
使用 Glue ETL 脚本查询 Tulip 表,简化将数据从 Tulip 转移到 Redshift(或其他数据云)的过程
目的
本脚本为查询 Tulip 表上的数据并将其移动到 Redshift 或其他数据仓库提供了一个简单的起点
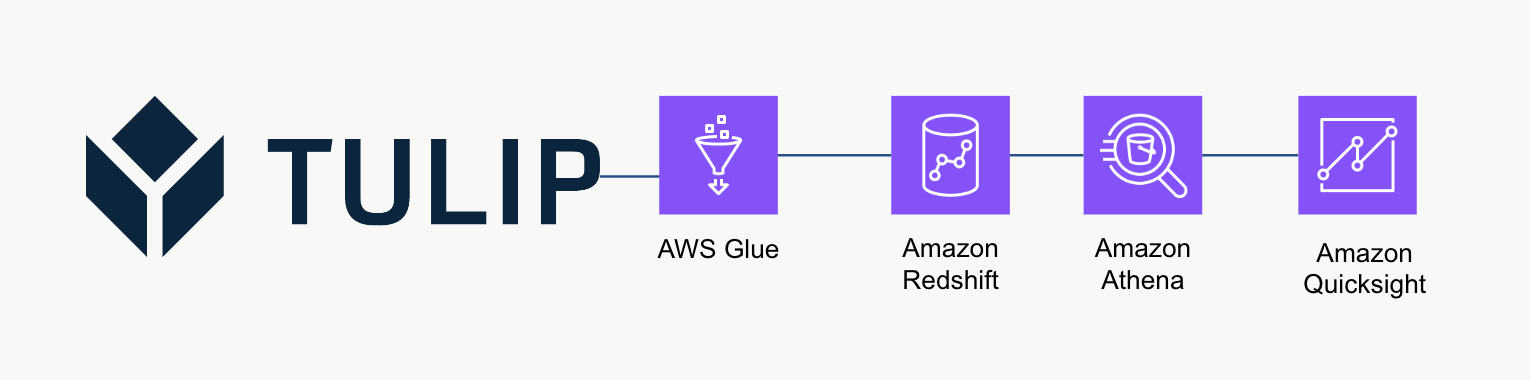
高级架构
此高级架构可用于查询 Tulip 表 API 中的数据,然后将数据保存到 Redshift 以进行进一步分析和处理。
示例脚本
下面的示例脚本展示了如何使用 Glue ETL(Python Powershell)查询单个 Tulp 表,然后写入 Redshift。注意:对于大规模生产用例,建议先写入临时 S3 存储桶,然后将存储桶内容复制到 S3。此外,凭证通过 AWS Secrets Manager 保存。
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create\_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table\_id = 'aKzvoscgHCyd2CRu3\_DEFAULT' def get\_secret(secret\_name, region\_name): # 创建秘密管理器客户端 session = boto3.session.Session() client = session.client( service\_name='secretsmanager', region\_name=region\_name ) try: get\_secret\_value\_response = client.get\_secret\_value( SecretId=secret\_name ) except ClientError as e: # 有关抛出的异常列表,请参阅 # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API\_GetSecretValue.html raise e return json.loads(get\_secret\_value\_response['SecretString'])
redshift\_credentials = get\_secret(secret\_name='tulip\_redshift', region\_name='us-east-1') api\_credentials = get\_secret(secret\_name='[INSTANCE].tulip.coAPI-KEY', region\_name='us-east-1')
# 创建 SQL 引擎
url = URL.create( drivername='postgresql', host=redshift\_credentials['host'], port=redshift\_credentials['port'], database=redshift\_credentials['dbname'], username=redshift\_credentials['username'], password=redshift\_credentials['password'] ) engine = sa.create\_engine(url)
header = {'Authorization' : api\_credentials['auth\_header']} base\_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) length = len(r.json()) df\_append = pd.DataFrame(r.json()) df = pd.concat([df, df\_append], axis=0)
# 捕捉日期时间戳
now = datetime.now() df['datetime\_updated'] = now
# 写入 Redshift
df.to\_sql('station\_activity\_from\_glue', engine, schema='product\_growth', index=False,if\_exists='replace')
规模考虑
考虑使用 S3 作为中间临时存储,然后将数据从 S3 复制到 Redshift,而不是直接写入 Redshift。这样可以提高计算效率。
此外,您还可以使用元数据将所有郁金香表写入数据仓库,而不是一次性写入郁金香表。
最后,这个示例脚本每次都会覆盖整个表。更有效的方法是更新上次更新或查询后修改的行。
下一步
如需进一步阅读,请查看Amazon Well-Architected Framework。这是了解数据流和集成最佳方法的重要资源