
Semplificare l'acquisizione dei dati da Tulip ad AWS S3 per maggiori opportunità di analisi e integrazione.
Scopo
Questa guida spiega passo per passo come recuperare tutti i dati di Tulip Tables tramite una funzione Lambda e scrivere su un bucket S3.
Questo va oltre la query di base di fetch e itera tutte le tabelle in una data istanza; questo può essere ottimo per un lavoro ETL settimanale (Extract, Transform, Load).
La funzione lambda può essere attivata tramite una serie di risorse, come i timer di Event Bridge o un gateway API.
Un esempio di architettura è riportato di seguito: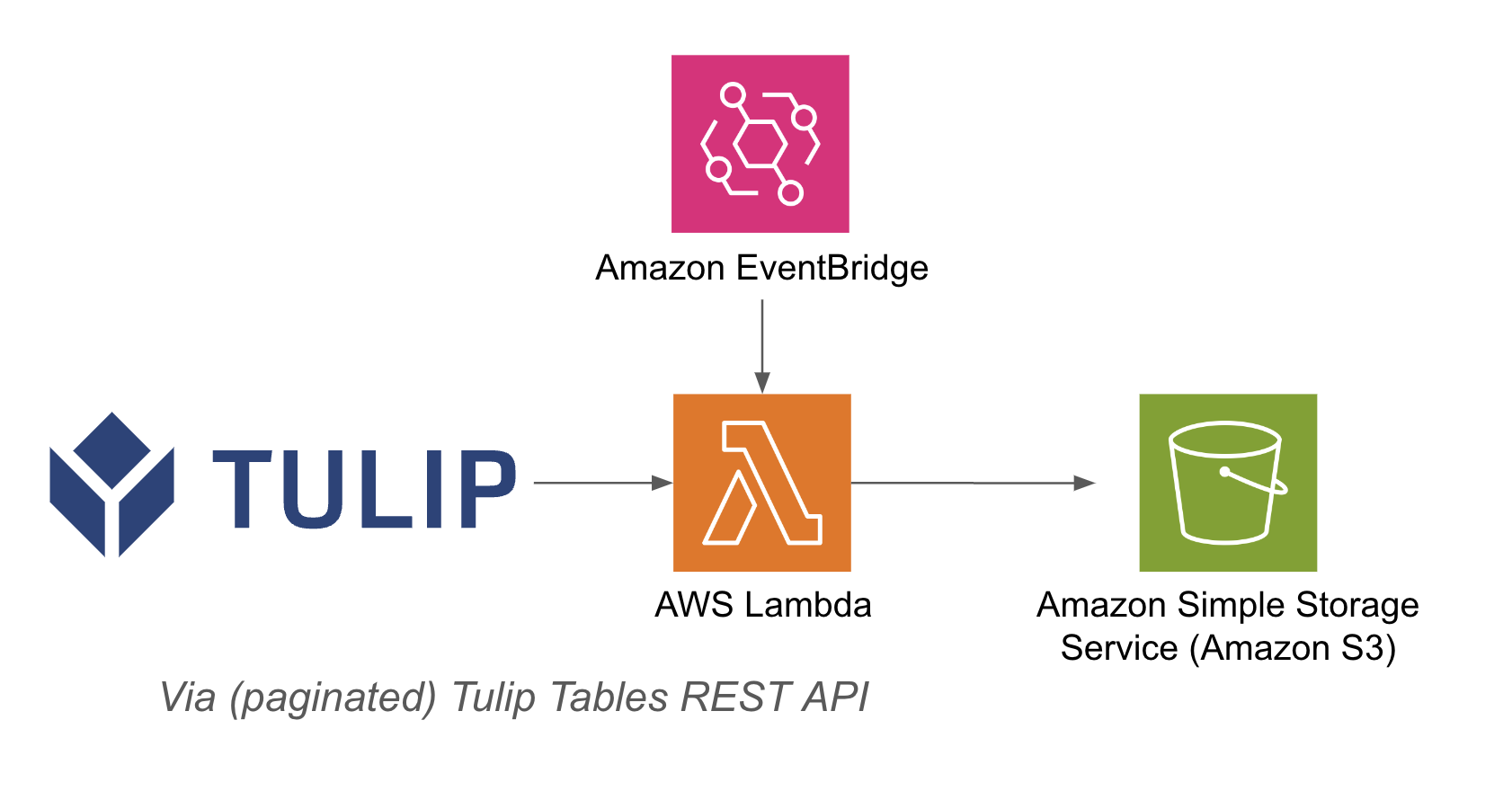
Configurazione
Questo esempio di integrazione richiede quanto segue:
- Uso dell'API di Tulip Tables (ottenere la chiave e il segreto dell'API nelle impostazioni dell'account).
- Tabella Tulip (ottenere l'ID univoco della tabella)
Passi di alto livello: 1. Creare una funzione AWS Lambda con il relativo trigger (API Gateway, Event Bridge Timer, ecc.) 2. Assicurarsi che i dati della tabella Tulip vengano recuperati con l'esempio seguente``pythonimport jsonimport awswrangler as wrimport boto3from datetime import datetimeimport pandas as pdimport requestsimport os
# Ottenere il timestamp corrente per i nomi unici dei file
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
bucket = os.getenv('bucket_name')
# Funzione per convertire i dizionari in stringhe
def dict_to_str(cella): if isinstance(cella, dict): return str(cella) return cella
def query_table(table_id, base_url, api_header): offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+funzione, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row: row.apply(dict_to_str), axis=1) return df
# creare una funzione
def write_to_s3(row, base_url, api_header, bucket): table = row['label'] id = row['id'] df = query_table(id, base_url, api_header)
path = f's3://{bucket}/{timestamp}/{table}.csv'# Scrivere DataFrame su S3 come CSVwr.s3.to_csv( df=df, path=path, index=False)print(f "Scritta {tabella} a {path}")return f "Scritta {tabella} a {path}"
def lambda_handler(event, context): api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) table_names = pd.DataFrame(r.json())
# interroga la tabella functiontable_names.apply(lambda row: write_to_s3(row, base_url, api_header, bucket), axis=1)return { 'statusCode': 200, 'body': json.dumps('wrote to s3!')}
## Casi d'uso e passi successivi
Una volta finalizzata l'integrazione con lambda, è possibile analizzare facilmente i dati con un notebook sagemaker, QuickSight o una serie di altri strumenti.
**1. Previsione dei difetti -** Identificare i difetti di produzione prima che si verifichino e aumentare la qualità al primo colpo - Identificare i principali fattori di produzione della qualità per implementare i miglioramenti.
**2. Ottimizzazione dei costi della qualità -** Identificare le opportunità di ottimizzare il design del prodotto senza impattare sulla soddisfazione del cliente.
**3. Ottimizzazione dell'energia di produzione -** Identificare le leve di produzione per ottimizzare il consumo energetico.
**4. Previsione e ottimizzazione delle consegne e della pianificazione -** Ottimizzare il programma di produzione in base alla domanda dei clienti e al programma degli ordini in tempo reale**.**
**5. Benchmarking globale di macchine e linee:** benchmark di macchine o attrezzature simili con normalizzazione**.**
**6. Gestione delle prestazioni digitali a livello globale/regionale:** dati consolidati per creare cruscotti in tempo reale**.**