
Запрос к таблицам Tulip с помощью сценария ETL Glue для упрощения переноса данных из Tulip в Redshift (или другие облака данных).
Цель
Этот сценарий предоставляет простую отправную точку для запроса данных в таблицах Tulip и перемещения их в Redshift или другие хранилища данных.
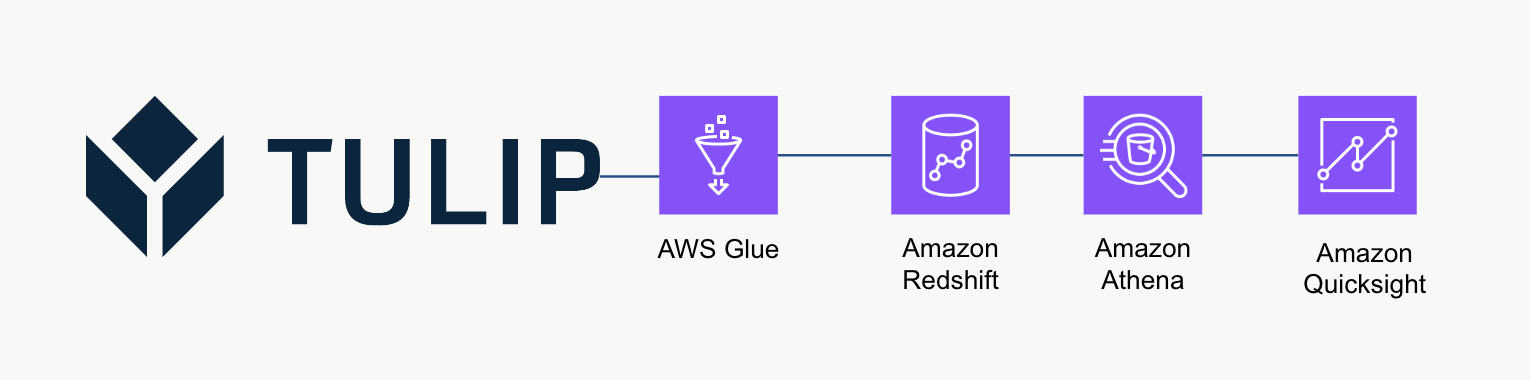
Архитектура высокого уровня
Эта высокоуровневая архитектура может быть использована для запроса данных из Tulip's Tables API и последующего сохранения в Redshift для дальнейшей аналитики и обработки.
Пример сценария
Пример сценария ниже показывает, как запросить одну таблицу Tulp с помощью Glue ETL (Python Powershell) и затем записать в Redshift. ПРИМЕЧАНИЕ: Для масштабных производственных случаев рекомендуется записывать данные во временное ведро S3, а затем копировать содержимое ведра в S3. Кроме того, учетные данные сохраняются через AWS Secrets Manager.
``python
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table_id = 'aKzvoscgHCyd2CRu3_DEFAULT' def get_secret(secret_name, region_name): # Создание клиента менеджера секретов session = boto3.session.Session() client = session.client( service_name='secretsmanager', region_name=region_name ) try: get_secret_value_response = client.get_secret_value( SecretId=secret_name ) except ClientError as e: # Список возникающих исключений см. на # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API_GetSecretValue.html raise e return json.loads(get_secret_value_response['SecretString'])
redshift_credentials = get_secret(secret_name='tulip_redshift', region_name='us-east-1') api_credentials = get_secret(secret_name='[INSTANCE].tulip.co-API-KEY', region_name='us-east-1')
# создайте SQL-движок
url = URL.create( drivername='postgresql', host=redshift_credentials['host'], port=redshift_credentials['port'], database=redshift_credentials['dbname'], username=redshift_credentials['username'], password=redshift_credentials['password'] ) engine = sa.create_engine(url)
header = {'Authorization' : api_credentials['auth_header']} base_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0)
# захватить метку времени
now = datetime.now() df['datetime_updated'] = now
# запись в Redshift
df.to_sql('station_activity_from_glue', engine, schema='product_growth', index=False,if_exists='replace')
## Соображения по масштабированию
Рассмотрите возможность использования S3 в качестве промежуточного временного хранилища, чтобы затем копировать данные из S3 в Redshift вместо того, чтобы записывать их непосредственно в Redshift. Это может быть более эффективным с точки зрения вычислений.
Кроме того, можно использовать метаданные для записи всех таблиц Tulip Tables в хранилище данных, а не отдельных таблиц Tulip Tables.
Наконец, в этом примере сценарий каждый раз перезаписывает всю таблицу. Более эффективным методом будет обновление строк, измененных с момента последнего обновления или запроса.
## Следующие шаги
Для дальнейшего чтения ознакомьтесь с [*Amazon Well-Architected Framework*](https://wa.aws.amazon.com/wellarchitected/2020-07-02T19-33-23/index.en.html). Это отличный ресурс для понимания оптимальных методов работы с потоками данных и интеграциями.