
Przepytywanie tabel Tulip za pomocą skryptu Glue ETL w celu uproszczenia przenoszenia danych z Tulip do Redshift (lub innych chmur danych)
Cel
Skrypt ten stanowi prosty punkt wyjścia do odpytywania danych w tabelach Tulip i przenoszenia ich do Redshift lub innych hurtowni danych.
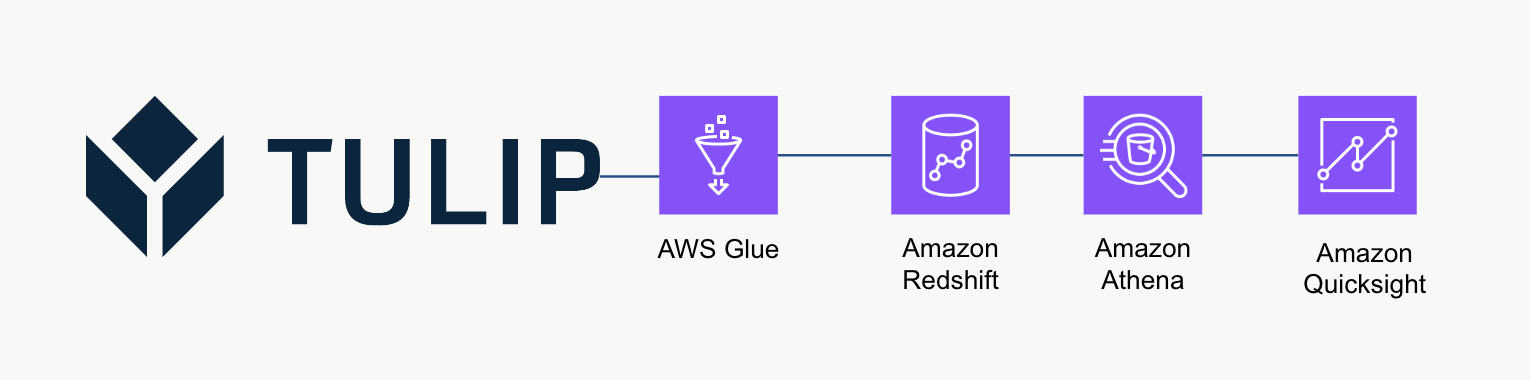
Architektura wysokiego poziomu
Ta wysokopoziomowa architektura może być używana do odpytywania danych z interfejsu API Tulip Tables, a następnie zapisywania ich w Redshift w celu dalszej analizy i przetwarzania.
Przykładowy skrypt
Poniższy przykładowy skrypt pokazuje, jak odpytywać pojedynczą tabelę Tulp za pomocą Glue ETL (Python Powershell), a następnie zapisywać dane w Redshift. UWAGA: W przypadku skalowanych przypadków użycia produkcyjnego zaleca się zamiast tego zapis do tymczasowego bucketu S3, a następnie skopiowanie zawartości bucketu do S3. Dodatkowo poświadczenia są zapisywane za pośrednictwem AWS Secrets Manager.
``python
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table_id = 'aKzvoscgHCyd2CRu3_DEFAULT' def get_secret(secret_name, region_name): # Create a Secrets Manager client session = boto3.session.Session() client = session.client( service_name='secretsmanager', region_name=region_name ) try: get_secret_value_response = client.get_secret_value( SecretId=secret_name ) except ClientError as e: # Aby uzyskać listę wyjątków, zobacz # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API_GetSecretValue.html raise e return json.loads(get_secret_value_response['SecretString'])
redshift_credentials = get_secret(secret_name='tulip_redshift', region_name='us-east-1') api_credentials = get_secret(secret_name='[INSTANCE].tulip.co-API-KEY', region_name='us-east-1')
# budowanie silnika SQL
url = URL.create( drivername='postgresql', host=redshift_credentials['host'], port=redshift_credentials['port'], database=redshift_credentials['dbname'], username=redshift_credentials['username'], password=redshift_credentials['password'] ) engine = sa.create_engine(url)
header = {'Authorization' : api_credentials['auth_header']} base_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0)
# przechwytywanie znacznika daty i czasu
now = datetime.now() df['datetime_updated'] = now
# zapis do Redshift
df.to_sql('station_activity_from_glue', engine, schema='product_growth', index=False,if_exists='replace')
## Rozważania dotyczące skali
Warto rozważyć użycie S3 jako pośredniej tymczasowej pamięci masowej, aby następnie skopiować dane z S3 do Redshift zamiast zapisywać je bezpośrednio w Redshift. Może to być bardziej wydajne obliczeniowo.
Ponadto można również użyć metadanych do zapisania wszystkich tabel Tulip Tables w hurtowni danych zamiast jednorazowych tabel Tulip Tables
Wreszcie, ten przykładowy skrypt za każdym razem nadpisuje całą tabelę. Bardziej wydajną metodą byłaby aktualizacja wierszy zmodyfikowanych od ostatniej aktualizacji lub zapytania.
## Dalsze kroki
Aby uzyskać więcej informacji, zapoznaj się z [*Amazon Well-Architected Framework*](https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/index.en.html). Jest to świetne źródło wiedzy na temat optymalnych metod przepływu danych i integracji