
Scopo
Il Widget di input vocale Input Widget lavora insieme a tutti gli altri input per consentire agli utenti di inserire dati nelle applicazioni Tulip. In molti ambienti di produzione l'inserimento da tastiera è considerato poco pratico o semplicemente troppo lento. Con il widget Speech-to-text, gli utenti possono descrivere il problema che stanno riscontrando e questo verrà automaticamente trascritto. 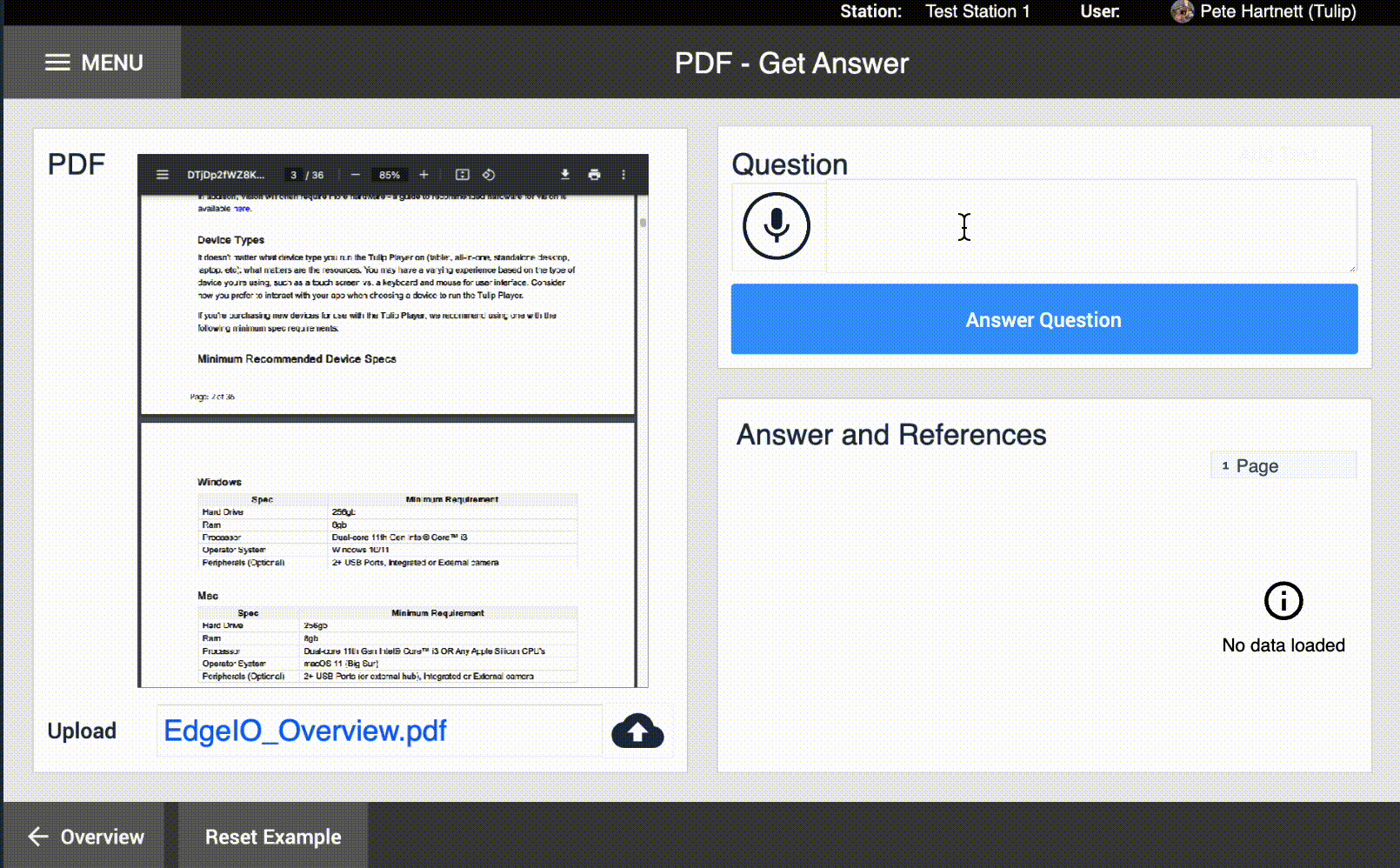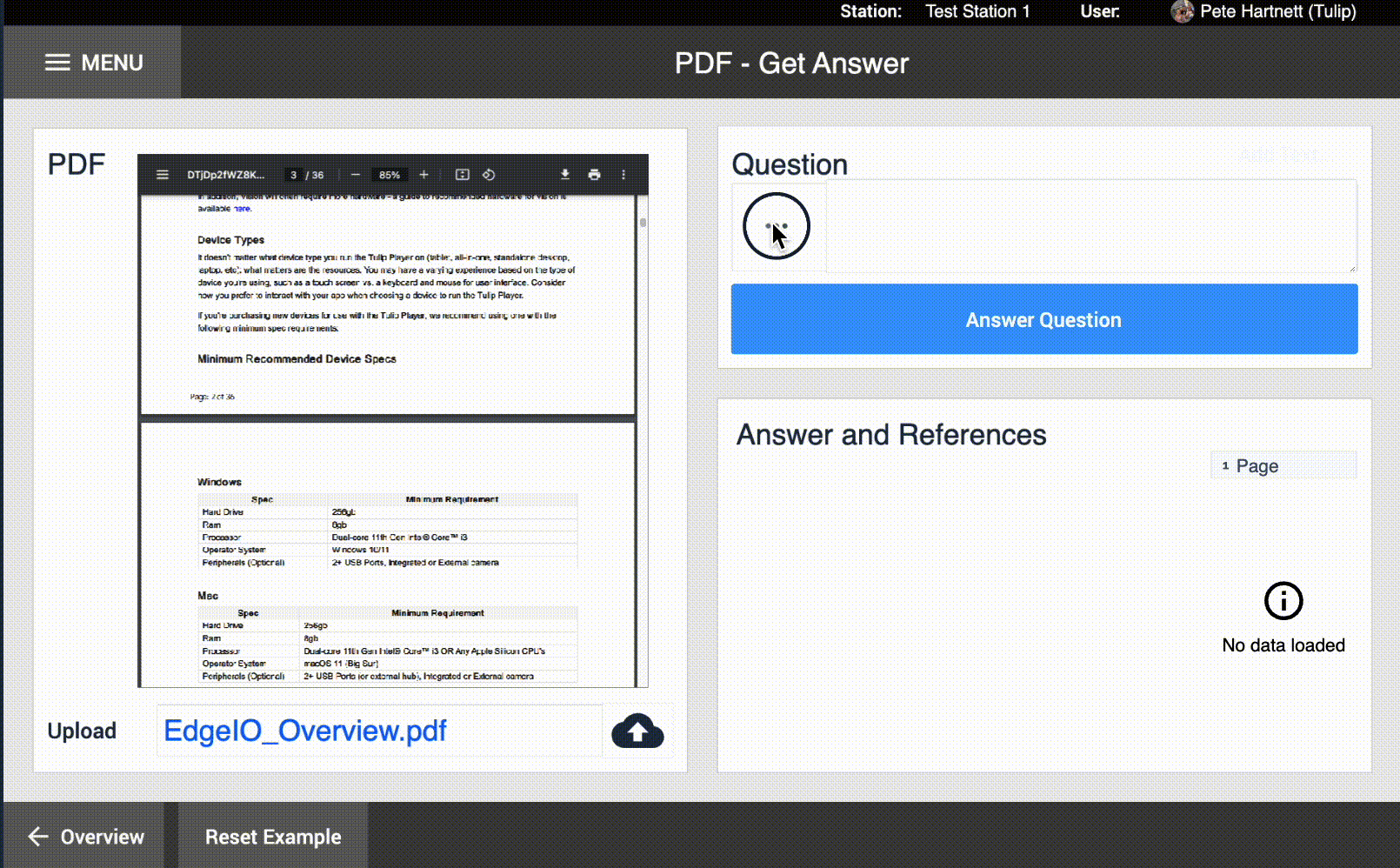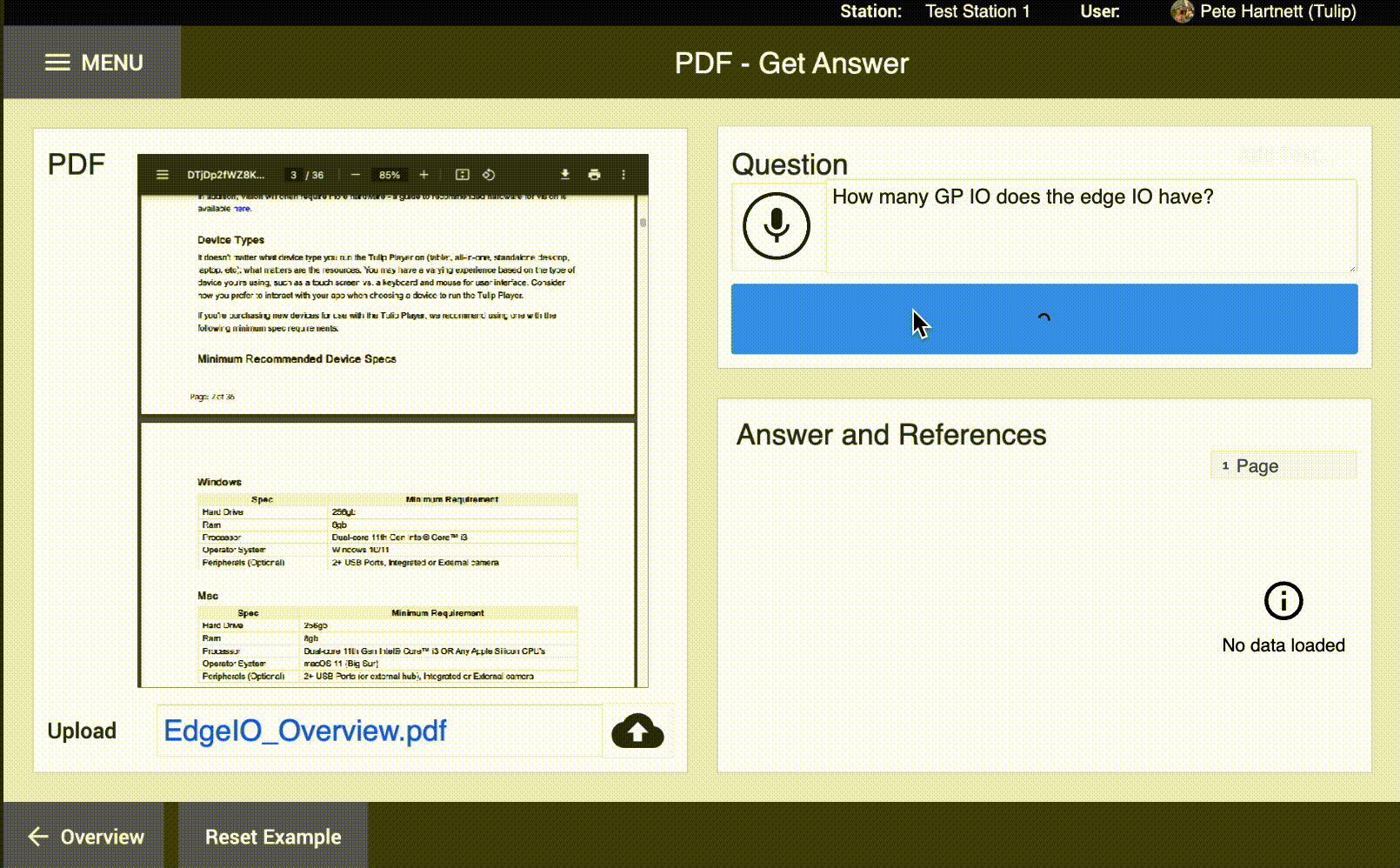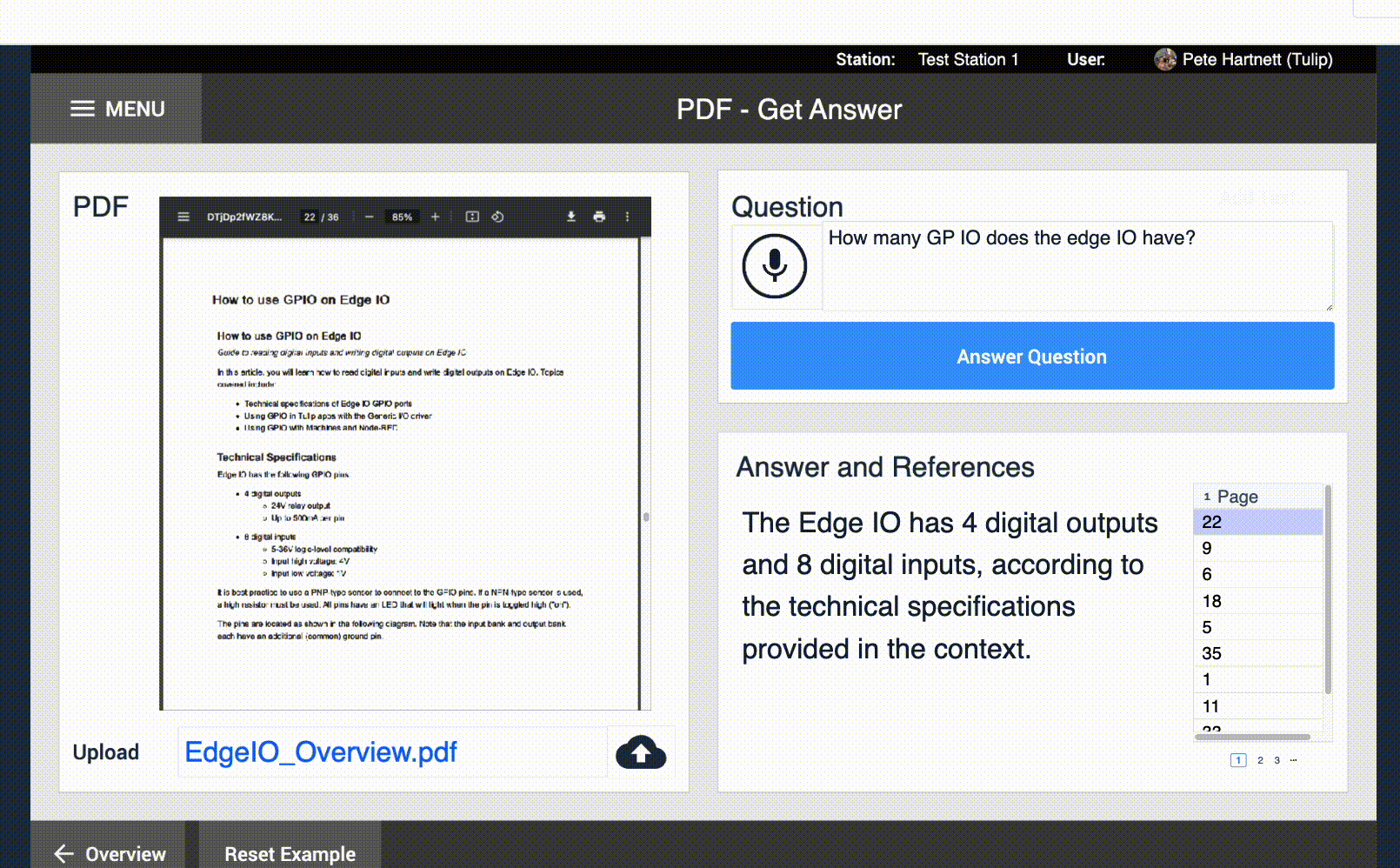 {Altezza="" Larghezza=""}
{Altezza="" Larghezza=""}
Casi d'uso esemplificativi
Se combinato con altre azioni AI Trigger, il widget Speech-to-text può essere utilizzato per cambiare radicalmente l'esperienza dell'utente nell'interazione con i vostri sistemi e processi.
Alcuni esempi di casi d'uso sono:* Consentire agli utenti di porre domande a un "esperto" di intelligenza artificiale. Eliminare la necessità di richiedere l'assistenza di quell'unico dipendente in grado di rispondere a qualsiasi domanda, consentendo agli utenti di porre domande direttamente al database dei difetti passati. La raccolta di informazioni significative da parte degli utenti che devono scrivere o digitare manualmente i loro risultati è una ricetta per ottenere informazioni inutili. Semplificate la raccolta dei dati in modo che possano essere raccolti con la stessa velocità con cui vengono spiegati.* Guidate gli utenti verso la risorsa giusta. Spesso metà della battaglia in un ruolo è capire chi è la persona o il reparto giusto per sollevare un problema. Combinate l'input Speech-to-text con il trigger Classify per determinare la risorsa giusta a cui indirizzare il feedback.
Come fare
Mappatura delle variabili - Il widget Parlato-testo, come qualsiasi altro input, deve essere mappato su una variabile di testo. Quando il discorso dell'utente è stato elaborato, questa variabile verrà popolata con l'input trascritto dall'utente. 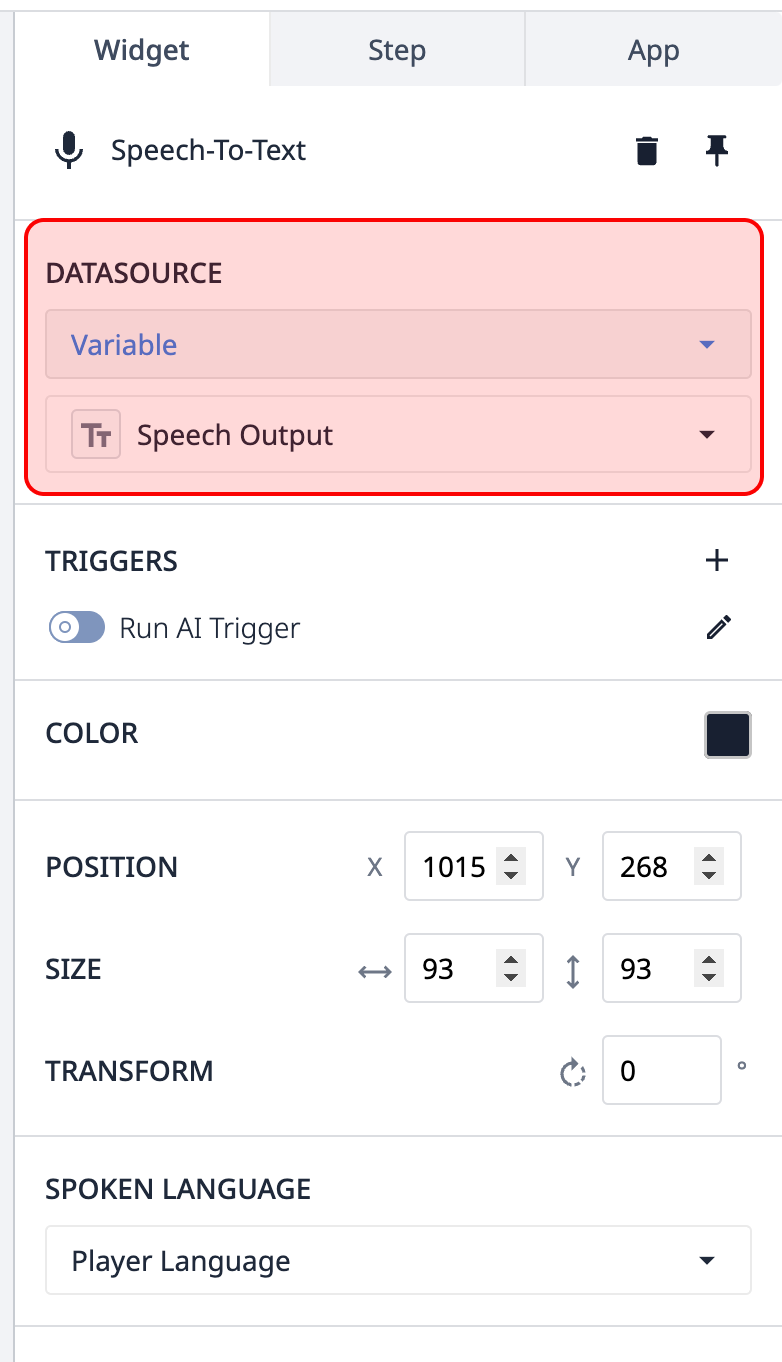
Trigger - L'input speech-to-text può eseguire automaticamente un trigger quando l'input dell'utente è stato trascritto. Questo può essere usato per archiviare automaticamente i dati, eseguire altre azioni copilota e altro ancora.
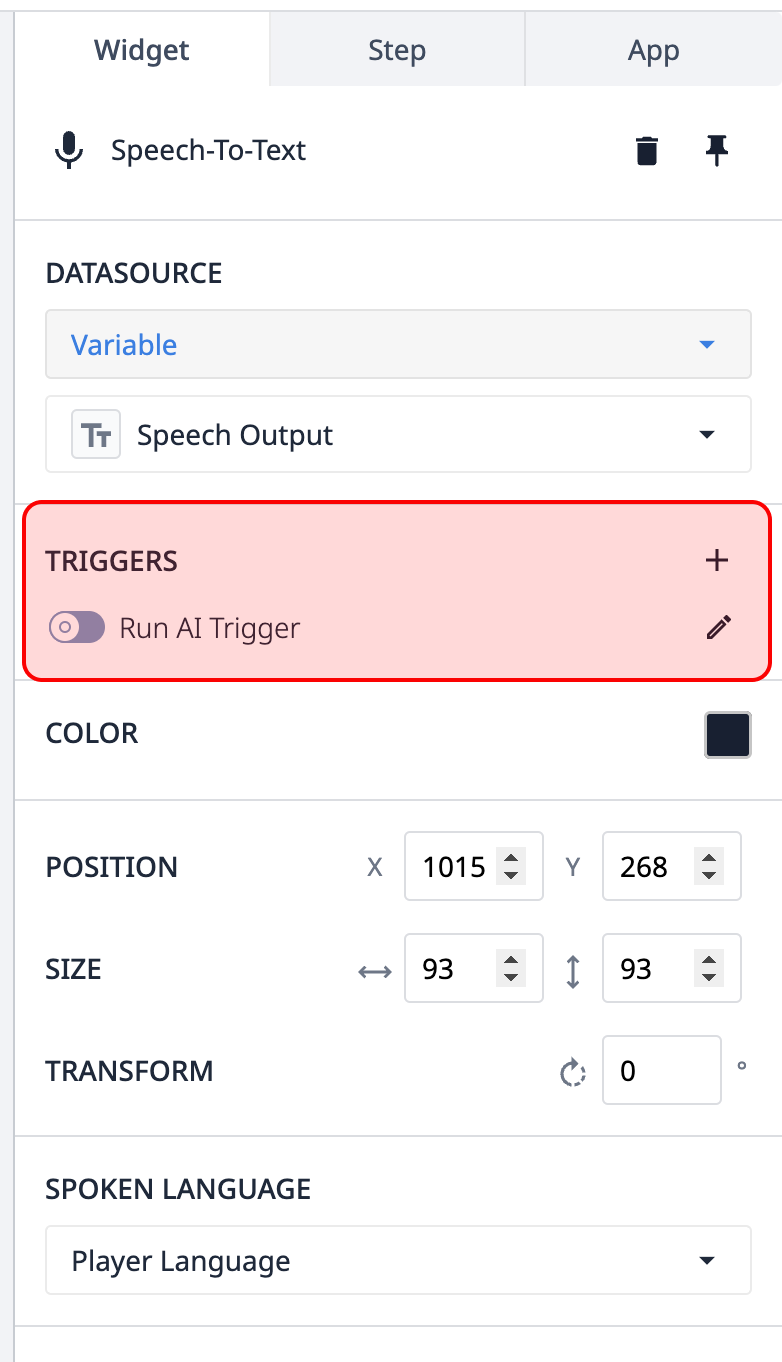 {Altezza="" Larghezza="250"}
{Altezza="" Larghezza="250"}
Lingua parlata - La lingua parlata sarà quella impostata nel player per l'utente connesso, ma può essere annullata manualmente se si preferisce questo comportamento. 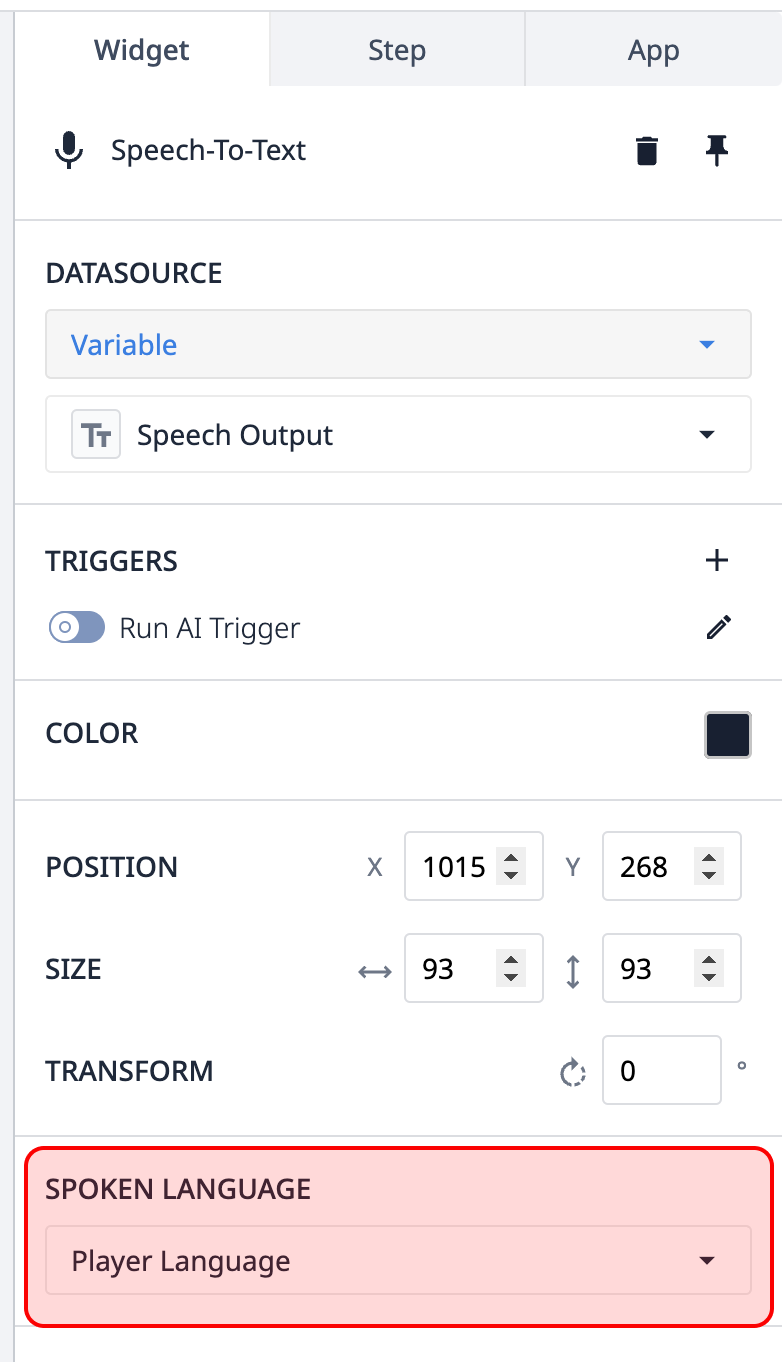
Limiti
Limits are subject to change.
Attualmente esistono i seguenti limiti per gli input speech-to-text. Questi limiti sono tracciati a livello di istanza. In caso di superamento di questi limiti, l'input speech-to-text potrebbe non trascrivere l'input dell'utente.Lunghezza massima della registrazione: 30 secondiLimite mensile: 5.000 richieste/meseLimite di frequenza: 10 richieste/minuto