
Consulta de tablas de Tulip con un script ETL de Glue para simplificar el traslado de datos de Tulip a Redshift (u otras nubes de datos).
Propósito
Este script proporciona un punto de partida simple para consultar datos en Tulip Tables y moverlos a Redshift u otros Data Warehouses
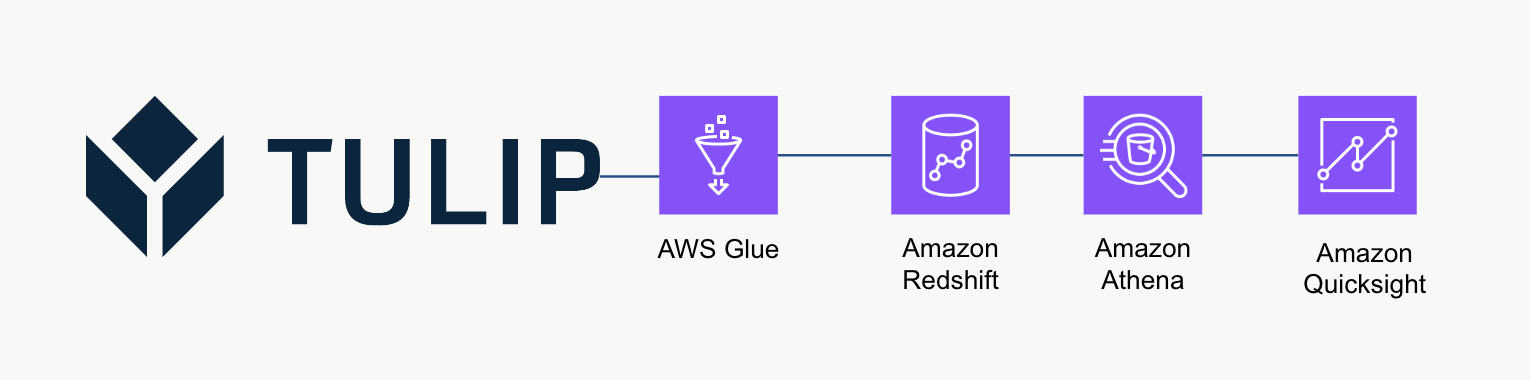
Arquitectura de alto nivel
Esta arquitectura de alto nivel se puede utilizar para consultar datos de la API de Tulip Tables y luego guardarlos en Redshift para su posterior análisis y procesamiento.
Script de ejemplo
El siguiente script de ejemplo muestra cómo consultar una única tabla de Tulp con Glue ETL (Python Powershell) y luego escribir en Redshift. NOTA: Para casos de uso de producción a escala, se recomienda escribir en un bucket S3 temporal y luego copiar el contenido del bucket a S3. Además, las credenciales se guardan a través de AWS Secrets Manager.
import sys import pandas as pd import numpy as np import requests import json import boto3 from botocore.exceptions import ClientError from sqlalchemy import create\_engine import sqlalchemy as sa from sqlalchemy.engine.url import URL import psycopg2 from datetime import datetime import logging logger = logging.getLogger()
table\_id = 'aKzvoscgHCyd2CRu3\_DEFAULT' def get\_secret(secret\_name, region\_name): # Crear un cliente del Gestor de Secretos session = boto3.session.Session() client = session.client( service\_name='secretsmanager', region\_name=region\_name ) try: get\_secret\_value\_response = client.get\_secret\_value( SecretId=secret\_name ) except ClientError as e: # Para ver una lista de las excepciones lanzadas, consulte # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API\_GetSecretValue.html raise e return json.loads(get\_secret\_value\_response['SecretString'])
redshift\_credentials = get\_secret(secret\_name='tulip\_redshift', region\_name='us-east-1') api\_credentials = get\_secret(secret\_name='[INSTANCE].tulip.co-API-KEY', region\_name='us-east-1')
# crear motor SQL
url = URL.create( drivername='postgresql', host=redshift\_credentials['host'], port=redshift\_credentials['port'], database=redshift\_credentials['dbname'], username=redshift\_credentials['username'], password=redshift\_credentials['password'] ) engine = sa.create\_engine(url)
header = {'Authorization' : api\_credentials['auth\_header']} base\_url = 'https://william.tulip.co/api/v3'
offset = 0 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json())
while length > 0: offset += 100 function = f'/tables/{table\_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base\_url+function, headers=header) length = len(r.json()) df\_append = pd.DataFrame(r.json()) df = pd.concat([df, df\_append], axis=0)
# capturar la fecha y la hora
now = datetime.now() df['datetime\_updated'] = now
# escribir en Redshift
df.to\_sql('estacion\_actividad\_desde\_pegamento', engine, schema='crecimiento\_producto', index=False,if\_exists='replace')
Consideraciones de escala
Considere la posibilidad de utilizar S3 como almacenamiento temporal intermedio para luego copiar los datos de S3 a Redshift en lugar de escribirlos directamente en Redshift. Esto puede ser más eficiente computacionalmente.
Además, también puede utilizar metadatos para escribir todas las Tulip Tables en un almacén de datos en lugar de Tulip Tables puntuales.
Por último, este script de ejemplo sobrescribe toda la tabla cada vez. Un método más eficiente sería actualizar las filas modificadas desde la última actualización o consulta.
Siguientes pasos
Para más información, consulta el Marco de trabajo bien diseñado de Amazon. Se trata de un gran recurso para comprender los métodos óptimos para los flujos de datos y las integraciones.