Contenu x
- Première étape.
- Bâtiment
- Conception de l'application
- La recherche sur les utilisateurs au service de la valeur commerciale
- Meilleures pratiques en matière de conception d'applications
- Credo de la solution tulipe
- Architectures composables ou monolithiques mettre à jour
- Comment concevoir une solution pour les tulipes
- Comment créer des applications composables
- Comment concevoir une disposition de base efficace
- Bonnes pratiques pour nommer les éléments dans Tulip
- Comment ajouter des formes aux étapes de l'application
- Éditeur d'applications
- Présentation de l'éditeur d'applications Tulip
- Création d'une nouvelle application Tulipe
- Comment utiliser les raccourcis clavier dans l'éditeur et le lecteur d'applications ?
- Fonctionnalité multilingue dans Tulip
- Étapes
- Widgets
- Qu'est-ce qu'un widget ?
- Widgets de saisie
- Widgets intégrés
- Widgets boutons
- Comment configurer les widgets
- Ajout de widgets de saisie aux étapes mettre à jour
- Qu'est-ce qu'un widget de tableau interactif ?
- Comment utiliser la mise en forme conditionnelle
- Comment intégrer des vidéos
- Comment intégrer l'analyse dans une application
- Travailler avec des fichiers
- Remplir dynamiquement les widgets à sélection unique ou multiple
- Comment utiliser le widget case à cocher
- Comment ajouter un widget code-barres
- Comment ajouter un widget de grille à une étape
- Comment copier/coller du contenu dans les applications et entre les applications ?
- Comment ajouter un widget de jauge à votre marche
- Aperçu des widgets personnalisés mettre à jour
- Création d'un formulaire de signature Étape
- Validation des données avec les widgets de saisie mettre à jour
- Aperçu du widget de l'historique des enregistrements
- Détails techniques des étapes du formulaire
- Comment ajouter des images à une application
- Comment utiliser le widget de signature électronique
- Formatage des nombres dans les applications mettre à jour
- Déclencheur
- Qu'est-ce qu'un déclencheur ?
- Déclencheurs de niveau d'étape
- Déclencheurs au niveau de l'application
- Déclencheurs de widgets
- Un guide pour les transitions d'applications
- Capture App Screenshot
- Déclencheurs de minuterie
- Comment ajouter des déclencheurs d'appareils
- Comment ajouter des déclencheurs avec des conditions (énoncés If/Else)
- Liste des actions et des transitions dans l'éditeur de déclencheurs
- Quels sont les 10 déclencheurs les plus courants ?
- Comment définir la couleur d'un widget à partir d'un déclencheur
- Comment envoyer des courriels
- Comment configurer les utilisateurs de Tulip pour les notifications par SMS ?
- Comment imprimer des étapes à partir d'un déclencheur ?
- Comment utiliser l'éditeur d'expressions dans l'éditeur d'applications
- Détails techniques de l'éditeur d'expression
- Liste complète des expressions dans l'éditeur d'applications
- Utilisation d'expressions temporelles
- Expressions de typecasting
- Utilisation d'expressions avec des tableaux et des objets
- Travailler avec le temps dans les déclencheurs
- Formats de date personnalisés pris en charge
- Comment compléter une application
- Comment scanner des codes-barres et des codes QR via l'appareil photo de votre appareil
- Comment ajouter une expression régulière à un déclencheur ?
- Utilisation des informations sur les applications dans les applications Tulip
- Comment appeler une fonction de connecteur à l'aide de déclencheurs ?
- Variable
- Dépannage
- Dati (déesse hindoue)
- Stockage des données
- Variables dans Tulip
- Nombres et précision numérique
- Comment utiliser un modèle de données commun
- Comment utiliser le modèle de données commun pour les cas d'utilisation discrets ?
- Comment utiliser le modèle de données commun pour les cas d'utilisation dans l'industrie pharmaceutique ?
- Tableaux
- États financiers
- Connecteur
- Qu'est-ce qu'un connecteur ?
- Comment créer un connecteur
- Introduction aux hôtes du connecteur Tulip
- Comment exécuter une fonction de connecteur dans plusieurs environnements ?
- Instantanés de connecteurs
- Comprendre les tableaux et les objets dans les sorties de fonctions de connecteurs
- Affichage de listes interactives d'enregistrements de tables ou de sorties de connecteurs dans les applications
- Dépannage des connecteurs
- Partager les connecteurs entre les espaces de travail
- Connecteur Entrée Contrôle du codage
- Comment créer une base de données de test pour une fonction de connecteur ?
- Comment installer les connecteurs rapides
- Connecteurs HTTP
- Comment créer et configurer une fonction de connecteur HTTP ?
- Comment formater les sorties du connecteur HTTP
- Utilisation de connecteurs HTTP dans les applications
- Attraper les erreurs du connecteur HTTP
- Journal d'erreurs du connecteur et réessai de connexion
- OAuth 1.0
- Qu'est-ce que OAuth2.0 ?
- Configuration et détails techniques d'OAuth2.0
- Connecteurs SQL
- Connexions MQTT
- Intégration des connecteurs
- Analyse
- Qu'est-ce qu'une analyse ?
- Introduction à Analytics Builder
- Comment créer une nouvelle analyse
- Aperçu des types d'affichage mettre à jour
- Les types de modèles, expliqués
- Comment utiliser le modèle universel
- Formatage des nombres dans Analytics
- Introduction aux couches de graphiques mettre à jour
- Qu'est-ce qu'une carte de contrôle ?
- Alertes pour les cartes de contrôle
- Comment intégrer l'analyse dans une application
- Comment analyser des données provenant de plusieurs applications
- Utilisation des données machine dans l'éditeur d'analyse
- Comprendre les plages de dates
- Liste des champs dans le volet contextuel de l'analyse
- Comment utiliser l'éditeur d'expressions dans l'éditeur d'analyse
- Détails techniques de l'éditeur d'expression
- Liste complète des expressions dans l'éditeur d'analyse
- Comment modifier une application analytique
- Qu'est-ce qu'un calque de prévision ?
- Exemple d'analyse
- Comment calculer le rendement au premier passage à l'aide d'une analyse numérique ?
- Comment créer des analyses basées sur des tableaux
- Comment analyser les listes de contrôle d'inspection de la qualité à l'aide d'une analyse "à variables multiples" ?
- Comment comparer les défauts par type et par jour en utilisant le champ "Comparer par" ?
- Comment afficher les statistiques sur les temps de cycle par utilisateur à l'aide d'un tableau d'analyse ?
- Comment créer un diagramme de Pareto des défauts courants ?
- Comment créer votre premier tableau de bord d'atelier
- Comment partager des analyses ou des tableaux de bord
- Comment créer des tableaux de bord
- Vision
- Démarrer avec Vision
- Centre de vision
- Fonctionnalité de Tulip Vision
- Lignes directrices et limites de la lecture des codes-barres Vision
- Utilisation du détecteur de couleurs
- Utilisation du détecteur de changement
- Utilisation du détecteur de gabarits
- Utilisation du widget de la caméra Vision dans les applications
- Utilisation de la fonction d'instantané de Vision
- Utilisation des détecteurs de codes-barres et de Datamatrix
- Utilisation d'un détecteur de reconnaissance optique de caractères (OCR)
- Utilisation d'une capture d'écran comme source de caméra pour Vision
- Tulip Vision Integrationen
- Dépannage de la vision
- Surveillance de l'équipement
- Introduction à la surveillance des machines
- Comment configurer votre première machine
- Comment utiliser les sorties machine dans les déclencheurs
- Comment créer votre première source de données OPC UA
- Comment construire votre premier connecteur MQTT
- Comment ajouter un widget machine à une application
- Comment préparer vos machines à se connecter à Tulip
- Comment ajouter des attributs de machine, des raisons d'arrêt et des états ?
- Écrire sur les attributs de la machine à l'aide des protocoles OPC UA/MQTT mettre à jour
- Utilisation de périphériques Edge pour exécuter l'hôte du connecteur On Prem
- Utilisation de Edge MC pour exécuter OPC UA
- Comment utiliser l'API d'attributs de machine
- Comment configurer les types de machines
- Comment ajouter et configurer des machines
- Comment créer votre premier déclencheur de machine
- Recommandations pour l'architecture de surveillance des machines avec Tulip
- Industries réglementées
- Les bases de la création d'applications GxP
- Meilleures pratiques pour la création d'applications GxP
- Résumé des capacités GxP de Tulip
- Collecte de données GxP
- Corrections des données de traitement et examen de celles-ci
- Fonctionnalité de pause et de reprise
- Utilisation du widget Historique des enregistrements pour visualiser les modifications apportées aux enregistrements d'une table
- Comment exporter les données de l'application au format CSV
- Examen des données pour la conformité GxP
- Validation des données avec les widgets de saisie mettre à jour
- Personnaliser les rôles des utilisateurs mettre à jour
- Comment utiliser le widget de signature électronique
- Co-pilote de première ligne
- Utilisation et prix de Frontline Copilot
- Widget Chat de l'opérateur
- Page des réglages du copilote Frontline
- Tulip AI Composer
- Traduire l'action de déclenchement
- Extraction de texte à partir d'une image Action de déclenchement mettre à jour
- Réponse aux questions des actions de déclenchement de données/documents
- Classifier l'action déclenchante
- Saisie de la parole en texte
- Chat avec les tables
- FAQ sur la gouvernance des copilotes de ligne
- Automatismes
- Premiers pas avec les automatisations
- Présentation de l'éditeur d'automatismes
- Comment mettre en place des automatismes programmés
- Comment utiliser les versions d'Automations
- Comment utiliser l'historique des exécutions d'Automations
- Limites de l'automatisation
- Solution de gestion des stocks avec automatismes
- Avertissement de bouclage dans les automatismes
- Exportation et importation
- Conception de l'application
- Applications en cours d'exécution
- Comment utiliser le lecteur de tulipes
- Comment faire fonctionner une application dans le lecteur Tulip mettre à jour
- Choisir entre les applications Tulip Web Player et Tulip Player
- Comment passer d'un compte Tulip à un autre
- Comment utiliser le lecteur Tulip sur Apple iOS et iPadOS
- Langues prises en charge par Tulip
- How to access your Tulip Player/Instance in an iFrame
- Comment faire fonctionner les applications Tulip sur différents appareils ?
- Comment dépanner le lecteur Tulip
- Appareils recommandés pour l'exécution du lecteur de tulipes mettre à jour
- Comment redémarrer le lecteur Tulip si l'écran devient vide ?
- Comment exporter les données de l'application au format CSV
- Gestion de
- Configuration de votre instance Tulip
- Gestion des utilisateurs
- Intro: User Management
- Ajouter et gérer des utilisateurs
- Mise à jour des champs sur les utilisateurs et opérateurs individuels de Tulip à partir d'applications
- Personnaliser les rôles des utilisateurs mettre à jour
- Créer et gérer des groupes d'utilisateurs
- Autorisation et contrôle d'accès à l'aide de SAML
- Comment ajouter la carte RFID d'un nouvel opérateur à l'aide d'un lecteur RFID ?
- Gestion des applications
- Intro : Gestion des applications
- Vue d'ensemble de la publication de l'application
- Ajouter et gérer des applications
- Créer et gérer des versions d'applications
- Configurer les approbations pour vos applications
- Modifier les droits d'édition des applications individuelles
- Restaurer une version de développement d'une application à partir d'une version publiée
- Comparer les versions des applications
- Comment récupérer les applications archivées
- Gestion de la médecine
- Gestion de l'espace de travail
- Gestion des joueurs
- Linux Player
- Caractéristiques des joueurs par plate-forme mettre à jour
- Comportement de déconnexion du joueur
- Comment masquer le menu développeur dans Tulip Player
- Comment désactiver les mises à jour automatiques pour le lecteur Tulip
- Résolution des erreurs de la base de données de secours
- Utilisation du lecteur Tulip avec différents comptes Windows
- Déploiement de Tulip Player en entreprise
- Vue d'ensemble des stations et des interfaces mettre à jour
- Comment dépanner le lecteur Tulip
- Developers
- Connect to Software
- Connectors
- Qu'est-ce qu'un connecteur ?
- Comment créer un connecteur
- Introduction aux hôtes du connecteur Tulip
- Configuration et détails techniques d'OAuth2.0
- Comment exécuter une fonction de connecteur dans plusieurs environnements ?
- Instantanés de connecteurs
- Comprendre les tableaux et les objets dans les sorties de fonctions de connecteurs
- Connecteur Entrée Contrôle du codage
- Comment créer et configurer une fonction de connecteur HTTP ?
- Comment formater les sorties du connecteur HTTP
- Utilisation de connecteurs HTTP dans les applications
- Comment écrire une fonction de connecteur SQL
- Aperçu des fonctions MQTT
- Comment construire votre premier connecteur MQTT
- Lignes directrices pour l'intégration des écosystèmes
- Intégration d'Amazon Bedrock
- Intégration AWS - Récupérer toutes les tables Tulip et les écrire sur S3
- Intégration AWS - Envoi de données à AWS via API Gateway et Lambda
- Intégration AWS - Récupérer les données des tables Tulip
- Intégration AWS - Récupérer toutes les tables Tulip dans une fonction Lambda
- Exemple de script ETL Glue pour le chargement des données de la table Tulip
- Intégration IoT Sitewise
- Gestion quotidienne allégée avec AWS
- Intégration de Microsoft Azure Machine Learning
- Intégration Microsoft Fabric
- Intégration de Rockwell FactoryTalk Optix
- Intégration de Snowflake avec le tissu - Récupérer les tables de Tulip dans Snowflake
- Connectors
- Connect to Hardare
- Edge Devices
- Borde IO
- Rand MC
- Mise en place d'un Edge MC
- Comment enregistrer un Edge MC mettre à jour
- Comment faire : Utiliser Serial on Edge MC
- Comment configurer une connexion sans fil sur Edge MC
- Spécifications techniques pour Edge MC
- Réinitialisation des paramètres d'usine de l'Edge MC
- Comment activer l'assistance à distance Edge MC
- Kit machine
- Pasarela IO
- Annonce de fin de vente de la passerelle I/O
- Mise en place d'une passerelle Tulip I/O
- Comment enregistrer une passerelle E/S
- Réinitialisation de la passerelle d'E/S aux paramètres d'usine
- Comment activer l'assistance à distance de la passerelle d'E/S
- Comment utiliser les entrées analogiques sur la passerelle d'E/S
- Comment utiliser le pilote de série générique sur la passerelle d'E/S
- Spécifications techniques de la passerelle Tulip I/O Gateway
- Fabrik-Kit
- Guide de démarrage rapide du kit d'usine
- Matériaux du kit d'usine et informations sur l'approvisionnement
- Configuration de la bande lumineuse Edge IO
- Comment configurer une pédale de commande dans Tulip ?
- Test de l'unité du capteur de faisceau de rupture
- Tests à l'unité des capteurs de température et d'humidité
- Comment inclure les appareils du kit d'usine dans les applications
- Kit d'éclairage Tulip Initial Setup
- Comment utiliser le kit d'éclairage des tulipes
- Connexion des périphériques USB du kit d'usine (code-barres, pédale, température/humidité)
- Mise en place du capteur à faisceau brisé
- Kit d'éclairage Test unitaire
- Caractéristiques techniques du kit d'éclairage Tulip
- Assemblage de la pile de lumière
- Gestion des appareils en périphérie
- Comment activer HTTPS sur votre appareil Edge
- Comment configurer le portail des appareils
- Comment gérer les appareils Edge dans Tulip
- Versions du micrologiciel prises en charge
- Comment gérer les mises à jour automatiques des appareils Edge
- Comment configurer les paramètres du réseau sur votre appareil Tulip Edge
- Comment configurer l'interface LAN d'un dispositif Edge ?
- Comment les appareils Tulip Edge obtiennent-ils leur adresse IP ?
- Comment configurer les paramètres SNMP pour les appareils Edge ?
- Comment trouver la version du système d'exploitation de votre appareil Edge
- FAQ sur le dispositif Tulip Edge
- Portail HTTPS de l'appareil Edge
- Études de cas pour les dispositifs finaux
- Dispositifs de périphérie et FlowFuse
- Comment activer et configurer le courtier MQTT de l'appareil Edge
- Comment configurer un pont MQTT sur un appareil Edge
- Utilisation de Edge MC pour exécuter OPC UA
- Comment utiliser GPIO sur Edge IO
- Utilisation de Node-RED avec Edge MC
- Utilisation de Node-RED avec Edge IO
- Comment faire : Utiliser le mode sériel avec Edge IO
- Utilisation de périphériques Edge pour exécuter l'hôte du connecteur On Prem
- Communiquer avec les machines à l'aide du Connecteur Host et du Node-RED d'Edge MC
- Ce que vous pouvez faire avec Tulip + IoT
- Dépannage des appareils Tulip Edge
- Appareils compatibles
- Liste des appareils Plug And Play fonctionnant avec Tulip
- Création et support des pilotes de périphériques
- Support des pilotes de périphériques dans Tulip
- Comment configurer un lecteur de codes-barres
- Utilisation du pilote série
- Comment intégrer une imprimante Zebra avec Tulip
- Utilisation du pilote d'imprimante réseau Zebra
- Utilisation du pilote de l'imprimante d'étiquettes Zebra GK Series
- Utilisation du pilote USB Bobe Box
- Utilisation du pilote In-Sight 2000 de Cognex
- Comment configurer Cognex et Tulip
- Utilisation du pilote du PH-mètre MT SevenExcellence
- Utilisation du pilote ADC générique
- Utilisation du pilote de thermomètre Omega HH806
- Utilisation du conducteur de pied à coulisse numérique
- Comment configurer le thermomètre Bluetooth TS05 de General ?
- Utilisation du pilote TCP DataMan de Cognex
- Configuration du récepteur Mitutoyo U-WAVE pour Windows Tulip Player
- Utilisation du pilote de balance Brecknell PS25
- Utilisation du pilote RFID
- Utilisation du pilote Kolver EDU 2AE/TOP/E
- Utilisation du pilote de la pédale USB
- Utilisation du pilote de protocole ouvert Torque
- Utilisation du pilote de la balance Dymo M10 USB
- Utilisation du pilote In-Sight de Cognex
- Utilisation du pilote Telnet
- Utilisation du pilote générique d'E/S
- Comment configurer un contrôleur de couple Kolver
- Utilisation du pilote de pied à coulisse multicanal Insize
- Utilisation du pilote de la balance USB Dymo S50
- Configuration de Zebra Android DataWedge
- Utiliser le pied à coulisse numérique Mitutoyo avec le pilote U-wave Mitutoyo
- Comment ajouter une balance Ohaus et stocker la production dans une variable ?
- Tests à l'unité des capteurs de température et d'humidité
- Troubleshoot
- Nodo-RED
- Aperçu de Node-RED
- Instructions
- Mise à jour de Node-RED
- Envoi de données d'un nœud-RED à Tulip avec des nœuds Tulip mettre à jour
- Envoi de messages de Tulip à Node-RED
- Utiliser Node-RED avec l'API Tulip
- Comment faire : Utiliser le mode sériel avec Node-RED
- Importation de flux Tulip Node-RED
- Comment faire : Utiliser le mode sériel avec Edge IO
- Études de cas
- Comment configurer les appareils Modbus
- Comment configurer les appareils PICK-IQ de Banner avec Edge IO
- Comment envoyer des données à des machines à partir d'appareils périphériques à l'aide de Node-RED et de balises Tulip
- Communiquer avec les machines à l'aide du Connecteur Host et du Node-RED d'Edge MC
- Connexion d'un capteur 4-20 mA avec Edge IO et Node-RED
- Gestion des états des machines et du nombre de pièces avec Edge IO et Node-RED
- Connexion d'un oscilloscope analogique avec Edge IO et Node-RED
- Connecter les Phidgets filaires avec Edge MC et Node-RED
- Edge Devices
- Écrire des composants réutilisables
- Travailler avec des API
- Edge Driver SDK
- Connect to Software
- Documentation technique et informatique
- Calendrier des événements de maintenance mettre à jour
- Comment obtenir le soutien des tulipes mettre à jour
- Infrastructure informatique
- Guide de bienvenue de Tulip IT
- Configuration de votre liste d'adresses IP autorisées
- Aperçu des options de sécurité de Tulip
- Guide de la sécurité informatique de Tulip mettre à jour
- Introduction aux hôtes du connecteur Tulip
- Tulip & Device Architecture
- Prise en charge de la version de l'hôte du connecteur sur site Nouveau
- Activation des rotations de journaux pour le conteneur Connector Host existant sur site
- Recommandations pour l'architecture de surveillance des machines avec Tulip
- Détails de la machine virtuelle Tulip sur site
- Composants de la plate-forme Tulip et diagramme du réseau
- Déployer Tulip dans AWS GovCloud
- Comment utiliser un serveur proxy avec Tulip Player sous Windows
- Vue d'ensemble des hôtes de connecteurs sur site
- Exigences en matière de réseau pour un déploiement de Tulip Cloud mettre à jour
- Formulaire W-9 de Tulipe
- Quelles sont les politiques et l'infrastructure de Tulip en matière de cybersécurité ?
- LDAP/SAML/SSO
- Comment utiliser le portail des partenaires de Tulip
- Guides
- Vers la transformation numérique
- Use Cases by Solution
- Exemples
- Comment obtenir une visibilité en temps réel des ordres de travail par poste de travail ?
- Tutoriel sur l'audit 5S
- Comment créer une application automatisée de rapport de rejet
- Comment planifier votre première application pour les opérations de première ligne
- Comment suivre les audits de machines dans un tableau
- Comment automatiser vos ordres de travail dans une application d'opérations de première ligne
- Comment utiliser les applications de fabrication dans les environnements à forte mixité
- Comment créer une application numérique d'instructions de travail
- Comment suivre la généalogie des produits à l'aide de tableaux
- Comment ajouter une balance Ohaus et stocker la production dans une variable ?
- Comment déduire un tableau d'inventaire à la fin d'une opération ?
- Comment utiliser le "modèle d'interface utilisateur" des instructions de travail ?
- Comment créer une matrice de compétences avec des champs d'utilisateur
- Comment créer une table de nomenclature ?
- Comment gérer vos stocks à l'aide de tableaux
- Comment transmettre des données dynamiques entre plusieurs applications à l'aide de champs d'utilisateurs ?
- Comment naviguer entre plusieurs applications en créant une "application de routage" ?
- 📄 Suivi des commandes
- 📄 Suivi des défauts
- Bibliothèque
- Utilisation de la bibliothèque des tulipes mettre à jour
- Laboratory Operation App Suite
- Collections de la bibliothèque
- Applications de la bibliothèque
- Exemples pédagogiques
- Exemples fonctionnels
- Exemple fonctionnel Andon
- Exemple fonctionnel d'inspection
- Exemple fonctionnel des données de la tulipe
- Exemple fonctionnel de Duro PLM
- Technicon - Universal Robots Exemple fonctionnel
- United Manufacturing Hub - Exemple fonctionnel
- Exemple de diagramme de contrôle
- Galerie de photos
- Test unitaire AI - Document Q&R
- Solutions pour les applications
- Suite d'applications GMAO
- Zerokey solutions
- Visibilité des performances
- Paquet d'application pour la déclaration électronique des lots (eBR)
- CAPA Lite par PCG
- 5 Pourquoi Root Cause avec l'IA
- Signalement simple des défauts grâce à l'IA
- Constructeur de cas d'entreprise
- Réunion de démarrage Shift
- Kanban App Suite
- Tableau de bord simple de l'OEE
- Solution de nomenclature Arena
- Equipment Management App Suite
- Liste de contrôle simple
- Suite de gestion des listes de contrôle
- Attendance Management Simple Solution
- Applications de la bibliothèque Pack & Ship
- CAPA Management
- Application de caméra mobile
- Calculateur OEE
- Tableau de bord de la production horaire
- Matériau Backflush
- Tableau de bord des événements de qualité
- Application de rendement de premier passage
- De la cueillette à la lumière
- Solutions de formation
- Inventaire des systèmes numériques
- Localisation avec la vision
- Gestion de l'accès aux systèmes numériques
- Gestion du matériel
- Gestionnaire d'outils et de biens
- Gestion d'événements de qualité
- Avance par palier avec capteur de rupture de faisceau
- Chronomètre numérique
- Liste de contrôle de l'audit
- Katana ERP App
- Évaluation de base de haut niveau
- BOM Management
- Gestionnaire des incidents de sécurité
- Composable Lean
- Composable Mobile
- Comment postuler
- eDHR App Suite
- Modèle de formation
- Quality Event Management App Suite
- Batch Packaging Template App
- Modèle de présentation de tableau de bord
- Tableau de bord de la surveillance des machines
- Modèle de suivi des défauts
- Configuration des couleurs
- Exemple d'instructions de travail
- Modèle de conception
- Gestion de la formation
- Modèles d'instructions de travail
- Work Instructions Template
- Modèle de picklist
- Modèles de base pour la création d'applications tulipes
- Tableau de bord des flux de voyageurs et de matériel
- Modèle de suivi des commandes
- Exemples pédagogiques
- MES compostable
- Système MES pour le secteur pharmaceutique.
- Connecteurs et tests unitaires
- Test d'unité Planeus mettre à jour
- Connecteur COPA-DATA Nouveau
- Connecteur Veeva
- Connecteur Inkit
- Connecteur MRPeasy
- Connecteur Oracle Fusion
- Connecteur LabVantage et test d'unité
- Connecteur Google Chat
- Connecteur Salesforce
- Vue d'ensemble de Litmus
- Connecteur eMaint
- Connecteur eLabNext
- Connecteur ERP Acumatica
- Connecteur CETEC
- Connecteur PagerDuty
- Intégration de NiceLabel
- Vue d'ensemble de l'intégration d'Aras
- Intégration SDA
- Nymi Band Unit Test
- Intégration de l'arène mettre à jour
- Tests d'unités de scanners de codes à barres
- Tests de l'unité Footpedal
- Démarrer avec Tulip sur le casque RealWear
- Connecteur de table d'aération
- Connecteur Shippo
- Intégration du barman
- SAP S/4 HANA Cloud Connector
- Tests d'unités de scanners RFID
- Connecteur Jira
- Test de l'imprimante d'étiquettes Zebra
- Connecteur Google Translate
- MSFT Power Automate
- Connecteur OpenAI
- Google Calendar Connector
- Test unitaire de l'API Tulip
- Test de l'unité Duro PLM
- Test d'unité HiveMQ
- Intégration de NetSuite
- Test d'unité de Cognex
- Intégration de PowerBI Desktop
- Test de l'unité ProGlove
- Intégration Fivetran
- Intégration de ParticleIO
- Connecteur Google Drive
- Connecteur flocon de neige mettre à jour
- Connecteur SAP SuccessFactors
- ZeroKey Integration
- Google Geocode Connector
- Connecteur Google Sheets
- Comment intégrer Tulip à Slack
- Test de l'unité HighByte Intelligence Hub
- Test unitaire de LandingAI
- Test de l'unité LIFX (lampes sans fil)
- Connecteur de calendrier Microsoft
- M365 Dynamics F&O Connecteur
- Connecteur Microsoft Outlook
- Connecteur Microsoft Teams
- Connecter l'API Microsoft Graph à Tulip avec Oauth2
- Connecteur Microsoft Excel
- Apps et connecteurs NetSuite
- Connecteur OpenBOM
- Tests unitaires sur les balances
- Connecteur InfluxDB
- Connecteur Augury
- Connecteur ilert
- Connecteur Schaeffler Optime
- Connecteur Atlas MongoDB
- Connecteur MaintainX
- Connecteur Twilio
- Connecteur SendGrid
- Connecteur Solace
- Comment concevoir des applications Tulip pour le casque RealWear
- Connecteur OnShape
- Widgets personnalisés
- Widget personnalisé de programmation Nouveau
- Widget chronologique
- Widget de visualisation d'arbre json
- Widget de gestion des tâches Kanban
- Widget de badge
- Widget Timer avancé
- Bouton segmenté Widget personnalisé
- Jauge dynamique Widget personnalisé
- Widget snack-bar
- Test de l'unité de détection de changement
- Indicateur de couleur d'état Test de l'unité
- Vérification de la longueur d'entrée Test de l'unité
- Test unitaire du widget personnalisé de la calculatrice
- Test unitaire du widget d'annotation d'images
- Widgets du tableau de bord Lean
- Test d'unité Looper
- Test d'unité du chronomètre
- Numéro de l'unité d'entrée Test
- Test d'unité du pavé numérique
- Jauges radiales
- Test d'unité du menu pas à pas
- Widget SVG
- Test de l'unité de saisie de texte
- Conseil sur les outils Test d'unité
- Instructions de travail Points de soins Test d'unité
- Test unitaire du widget de signature électronique écrit
- Test d'unité ZPL Viewer
- Widget graphique linéaire simple
- Widget personnalisé pour les étagères
- Slider Widget
- Widget personnalisé NFPA Diamond
- Widget personnalisé Réussite - Échec
- Widget personnalisé Simpler Timer
- Widgets d'intégration de Nymi Presence
- Automatismes
- Check Expired Training
- Alerte et escalade d'événements : Gestion des événements en retard
- Notification horaire de l'état de la production
- Mise à jour de l'état des équipements de maintenance
- Réinitialisation de l'état de l'équipement
- Réinitialisation de l'état d'étalonnage
- Rappel de contrôle d'état de la machine
- Automatisation de la mise à jour du tableau d'inventaire
- Automatisation du connecteur Slack
- Vérification du nombre de pièces

Tableau Importation Exportation
- Mis à jour le 24 Mar 2025
- 2 Minutes à lire
- Contributeurs

Résumé de l’article
Avez-vous trouvé ce résumé utile ?
Merci pour vos commentaires
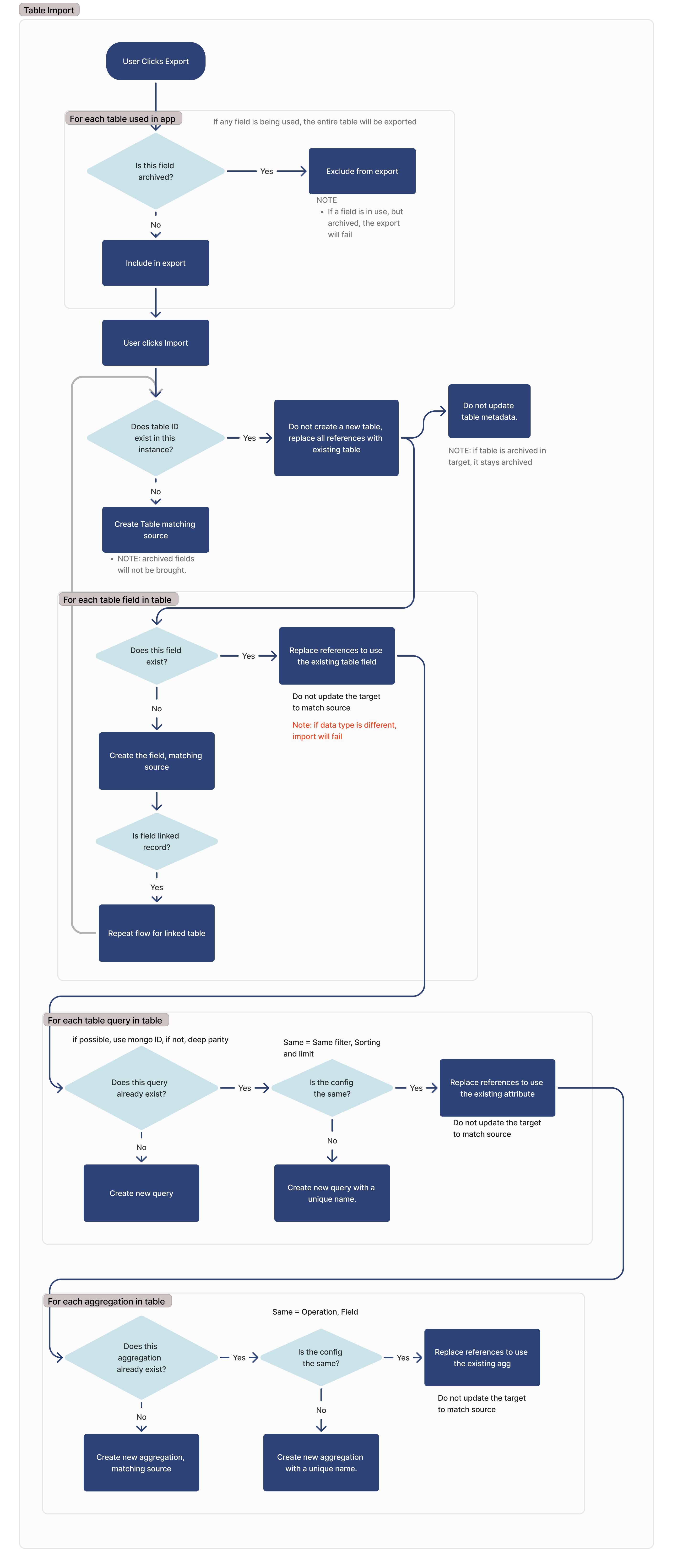
Diagramme d'exportation et d'importation
Vous trouverez ci-dessous l'ensemble du flux de transfert pour les tables, les requêtes et les agrégations de Tulip. Ce document fournira une explication détaillée de ce flux.
Champs d'utilisateur personnalisés et tables d'activité des machines
Le flux décrit ci-dessous s'applique également à l'exportation et à l'importation des tables de champs d'utilisateurs personnalisés et des tables de champs d'activité de la machine.
Exportation
Au cours du processus d'exportation, l'application ou l'automatisation exportée signale toutes les tables utilisées dans cette application. Une table est considérée comme utilisée si l'une des conditions suivantes est remplie :
- affichée dans un widget "Enregistrement de tableau
- Utilisé dans un widget de saisie
- affiché dans un tableau interactif
- Utilisé dans un déclencheur
- Utilisé dans une action d'automatisation
- Utilisé dans un bloc d'événement d'automatisation
- Utilisé dans un filtre pour une requête de tableau, un tableau interactif ou un widget d'analyse
- Utilisé comme entrée ou sortie d'un widget personnalisé
Si un champ est archivé, il ne sera pas exporté. Si un champ est archivé mais en cours d'utilisation, l'exportation échouera.
Importer
Archived Table Fields
Archived table fields will not be exported, and any references to those fields within applications will need to be remapped on import.
Recherche d'une table identique
Pour identifier les tables correspondantes lors de l'importation, nous recherchons les identifiants correspondants. Si une table avec le même identifiant est trouvée, nous ne créons pas de nouvelle table et nous nous appuyons sur la table existante.
Si la table du site d'importation est archivée, elle le restera.
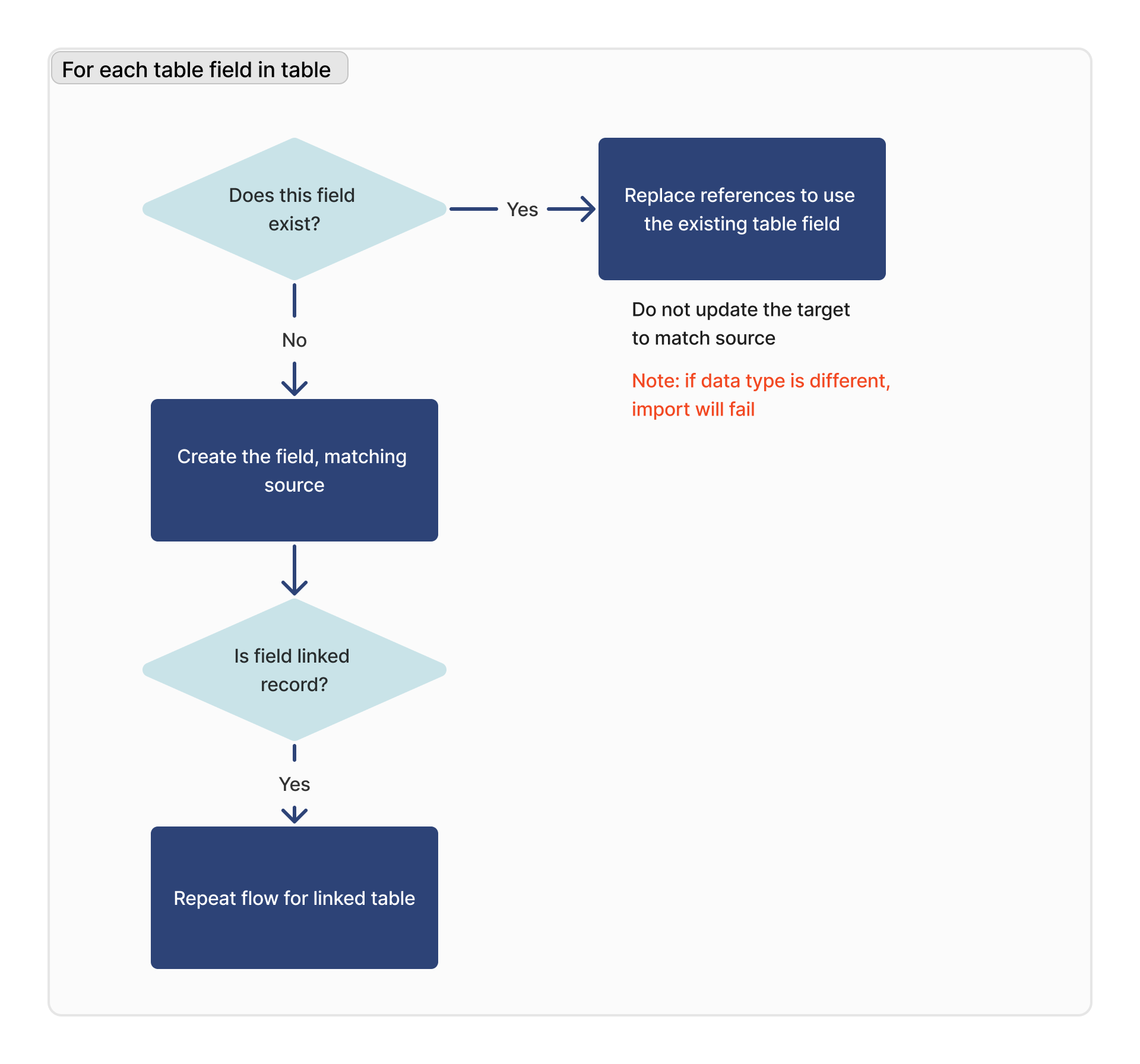
Pour chaque champ de table
Pour chaque champ de table, nous recherchons un champ correspondant sur la base de l'ID de colonne de ce champ.
Si le type de données du champ correspondant est différent, l'importation échoue.
Si le champ est un champ d'enregistrement lié, la table liée sera ajoutée à la liste des dépendances pour l'importation, et ce flux sera répété pour cette table.
Pour chaque requête
Pour chaque requête de la table importée, nous vérifions si cette requête existe. Si un ID correspondant est trouvé, nous vérifions que la configuration est identique (limite, tri et filtrage) entre la cible et la source.
Si aucune requête correspondante n'est trouvée, une nouvelle requête est créée. Si une requête correspondante est trouvée, mais qu'elle n'est pas identique à l'instance cible, une nouvelle requête sera créée avec un nouveau nom.
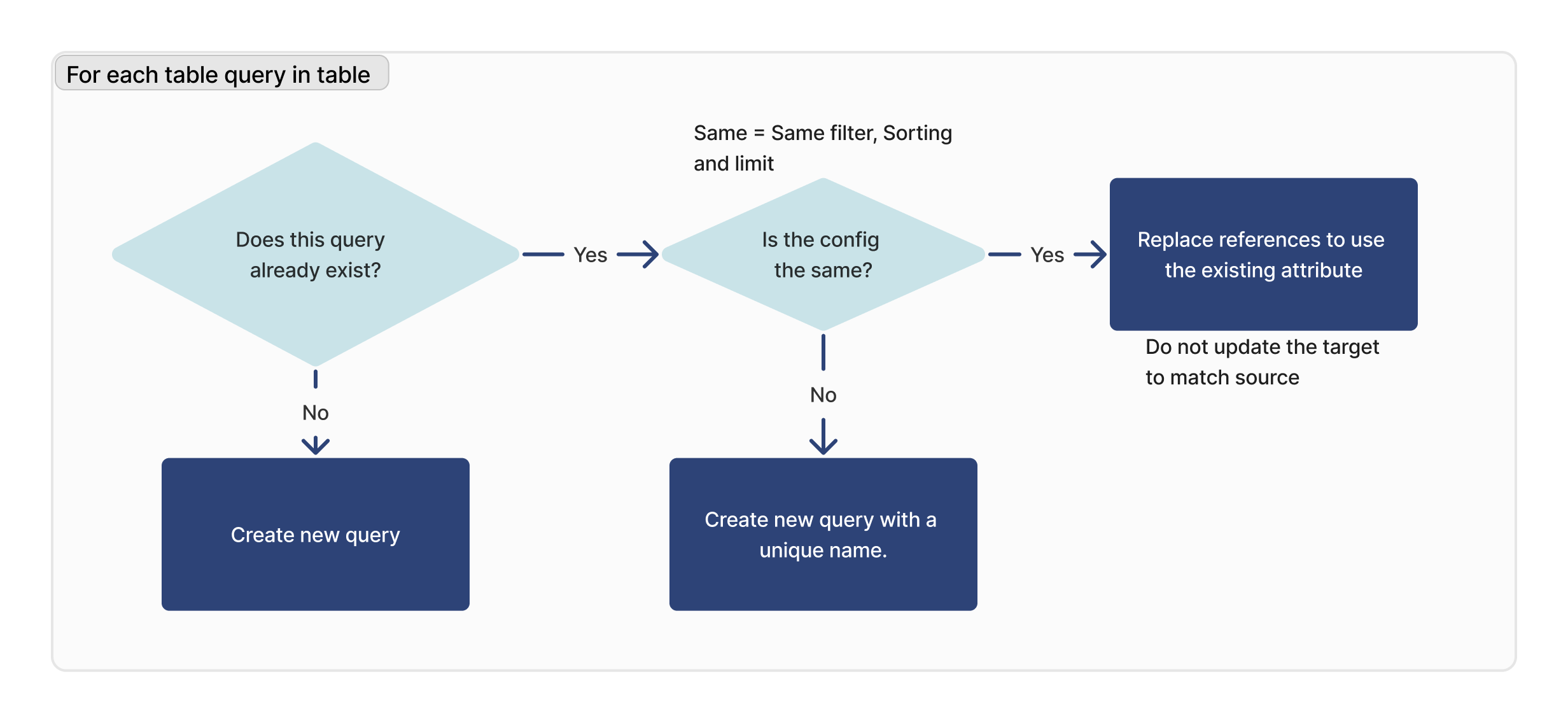
Remarque : cela ne s'applique pas aux champs d'utilisateur personnalisés ni aux tables d'activité des machines.
Pour chaque agrégation
Pour chaque agrégation dans la table importée, nous vérifions si cette requête existe. Si un ID correspondant est trouvé, nous vérifions que la configuration est identique (opération, champ) entre la cible et la source.
Si la requête correspondante est introuvable, une nouvelle requête est créée. Si une requête correspondante est trouvée, mais qu'elle n'est pas identique à l'instance cible, une nouvelle requête sera créée avec un nouveau nom.
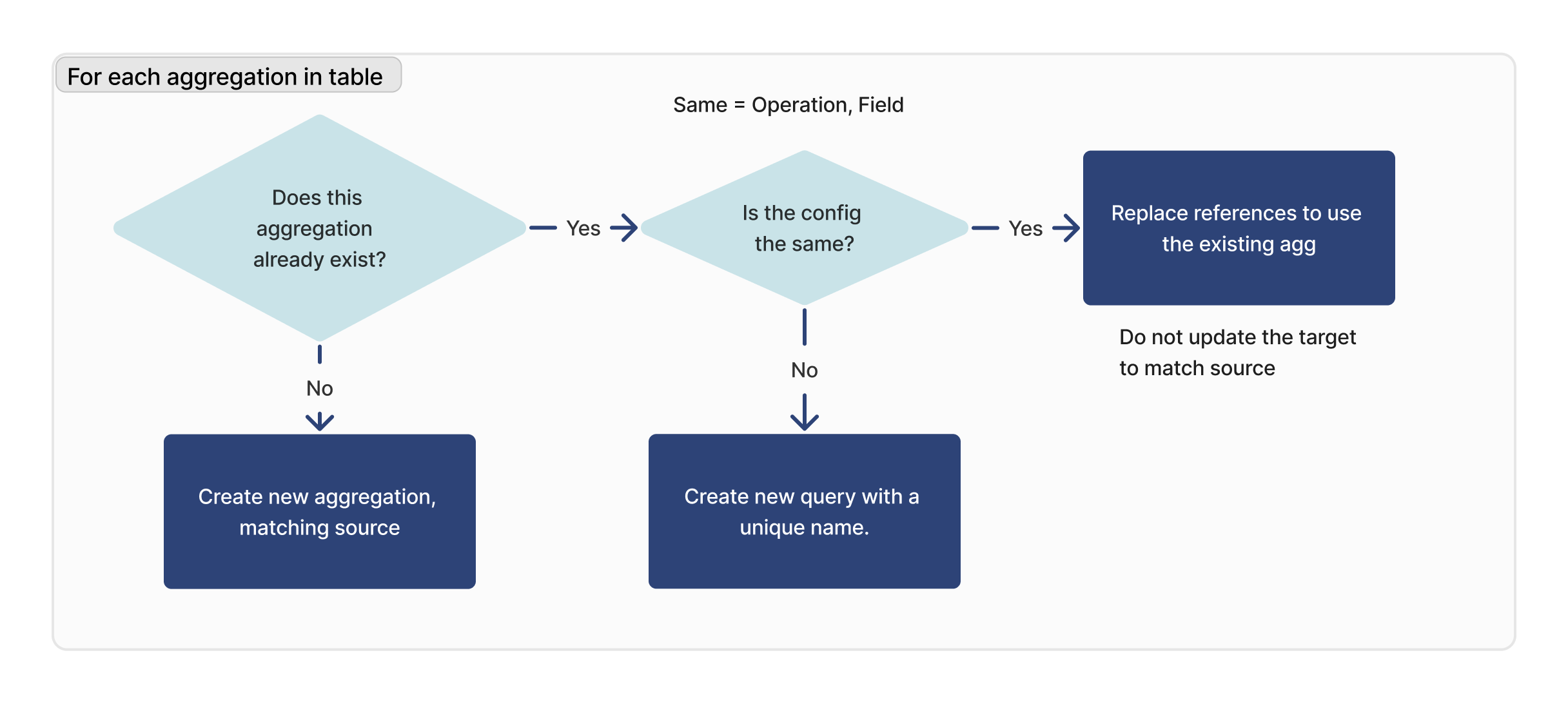
Remarque : cela ne s'applique pas aux champs d'utilisateur personnalisés ni aux tables d'activité des machines.
Cet article vous a-t-il été utile ?
Merci pour vos commentaires! Notre équipe vous répondra
Comment pouvons-nous améliorer cet article?
Vos commentaires
Commentaire
Commentaire (Optionnel)
Limite de caractères : 500
S’il vous plaît entrer votre commentaire
Messagerie électronique (Optionnel)
Messagerie électronique
Veuillez saisir un e-mail valide
