜圈
- 数值
- 包含要可视化的数值的数字字段
- 标签
- 用于标注不同甜甜圈片段的字段。这些标签将显示在工具提示和图例中
- 默认为可视化数据的行索引
单值,仪表
- 数值
- 包含要可视化的值的数值字段
注意:查询结果中第一行的值将被可视化。如果查询结果返回多行,则可以添加排序来更改排序值。如果在可视化中看不到预期值,建议使用底部的 "显示查询结果 "按钮检查数据。
方框
- X 轴
- 其值应显示在 X 轴上的字段
- 该字段中的每个值都将显示一个单独的 "方框"。
- Y 轴
- 显示包含要在方框图中可视化的数值的数字字段
- 该字段应包含未汇总的所有数值。可视化将负责计算方框值。
帕累托
- X 轴
- 数值应显示在 X 轴上的字段
- Y 轴
- 数值应显示在 Y 轴上的数值字段。
累计百分比线在可视化中自动计算。
在可视化类型之间切换
在数据面板中配置的任何可视化类型之间切换时,任何兼容的配置都会沿用。这样可以最大限度地减少切换的工作量,让您可以轻松尝试不同的数据可视化选项。
表格和幻灯片
表格和幻灯片可视化没有数据面板,是自动配置的。
表格显示查询中配置的所有分组和操作。它们按照在左侧查询生成器中出现的顺序排列。
幻灯片以单独幻灯片的形式显示查询结果中任何图像字段中的所有图像。查询中配置的任何其他字段都会显示在图片下方的表格中。
找到您想要的内容了吗?
你还可以前往community.tulip.co发布你的问题,或查看其他人是否也遇到过类似问题!
