

Útmutató az univerzális sablonhoz és a funkcióhasználat optimalizálásához.
A Universal Template egyetlen élményt nyújt az elemzések zökkenőmentes felépítéséhez. Lehetővé teszi a vizualizációs típusok közötti váltást az adatok lekérdezésének és vizualizációjának szétválasztásával. Az Univerzális sablon támogatja az összes elemzéstípust és Tulip adatforrást (Teljesítmények, táblázatos adatok és gépi adatok).

A lekérdezések és a vizualizációk használata
A lekérdezés olyan, mint egy utasítás, amelyet a rendszernek ad, részletezve, hogy mit szeretne, mit csináljon az alkalmazásból, gépből vagy egy Tulip-táblában lévő "nyers" adatokkal. A lekérdezés eredménye a Tulip Analytics által a lekérdezés konfigurálása alapján létrehozott adatok táblázatos megjelenítése. A lekérdezést az Analytics-szerkesztő bal oldali paneljén konfigurálja.
Az adott lekérdezésből származó adatokat különböző megjelenítésekkel vizualizálhatja, amelyek az összes adatot vagy csak kiválasztott részeket mutatják. A vizualizációt az Analytics-szerkesztő felső részén választja ki, és az Analytics-szerkesztő jobb oldali paneljén konfigurálja tovább.
A vizualizáció alatt mindig a lekérdezés eredménye látható, ha a lekérdezés eredményének megjelenítése gombra kattint, kivéve, ha a "táblázat" vizualizáció van kiválasztva.
A lekérdezés felépítése
Adatforrás
Az adatforrás az, amire az elemzés épül. Választhat az alkalmazás kitöltési adatai, a táblázat adatai vagy a gépi adatok közül.
Ha az alkalmazás kitöltési adataira épít elemzést, akkor több alkalmazást is kiválaszthat. Ezáltal az elemzés az összes kiválasztott alkalmazás befejezési rekordját figyelembe veszi.
Vegye figyelembe, hogy ha több Alkalmazás van kiválasztva, az adatok nem lesznek összekapcsolva, hanem minden egyes befejezést külön soronként kezel. Ez azt jelenti, hogy a kitöltések "mezőit" (pl. Felhasználó, kezdési idő és állomás) együttesen tudja elemezni. Az egyéb adatokat, például az Alkalmazás-változókat minden egyes Alkalmazás esetében külön kezeljük, és az összes többi alkalmazás befejezési rekordjainak értéke "null" lesz.
Ha gépekre vonatkozó elemzést készít, akkor egy vagy több géptípust is kiválaszthat. Ha egy adott gépre szeretne elemzést készíteni, adjon hozzá egy további szűrőt.
Csoportosítások és műveletek
A csoportosítások és a műveletek a lekérdezés felépítésének központi területei. Itt határozza meg, hogy az adatopciók közül melyiket és milyen formában szeretné megjeleníteni.
Csoportosítások
A csoportosítások utasítást adnak a csoportok lehető legnagyobb mértékű kombinálása érdekében. Ha ismeri a GROUP BY funkciót az általános QL és BI eszközökben, a csoportosítási folyamat szinte ugyanúgy viselkedik. A csoportosítások meghatározzák a hasonló értékek keresésére szolgáló mezőket és adattípusokat. Lehetővé teszik, hogy egyre részletesebb képet kapjon a látni kívánt adatokról.
A csoportosítások nagyobb kontrollt biztosítanak annak meghatározásához, hogy mely sorokat kell kombinálni. A csoportosítás bármilyen típusú mező lehet. Attól függően, hogy milyen műveleteket állított be, egy vagy több csoportosítás hozzáadása különböző eredményekhez vezet.
Nézzünk végig néhány csoportosítási kombinációt.
| | Egy csoportosítás | Több csoportosítás | | | --- | --- | --- | --- | --- --- | | Csak megkülönböztetett értékek | Egy sor a forrásadatok minden egyes sorához, amely a csoportosítási mező értékeit és az adott sor megkülönböztetett értékeit mutatja | Egy sor a forrásadatok minden egyes sorához, amely a csoportosítási mezők értékeit és az adott sor megkülönböztetett értékeit mutatja | | | Csak összesítés | Egy sor a csoportosítási mező minden egyes megkülönböztetett bejegyzéséhez, amely a csoportosításhoz tartozó értékkel rendelkezik, és a forrásadatok összes sorának összesített értékei az adott értékkel. csoportosítási érték | Egy sor a csoportosítási mezők minden egyes kombinációjához különálló bejegyzések a csoportosítások megfelelő értékeivel és a forrásadatok összes sorának összesített értékei a megfelelő csoportosítási értékekkel | | | Különálló értékek és aggregációk | Egy sor a forrásadatok minden egyes sorához, amely a csoportosítások értékeit és a különálló értékeket mutatja, valamint a forrásadatok összes sorának összesített értékei az adott csoportosítási értékkel (i. A csoportosítási mezőben a csoportosítási mezőben a csoportosítási mezőben a különálló értékek és az összes sor összesített értékei szerepelnek.azaz az összesített értékek azonosak az azonos csoportosítási értékkel rendelkező összes sorban). | A forrásadatok minden egyes sorához egy sor, amely megmutatja a csoportosítások értékeit és a forrásadatok összes sorának összesített értékeit a megfelelő csoportosítási értékekkel (azaz az összesített értékek azonosak az összes sorban, amelyekben ugyanazok a csoportosítási értékek vannak) | |
Fontos megjegyezni, hogy az adatok csak akkor jelennek meg, ha létezik olyan sor, amely releváns információt tartalmaz. Ha egy adott napra vonatkozóan nincsenek adatok a forrásadatokban, az elemzés üresen jelenik meg.
Nézzünk egy példát a csoportosítások működésére: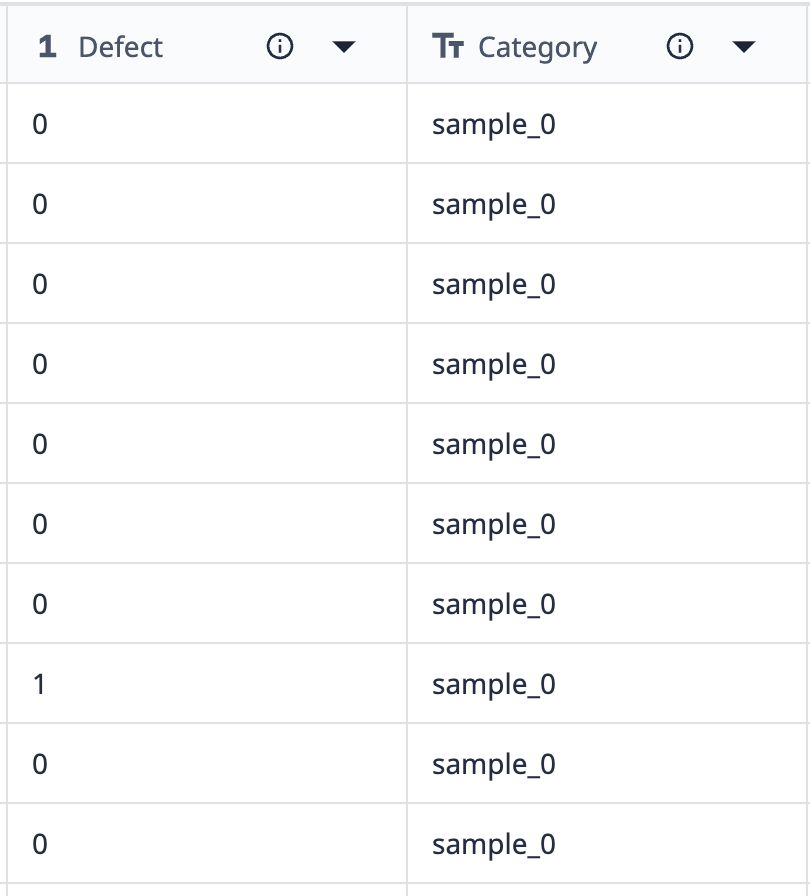
A táblázat adatai azt mutatják, hogy 10 "minta_0" feliratú rekord van. A minta_0 adatpontok közül egy kivételével mindegyikben nincs hiba. Ha ezeket az adatokat olyan vizualizációba szeretnénk csoportosítani, amely csak a különböző minta_0 pontokat mutatja, ahol a hibaszám eltér, akkor a csoportosítások segítségével egyesíthetjük a hasonló adathalmazokat.
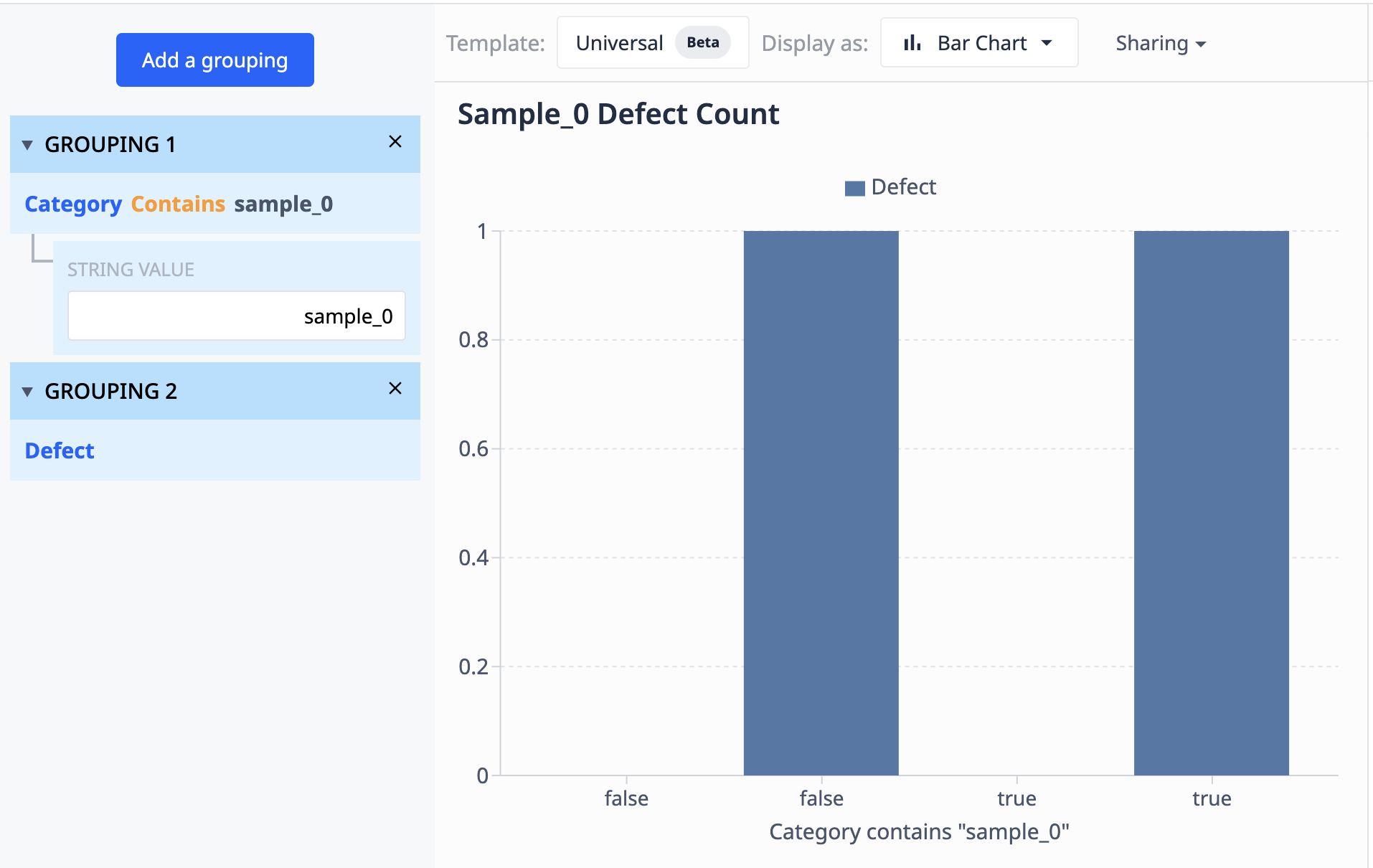
Műveletek
A műveletek lehetnek aggregációk, amelyek több rekordot egyesítenek, vagy mezők, amelyek nem.
A műveletek két általános kategóriába sorolhatók: 1. Különálló értékek A különálló értékek a forrásadatok egyes adatpontjait jelentik. A legegyszerűbb esetben ez egy változó egy értéke egy kitöltési rekordból, egy mező egy táblázatból vagy egy gépi attribútumból.
De ez lehet egy fejlettebb adatpont is, mint például két mező összege ugyanabból a rekordból, több karakterlánc kombinációja vagy egy olyan kifejezés, amely nem tartalmaz aggregációs függvényt.
Egy olyan táblázat segítségével, amely egy értékeket tartalmazó mezőt (numerikus) és egy időbélyegeket tartalmazó mezőt (dátumidő) tartalmaz, megjeleníthetjük az értékeket időbélyegek szerint, hogy azok így jelenjenek meg:
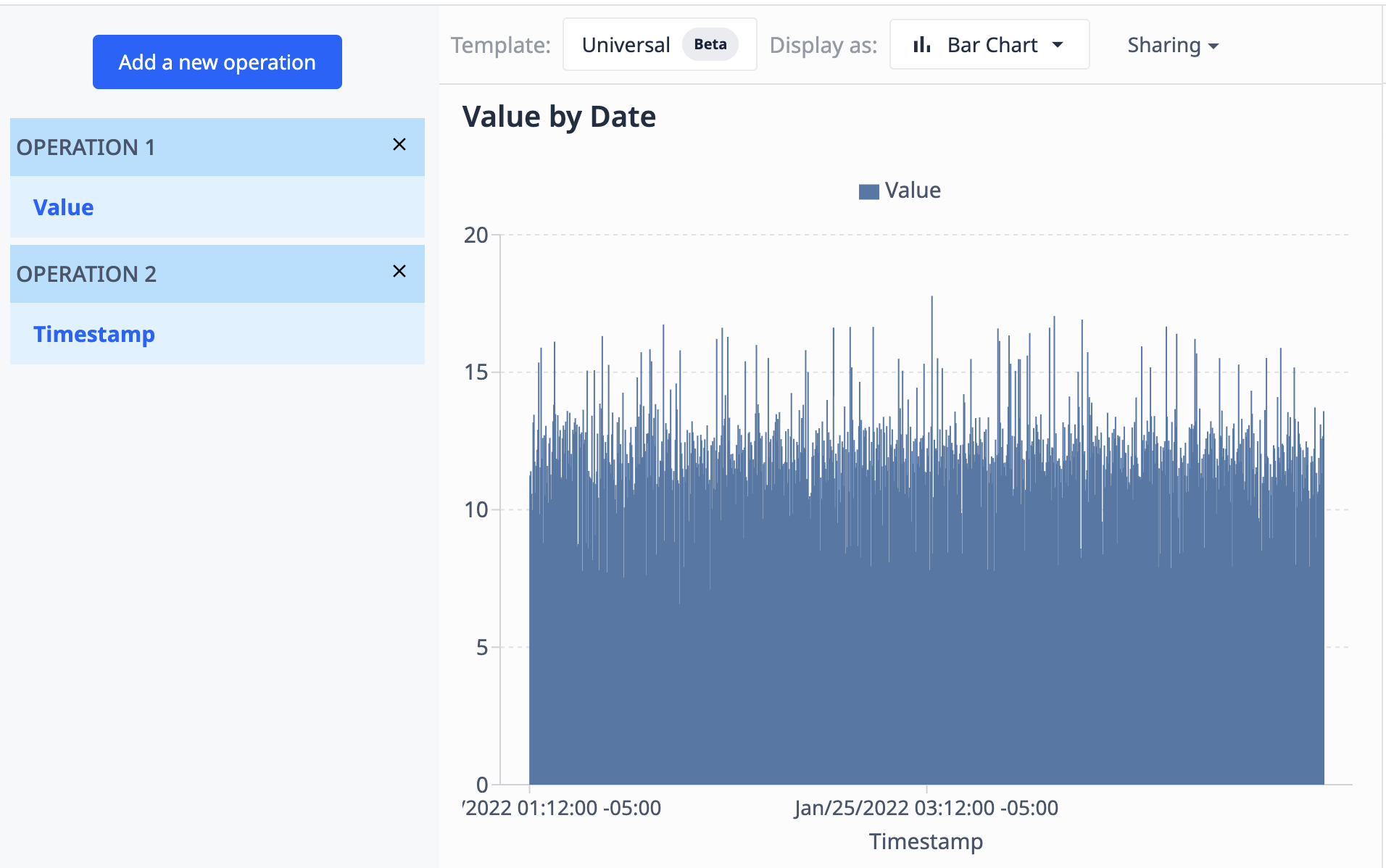
- Aggregációk
Az aggregációk olyan függvények, amelyek több sorból vesznek fel adatokat, és azokat halmazlogika alapján kombinálják. Az aggregációs függvények egy sora áll rendelkezésre előre beállított kiválasztásként, vagy a kifejezésszerkesztőn belül is használhatja az aggregációs függvényeket, hogy saját fejlett aggregációkat hozzon létre. A különböző aggregációs függvények különböző adattípusokhoz működnek. Az alábbiakban megtekintheti, hogy mely függvények állnak rendelkezésre, és milyen adattípusokat támogatnak.
Közvetlenül elérhető aggregációs függvényekEzek lehetővé teszik a sorok kombinálását:
- Átlag
- Medián
- Sum
- Minimum
- Maximum
- Módusz
- Standard eltérés
-
- percentilis
-
- percentilis
- Arány
- Arány Kiegészítés
A kifejezésszerkesztőben elérhető aggregációs funkciók
A kifejezésszerkesztőben található összesítő függvények az Ön egyedi igényei alapján részletesebb adatokat szolgáltathatnak. Az elemzésekben használható összes rendelkezésre álló kifejezésről szóló teljes útmutatóért lásd: Az elemzési szerkesztőben található kifejezések teljes listája.
Korlátozás és rendezés
Limit hozzáadásával meghatározhatja a lekérdezés eredménye által tartalmazott sorok maximális számát. A korlátozásokkal bizonyos adatokra összpontosíthat, vagy korlátozhatja a diagramban megjelenített adatok mennyiségét. Hozzáadhat például egy korlátot, hogy megjelenítse azt a három gyártósort, amelyeken az elmúlt hónapban a legtöbb hiba volt.
A rendezési adatok határozzák meg, hogy mely sorok szerepeljenek a határérték kiértékelésekor. A lekérdezés eredményének részét képező bármely mezőhöz hozzáadhat növekvő vagy csökkenő rendezést. Ha több mezőt ad hozzá a rendezéshez, akkor az adatok az első mező alapján lesznek először rendezve. Az első mező minden egyes értékéhez tartozó eredménycsoportok ezután a második stb. szerint lesznek rendezve.
Vegye figyelembe, hogy ha nem határozza meg kifejezetten a rendezést, a lekérdezés eredményének rendezése a rendelkezésre álló adatok alapján változhat. Korlátozás vagy ordinális tengelyekkel rendelkező diagramok használata esetén ez eltérő megjelenítéshez vezethet. Ezekben az esetekben javasoljuk a megfelelő rendezés hozzáadását.
A következő példa a Műveletek használatával látott grafikont használja. Itt az eredményeket 100 adatpontra korlátozzuk, és az időpontjuk alapján csökkenő sorrendbe rendezzük őket.
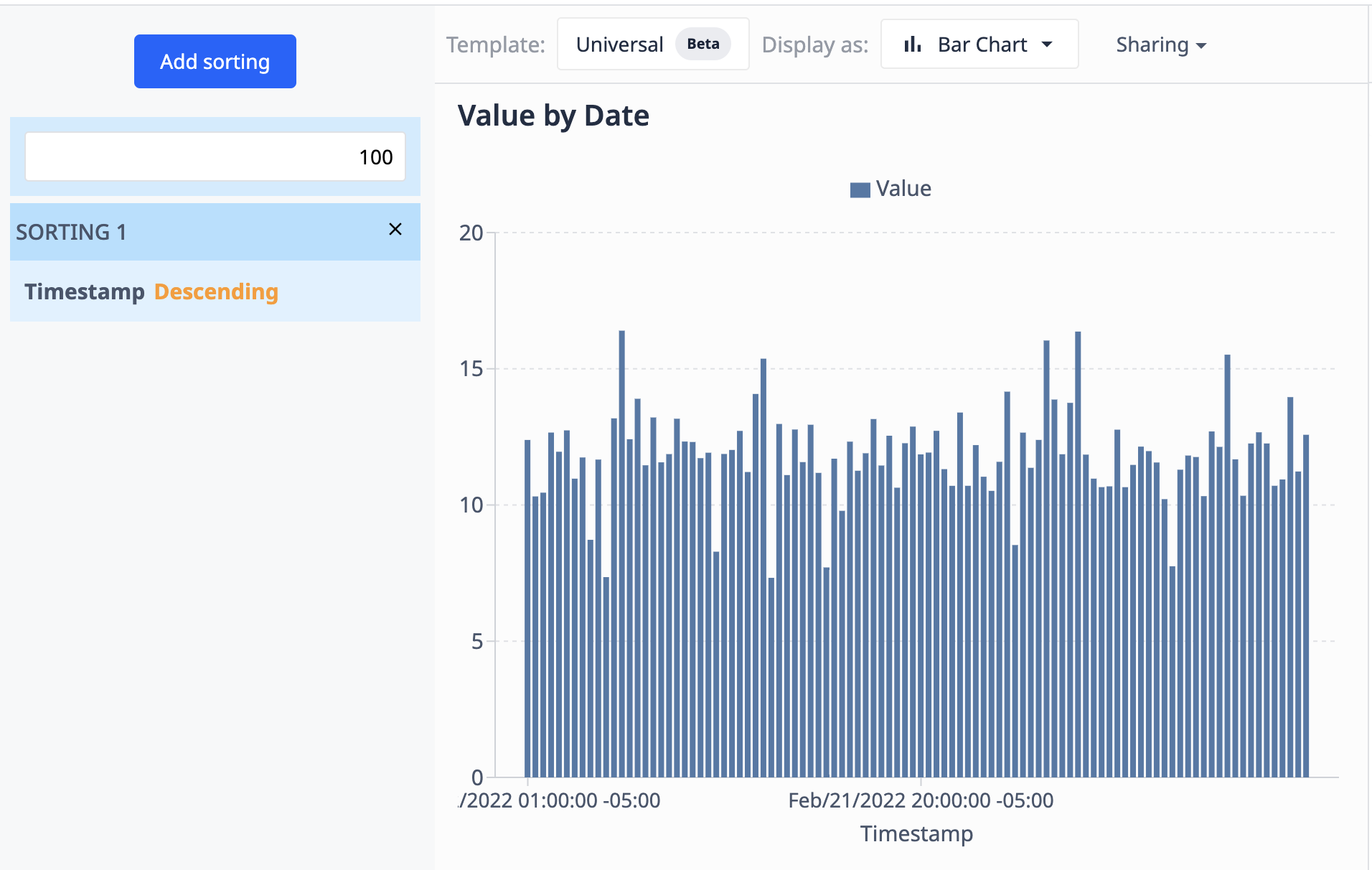
Mivel az adatforrás (a táblázat) új rekordokkal frissül, a megjelenítés csak a 100 legfrissebbet fogja mutatni.
Dátumtartomány
A dátumtartomány határozza meg, hogy milyen adatok szerepelnek az elemzés kiértékelésében. Gondoljon erre úgy, mint egy szűrőre az adathalmazban lévő dátumértékekre. A dátumtartomány az elemzést azokra az adatokra korlátozza, amelyek egy meghatározott időszakra vonatkoznak. Teljesítőképességi okokból javasoljuk, hogy a felhasználási esethez a lehető legrövidebb dátumtartományt használja, ahelyett, hogy később további szűrőket adna hozzá az idő leszűkítéséhez.
A következő dátumértékeket használjuk a különböző adatforrások dátumtartományához: * Alkalmazás befejezési adatok * Az alkalmazás befejezésének "kezdő időpontja" * Táblázat dátuma, felhasználó által választható * Létrehozás dátuma * Frissítés dátuma * Gépi adatok * A gépi tevékenység bejegyzésének kezdő időpontja.
Szűrők
A szűrők határozzák meg, hogy mely adatok szerepeljenek a lekérdezés eredményében. Tipikus felhasználási esetek: * Csak egy adott gyártósor adatainak megjelenítése * Egy adott gép kizárása az elemzésből * Csak olyan adatpontok megjelenítése, amelyek értéke magasabb egy adott küszöbértéknél.
A szűrők a feltételhez hasonlóan konfigurálhatók. Minden olyan adat, amely megfelel a feltételnek, bekerül az elemzésbe. Nézzünk néhány példát:
- A gyártósor egyenlő A
- Minden olyan rekordot tartalmaz, amelynek a "Gyártási vonal" mezőjében "A" szerepel.
- A gépazonosító nem egyenlő az "1. gép"-el
- Az összes olyan gépet tartalmazza, amely nem egyenlő az "1. gép"-gyel.
- A tesztelés időtartama > 55
- Minden olyan rekordot tartalmaz, ahol a tesztelés 55 másodpercnél tovább tartott.
A szűrők kétféleképpen határozhatók meg: 1. Az előre beállított szűrőfüggvények használata a forrásadatok egy mezőjével kombinálva 2. Egy olyan kifejezés konfigurálásával, amely egy bóléra értékelhető.
Vizualizációk
Új elemzés létrehozásakor az Univerzális sablon használatával alapértelmezés szerint a Táblázat vizualizáció van kiválasztva. A képernyő tetején található Display As (Megjelenítés mint ) beállítással bármikor átválthat egy másik megjelenítési típusra. A lehetőségek a "Table" (táblázat) mellett a következők:
- Bar
- Line
- Scatter
- Hisztogram
- Donut
- Gauge
- Box
- Egyetlen érték
- Diavetítés
- Pareto
Vizualizáció konfigurálása
A legtöbb megjelenítési típus esetében szabadon kiválaszthatja, hogy a lekérdezés eredményének mely mezőit milyen módon kívánja megjeleníteni. Ezt az Analytics-szerkesztő jobb oldalán található Adatpanelben teheti meg. Amikor először vált egy másik vizualizációra, a konfiguráció üres. A vizualizációt vagy manuálisan állíthatja be az Adatpanelen, vagy a képernyő közepén található Indítás javaslattal gombra kattintva egy javaslattal kezdheti.
A vizualizáció konfigurálásának előfeltételei a következők:
- A lekérdezés eredményében vannak adatok
- Rendelkezésre állnak a megfelelő mezők a vizualizációhoz. Például egy oszlopdiagramhoz legalább egy numerikus mezőre van szükség
Ha mindkét feltétel nem teljesül, az Analytics Editor figyelmeztető üzenetet jelenít meg.
Adatpanel beállításai
Az alábbi lista áttekintést ad a különböző megjelenítési típusok konfigurációs lehetőségeiről:
Vonal, vonal, szórás
- X tengely
- Az a mező, amelynek értékeit az X tengelyen meg kell jeleníteni.
- Y tengely
- Egy vagy több numerikus mező, amelynek értékeit az Y tengelyen kell megjeleníteni.
- Összehasonlítás
- Az a mező, amely az értékek azonos sorozatként való megjelenítésére szolgál a diagramban.
Ha több sorozatot szeretne megjeleníteni, akkor ezt vagy több mező kiválasztásával teheti meg az Y tengelyhez, vagy egy mezővel az Y tengelyhez és egy mezővel az Összehasonlítás szerinthez. Az Y tengely és az Összehasonlítás szerint több mező kombinálása nem lehetséges.
Az X tengely beállítás "..." menüjében a "Mezőértékek összehasonlítása" üzemmód elérhető ezekhez a megjelenítési típusokhoz. Ez lehetővé teszi több mező numerikus értékeinek egymás melletti megjelenítését. Ha az opció be van kapcsolva, a következő lehetőségek állnak rendelkezésre:
- X tengely
- Az összehasonlítandó numerikus mezők
- Összehasonlítás
- Az értékek azonos sorozatként való megjelenítéséhez használt mező a diagramon.
- Alapértelmezés szerint az adatok sorindexe.
Hisztogram
- Értékek
- A numerikus mező, amely azokat az értékeket tartalmazza, amelyekre a hisztogram megjelenik.
- Ennek a mezőnek az összes értéket aggregálatlanul kell tartalmaznia. A vizualizáció gondoskodik a hisztogramértékek kiszámításáról.
- Összehasonlítás
- Az "Értékek" több sorozatra való felosztására használt mező, amelyek mindegyike különálló hisztogramként jelenik meg a megjelenítésben.
Donut
- Values
- A vizualizálandó értékeket tartalmazó numerikus mezők
- Címkék
- A különböző donut-szegmensek címkéihez használt mező. Ezek megjelennek a tooltipben és a legendában.
- Alapértelmezés szerint a megjelenített adatok sorindexe.
Egyetlen érték, mérőszám
- Érték
- A megjelenítendő értéket tartalmazó numerikus mezők.
Megjegyzés: A lekérdezés eredményének első sorának értéke lesz megjelenítve. Ha a lekérdezés több sort ad vissza, akkor rendezéssel módosíthatja, hogy melyik érték legyen ez. Ha nem a várt értéket látja a vizualizációban, javasoljuk, hogy az adatok ellenőrzéséhez használja a "Lekérdezés eredményének megjelenítése" gombot az alján.
Doboz
- X tengely
- Az a mező, amelynek értékeit az X tengelyen kell megjeleníteni.
- Ebben a mezőben minden egyes értékhez külön "doboz" lesz vizualizálva.
- Y tengely
- A dobozdiagramban megjelenítendő értékeket tartalmazó numerikus mező
- Ennek a mezőnek aggregálatlanul kell tartalmaznia az összes értéket. A megjelenítés gondoskodik a dobozértékek kiszámításáról.
Pareto
- X tengely
- Az a mező, amelynek értékeit az X tengelyen kell megjeleníteni.
- Y tengely
- Az a numerikus mező, amelynek értékeit az Y tengelyen kell megjeleníteni.
A kumulatív százalékos vonal automatikusan kiszámításra kerül a vizualizációban.
Váltás a megjelenítési típusok között
Az adatpanelen konfigurált bármelyik megjelenítési típus közötti váltáskor minden kompatibilis konfiguráció átvitelre kerül. Ez minimalizálja a váltással járó erőfeszítéseket, és lehetővé teszi, hogy könnyen kipróbálhassa az adatok különböző megjelenítési lehetőségeit.
Táblázat és diavetítés
A Table (Táblázat) és a Slideshow (Diavetítés) vizualizációk nem rendelkeznek adatpanellel, és automatikusan konfigurálódnak.
A Táblázat a lekérdezésben konfigurált összes csoportosítást és műveletet megjeleníti. Ezek abban a sorrendben vannak elrendezve, ahogyan a bal oldali lekérdezéskészítőben megjelennek.
A Diavetítés a lekérdezés eredményében bármelyik képmezőben szereplő összes képet egyedi diaként mutatja. A lekérdezésben konfigurált további mezők a kép alatti táblázatban jelennek meg.
Megtalálta, amit keresett?
A community.tulip.co oldalon is megteheti, hogy felteszi kérdését, vagy megnézheti, hogy mások is szembesültek-e hasonló kérdéssel!
