
Semplificare il reperimento dei dati da Tulip ad AWS per maggiori opportunità di analisi e integrazione.
Scopo
Questa guida spiega passo per passo come recuperare i dati delle tabelle Tulip su AWS tramite una funzione Lambda.
La funzione Lambda può essere attivata da una serie di risorse, come i timer di Event Bridge o un API Gateway.
Di seguito è riportato un esempio di architettura:
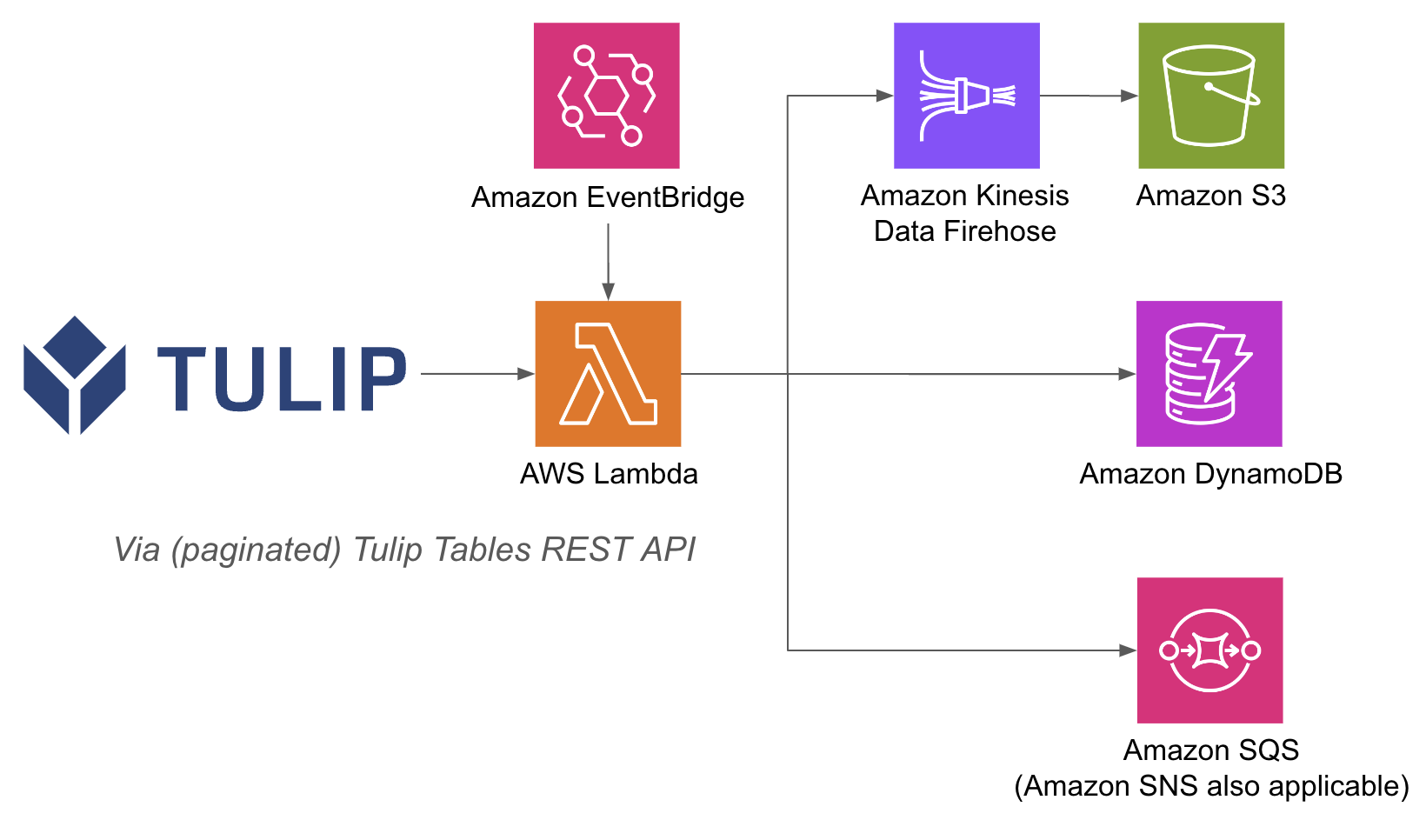
L'esecuzione di operazioni AWS all'interno di una funzione lambda può essere più semplice, perché con le funzioni API Gateway e Lambda non è necessario autenticare i database con nome utente e password sul lato Tulip; si può fare affidamento sui metodi di autenticazione IAM all'interno di AWS. Questo semplifica anche l'utilizzo di altri servizi AWS come Redshift, DynamoDB e altri ancora.
Configurazione
Questo esempio di integrazione richiede quanto segue:
- Uso dell'API Tulip Tables (ottenere la chiave e il segreto dell'API nelle impostazioni dell'account).
- Tulip Table (ottenere l'ID univoco della tabella)
Passi di alto livello: 1. Creare una funzione AWS Lambda con il trigger pertinente (API Gateway, Event Bridge Timer, ecc.) 2. Recuperare i dati della tabella Tulip con i dati di Tulip Tables. Recuperare i dati della tabella Tulip con l'esempio seguente ```python import json import pandas as pd import numpy as np import requests
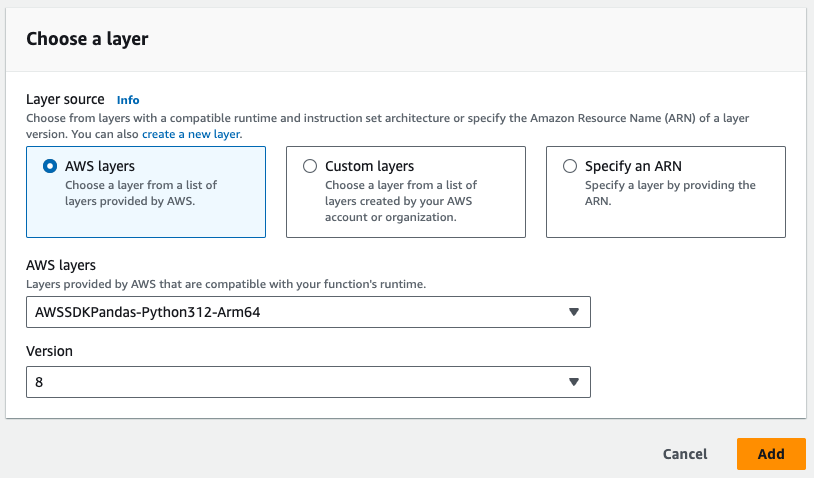
# NOTA il livello pandas da AWS dovrà essere
# essere aggiunto alla funzione Lambda
def lambda_handler(event, context): auth_header = OBTAIN FROM API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df.shape # questo aggiunge 100 record a un dataframe e può essere usato per S3, Firehose, ecc. # usare la variabile dati per scrivere su S3, Firehose,
# database e altro ancora.
- Il trigger può essere eseguito con un timer o attivato tramite un URL.
- Si noti il livello Pandas richiesto nell'immagine qui sotto
- Infine, aggiungere le integrazioni necessarie. È possibile scrivere i dati su un database, S3 o un servizio di notifica dalle funzioni lambda.
Casi d'uso e passi successivi
Una volta finalizzata l'integrazione con lambda, è possibile analizzare facilmente i dati con un notebook sagemaker, QuickSight o una serie di altri strumenti.
1. Previsione dei difetti- Individuare i difetti di produzione prima che si verifichino e aumentare la qualità al primo colpo - Individuare i principali fattori di produzione della qualità per implementare i miglioramenti.
2. Ottimizzazione dei costi della qualità- Identificare le opportunità di ottimizzare la progettazione dei prodotti senza incidere sulla soddisfazione dei clienti.
3. Ottimizzazione dell'energia di produzione- Identificare le leve di produzione per ottimizzare il consumo energetico.
4. Previsione e ottimizzazione delle consegne e della pianificazione- Ottimizzare il programma di produzione in base alla domanda dei clienti e al calendario degli ordini in tempo reale.
5. Benchmarking globale di macchine e linee- Benchmarking di macchine o attrezzature simili con normalizzazione.
6. Gestione delle prestazioni digitali globali/regionali- Dati consolidati per creare cruscotti in tempo reale.