
Interrogare le tabelle di Tulip con uno script ETL Glue per semplificare lo spostamento dei dati da Tulip a Redshift (o altri cloud di dati)
Scopo
Questo script fornisce un semplice punto di partenza per interrogare i dati sulle tabelle Tulip e spostarli su Redshift o altri Data Warehouse.
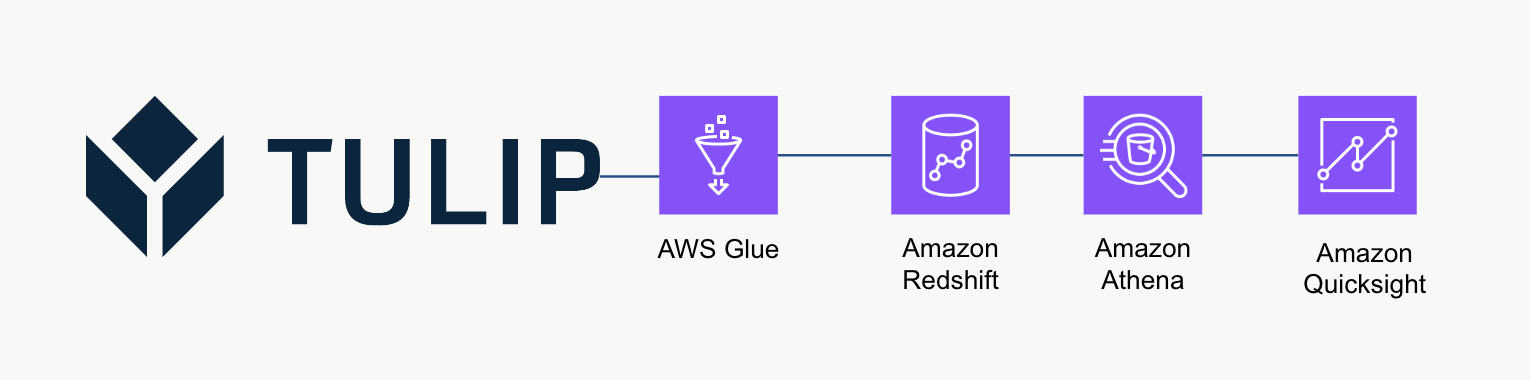
Architettura di alto livello
Questa architettura di alto livello può essere utilizzata per interrogare i dati dalle API delle tabelle di Tulip e poi salvarli su Redshift per ulteriori analisi ed elaborazioni.
Script di esempio
Lo script di esempio qui sotto mostra come interrogare una singola tabella Tulp con Glue ETL (Python Powershell) e poi scrivere su Redshift. NOTA: Per i casi di produzione scalata, si consiglia di scrivere su un bucket S3 temporaneo e poi copiare il contenuto del bucket su S3. Inoltre, le credenziali vengono salvate tramite AWS Secrets Manager.
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create\_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table\_id = 'aKzvoscgHCyd2CRu3\_DEFAULT' def get\_secret(nome\_segreto, nome\_regione): # Crea un client di Secrets Manager session = boto3.session.Session() client = session.client( service\_name='secretsmanager', region\_name=nome\_regione ) try: get\_secret\_value\_response = client.get\_secret\_value( SecretId=nome\_segreto ) except ClientError as e: # Per un elenco delle eccezioni lanciate, vedere # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API\_GetSecretValue.html raise e return json.loads(get\_secret\_value\_response['SecretString'])
redshift\_credentials = get\_secret(secret\_name='tulip\_redshift', region\_name='us-east-1') api\_credentials = get\_secret(secret\_name='[INSTANCE].tulip.co-API-KEY', region\_name='us-east-1')
# creare il motore SQL
url = URL.create( drivername='postgresql', host=redshift\_credentials['host'], port=redshift\_credentials['port'], database=redshift\_credentials['dbname'], username=redshift\_credentials['username'], password=redshift\_credentials['password'] ) engine = sa.create\_engine(url)
header = {'Authorization' : api\_credentials['auth\_header']} base\_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+funzione, headers=intestazione) length = len(r.json()) df\_append = pd.DataFrame(r.json()) df = pd.concat([df, df\_append], axis=0)
# catturare la data e l'ora
now = datetime.now() df['datetime\_updated'] = now
# scrivere su Redshift
df.to\_sql('station\_activity\_from\_glue', engine, schema='product\_growth', index=False,if\_exists='replace')
Considerazioni sulla scala
Considerare l'utilizzo di S3 come storage temporaneo intermedio per poi copiare i dati da S3 a Redshift invece di scriverli direttamente su Redshift. Questo può essere più efficiente dal punto di vista computazionale.
Inoltre, è possibile utilizzare i metadati per scrivere tutte le tabelle Tulip in un Data Warehouse invece di tabelle Tulip singole.
Infine, questo esempio di script sovrascrive ogni volta l'intera tabella. Un metodo più efficiente sarebbe quello di aggiornare le righe modificate dall'ultimo aggiornamento o dall'ultima query.
Passi successivi
Per ulteriori informazioni, consultate l'Amazon Well-Architected Framework. Si tratta di un'ottima risorsa per comprendere i metodi ottimali per i flussi di dati e le integrazioni.