
Glue ETL 스크립트로 Tulip 테이블을 쿼리하여 Tulip에서 Redshift(또는 다른 데이터 클라우드)로 데이터를 간편하게 이동하기
목적
이 스크립트는 Tulip 테이블에서 데이터를 쿼리하고 Redshift 또는 다른 데이터 웨어하우스로 이동하기 위한 간단한 시작점을 제공합니다.
상위 수준 아키텍처
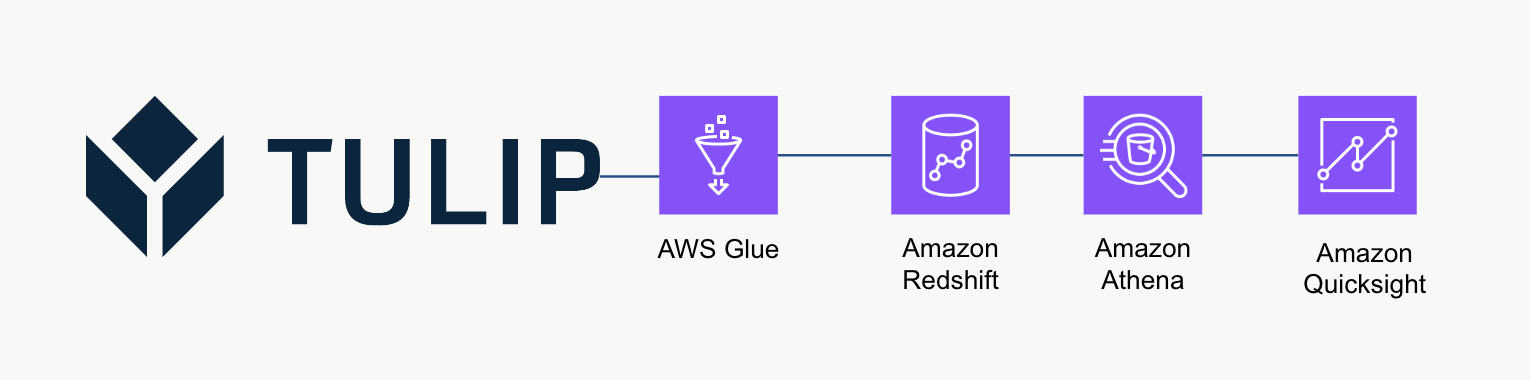
이 하이레벨 아키텍처는 Tulip의 Tables API에서 데이터를 쿼리한 다음 추가 분석 및 처리를 위해 Redshift에 저장하는 데 사용할 수 있습니다.
예제 스크립트
아래 예제 스크립트는 Glue ETL(Python Powershell)을 사용하여 단일 Tulp 테이블을 쿼리한 다음 Redshift에 쓰는 방법을 보여줍니다. 참고: 확장된 프로덕션 사용 사례의 경우, 임시 S3 버킷에 쓴 다음 버킷 콘텐츠를 S3에 복사하는 것이 좋습니다. 또한 자격 증명은 AWS Secrets Manager를 통해 저장됩니다.
import sys임포트 판다를 pd로 임포트 넘피를 np로 임포트 요청을 임포트 제이슨을 임포트 boto3를 botocore.exceptions에서 임포트 ClientError를 sqlalchemy에서 임포트 create\_engine을 sqlalchemy.engine.url로 임포트 sqlalchemy.engine.url에서 임포트 URL을 임포트 psycopg2를 datetime에서 임포트 datetime임포트 logginglogger = logging.getLogger()를 임포트합니다.
table\_id = 'aKzvoscgHCyd2CRu3\_DEFAULT'def get\_secret(secret\_name, region\_name): # 시크릿 매니저 생성 클라이언트 세션 = boto3.session.Session() client = session.client( service\_name='secretsmanager', region\_name=region\_name ) try: get\_secret\_value\_response = client.get\_secret\_value( SecretId=secret\_name ) except ClientError as e.: # 발생된 예외 목록은 # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API\_GetSecretValue.html 를 참조하세요. return json.loads(get\_secret\_value\_response['SecretString'])
redshift\_credentials = get\_secret(secret\_name='tulip\_redshift', region\_name='us-east-1')api\_credentials = get\_secret(secret\_name='[INSTANCE].tulip.co-API-KEY', region\_name='us-east-1')
# SQL 엔진 빌드
url = URL.create(drivername='postgresql', host=redshift\_credentials['host'],port=redshift\_credentials['port'],database=redshift\_credentials['dbname'], username=redshift\_credentials['username'], password=redshift\_credentials['password'] )engine = sa.create\_engine(url)
header = {'권한 부여' : api\_credentials['auth\_header']}base\_url = 'https://william.tulip.co/api/v3'
offset = 0function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all'r = requests.get(base\_url+function, headers=header)df = pd.DataFrame(r.json())length = len(r.json()))
length > 0: offset += 100 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) length = len(r.json()) df\_append = pd.DataFrame(r.json()) df = pd.concat([df, df\_append], axis=0)
# 날짜-시간 스탬프 캡처
now = datetime.now()df['datetime\_updated'] = now
# Redshift에 쓰기
df.to\_sql('station\_activity\_from\_glue', engine, schema='product\_growth', index=False,if\_exists='replace')
규모 고려 사항
데이터를 Redshift에 직접 쓰는 대신 S3를 중간 임시 저장소로 사용하여 S3에서 Redshift로 복사하는 것을 고려하세요. 이렇게 하면 계산상 더 효율적일 수 있습니다.
또한 메타데이터를 사용하여 일회성 Tulip 테이블 대신 모든 Tulip 테이블을 데이터 웨어하우스에 쓸 수도 있습니다.
마지막으로, 이 예제 스크립트는 매번 전체 테이블을 덮어씁니다. 더 효율적인 방법은 마지막 업데이트 또는 쿼리 이후 수정된 행을 업데이트하는 것입니다.
다음 단계
더 자세히 알아보려면 Amazon Well-Architected 프레임워크를 확인하세요. 데이터 흐름과 통합을 위한 최적의 방법을 이해하는 데 유용한 리소스입니다.