
Tulip táblák lekérdezése egy Glue ETL Script segítségével, hogy egyszerűsítse az adatok mozgatását a Tulipból a Redshiftbe (vagy más adatfelhőkbe)
Cél
Ez a szkript egy egyszerű kiindulási pontot biztosít a Tulip táblák adatainak lekérdezéséhez és a Redshiftbe vagy más adattárházakba történő áthelyezéséhez.
Magas szintű architektúra
Ez a magas szintű architektúra használható a Tulip Tables API-ból származó adatok lekérdezésére, majd a Redshiftbe történő mentésére további elemzés és feldolgozás céljából.
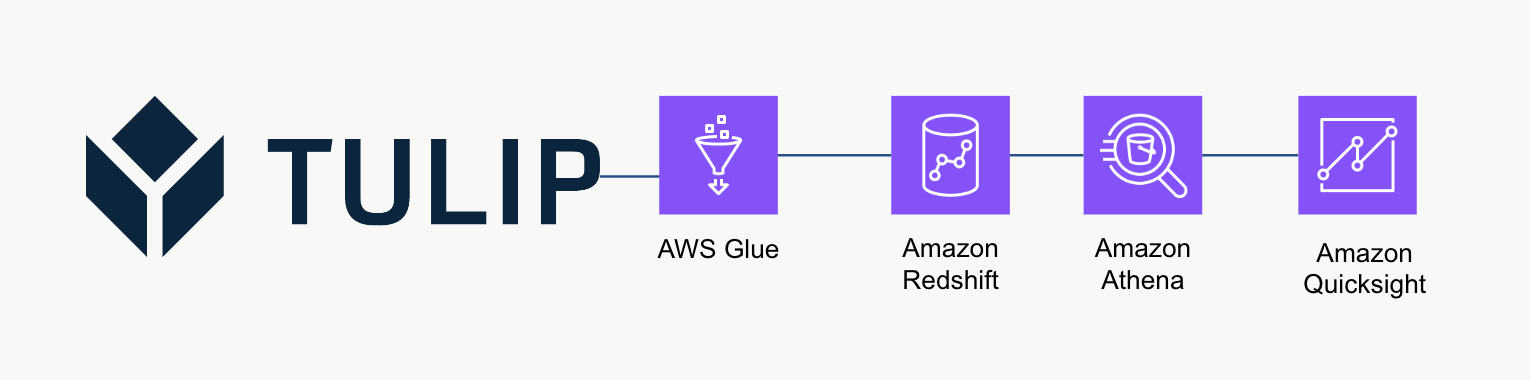
Példa szkript
Az alábbi példaszkript bemutatja, hogyan lehet lekérdezni egyetlen Tulp Table-t a Glue ETL (Python Powershell) segítségével, majd a Redshiftbe írni. MEGJEGYZÉS: A skálázott termelési felhasználási eseteknél ehelyett a vödör tartalmának egy ideiglenes S3 vödörbe való írása, majd S3-ra való másolása ajánlott. Ezenkívül a hitelesítő adatok az AWS Secrets Manager segítségével kerülnek mentésre.
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create\_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table\_id = 'aKzvoscgHCyd2CRu3\_DEFAULT' def get\_secret(secret\_name, region\_name): # Titokkezelő kliens létrehozása session = boto3.session.Session() client = session.client( service\_name='secretsmanager', region\_name=region\_name ) try: get\_secret\_value\_response = client.get\_secret\_value( SecretId=secret\_name ) except ClientError as e: # A dobott kivételek listáját lásd # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API\_GetSecretValue.html raise e return json.loads(get\_secret\_value\_response['SecretString'])
redshift\_credentials = get\_secret(secret\_name='tulip\_redshift', region\_name='us-east-1') api\_credentials = get\_secret(secret\_name='[INSTANCE].tulip.co-API-KEY', region\_name='us-east-1')
# SQL motor létrehozása
url = URL.create( drivername='postgresql', host=redshift\_credentials['host'], port=redshift\_credentials['port'], database=redshift\_credentials['dbname'], username=redshift\_credentials['username'], password=redshift\_credentials['password'] ) engine = sa.create\_engine(url)
header = {'Authorization' : api\_credentials['auth\_header']} base\_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) length = len(r.json()) df\_append = pd.DataFrame(r.json()) df = pd.concat([df, df\_append], axis=0)
# dátum-idő bélyegző rögzítése
now = datetime.now() df['datetime\_updated'] = now
# írás a Redshiftbe
df.to\_sql('station\_activity\_from\_glue', engine, schema='product\_growth', index=False,if\_exists='replace')
Méretezési megfontolások
Fontolja meg az S3 használatát köztes ideiglenes tárolóként, hogy aztán az adatokat az S3-ból a Redshiftbe másolja, ahelyett, hogy közvetlenül a Redshiftbe írná őket. Ez számítási szempontból hatékonyabb lehet.
Ezenkívül metaadatokat is használhat az összes Tulip-tábla adattárházba írásához az egyszeri Tulip-táblák helyett.
Végül ez a példaszkript minden alkalommal felülírja a teljes táblát. Hatékonyabb módszer lenne az utolsó frissítés vagy lekérdezés óta módosított sorok frissítése.
Következő lépések
További olvasmányokért tekintse meg az Amazon Well-Architected Frameworket. Ez egy nagyszerű forrás az adatfolyamok és integrációk optimális módszereinek megértéséhez.