
Consultar tabelas do Tulip com um script ETL Glue para simplificar a transferência de dados do Tulip para o Redshift (ou outras nuvens de dados)
Objetivo
Esse script fornece um ponto de partida simples para consultar dados em tabelas do Tulip e movê-los para o Redshift ou outros Data Warehouses
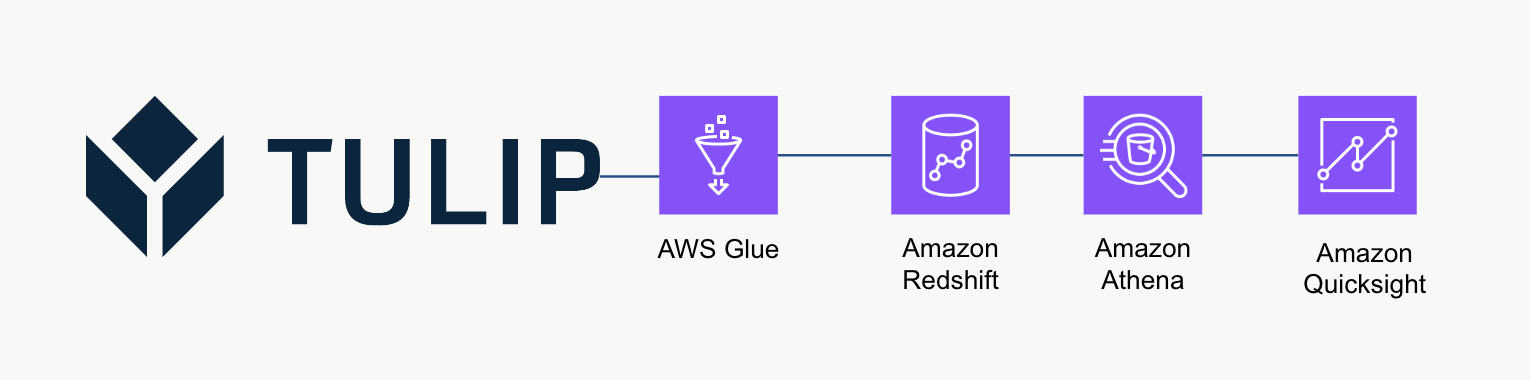
Arquitetura de alto nível
Essa arquitetura de alto nível pode ser usada para consultar dados da API Tables do Tulip e, em seguida, salvos no Redshift para análise e processamento adicionais.
Script de exemplo
O script de exemplo abaixo mostra como consultar uma única tabela do Tulip com o Glue ETL (Python Powershell) e depois gravar no Redshift. OBSERVAÇÃO: para casos de uso de produção em escala, recomenda-se gravar em um bucket temporário do S3 e, em seguida, copiar o conteúdo do bucket para o S3. Além disso, as credenciais são salvas por meio do AWS Secrets Manager.
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create\_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table\_id = 'aKzvoscgHCyd2CRu3\_DEFAULT' def get\_secret(secret\_name, region\_name): # Criar um cliente do Gerenciador de segredos session = boto3.session.Session() client = session.client( service\_name='secretsmanager', region\_name=region\_name ) try: get\_secret\_value\_response = client.get\_secret\_value( SecretId=secret\_name ) except ClientError as e: # Para obter uma lista das exceções lançadas, consulte # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API\_GetSecretValue.html raise e return json.loads(get\_secret\_value\_response['SecretString'])
redshift\_credentials = get\_secret(secret\_name='tulip\_redshift', region\_name='us-east-1') api\_credentials = get\_secret(secret\_name='[INSTANCE].tulip.co-API-KEY', region\_name='us-east-1')
# Criar mecanismo SQL
url = URL.create( drivername='postgresql', host=redshift\_credentials['host'], port=redshift\_credentials['port'], database=redshift\_credentials['dbname'], username=redshift\_credentials['username'], password=redshift\_credentials['password'] ) engine = sa.create\_engine(url)
header = {'Authorization' : api\_credentials['auth\_header']} base\_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) length = len(r.json()) df\_append = pd.DataFrame(r.json()) df = pd.concat([df, df\_append], axis=0)
# capturar registro de data e hora
now = datetime.now() df['datetime\_updated'] = now
# gravar no Redshift
df.to\_sql('station\_activity\_from\_glue', engine, schema='product\_growth', index=False,if\_exists='replace')
Considerações sobre escala
Considere usar o S3 como um armazenamento temporário intermediário para copiar os dados do S3 para o Redshift em vez de gravá-los diretamente no Redshift. Isso pode ser mais eficiente do ponto de vista computacional.
Além disso, você também pode usar metadados para gravar todas as tabelas Tulip em um Data Warehouse, em vez de tabelas Tulip isoladas
Por fim, esse script de exemplo sobrescreve a tabela inteira a cada vez. Um método mais eficiente seria atualizar as linhas modificadas desde a última atualização ou consulta.
Próximas etapas
Para ler mais, consulte o Amazon Well-Architected Framework. Esse é um ótimo recurso para entender os métodos ideais para fluxos de dados e integrações