
简化从 Tulip 到 AWS S3 的数据提取,以获得更广泛的分析和集成机会
目的
本指南将逐步介绍如何通过 Lambda 函数获取所有 Tulip 表数据并写入 S3 存储桶。
这超出了基本的获取查询,而是对给定实例中的所有表进行迭代;这对于每周一次的 ETL 作业(提取、转换、加载)非常有用。
lambda 函数可通过各种资源触发,如事件桥定时器或 API 网关。
下面列出了一个架构示例: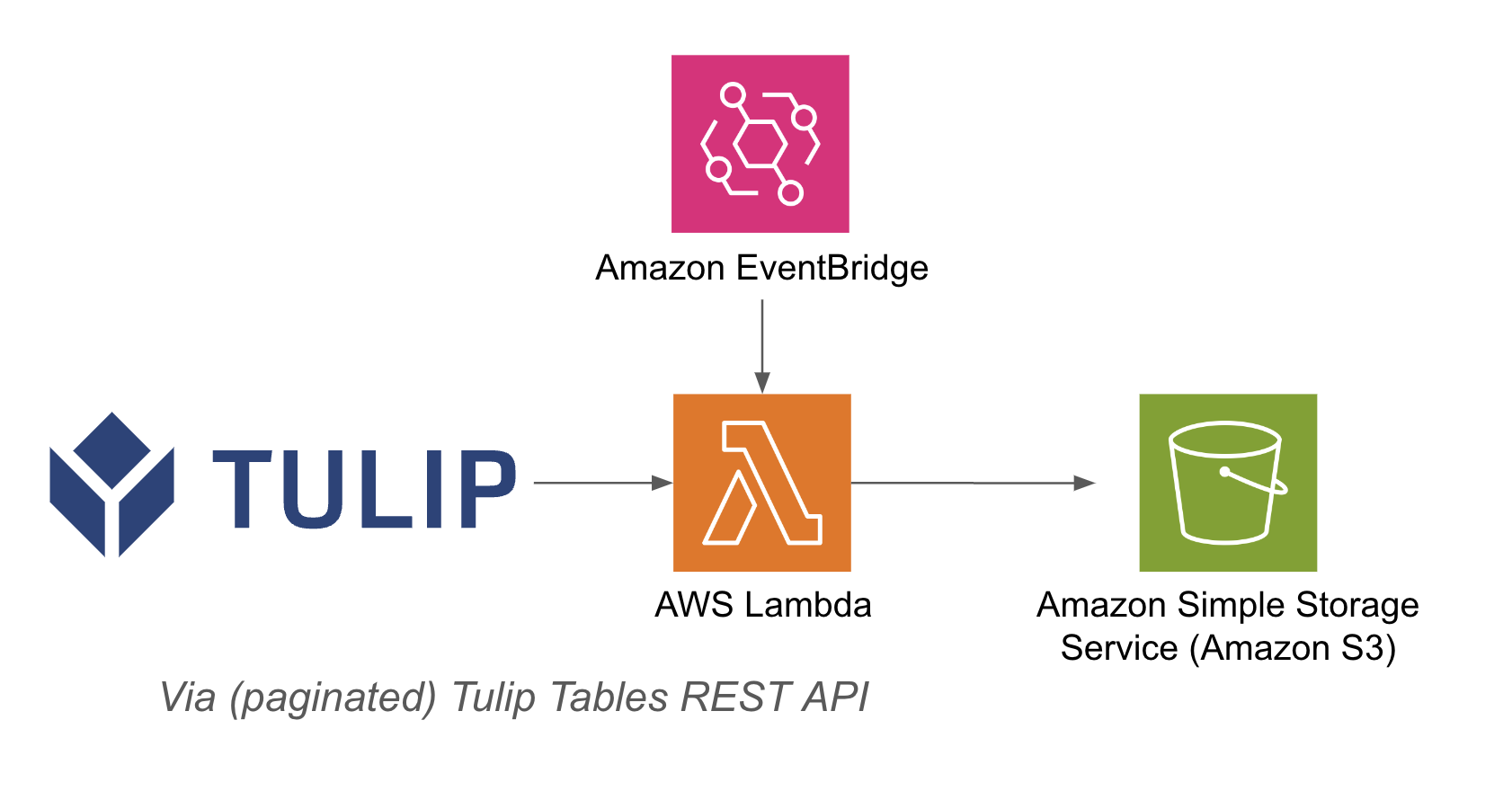 {height="" width="""}
{height="" width="""}
设置
此集成示例需要以下条件:
- 使用郁金香表 API(在账户设置中获取 API 密钥和秘密)
- 郁金香表(获取表唯一 ID
高级步骤:1.使用相关触发器(API Gateway、Event Bridge Timer 等)创建 AWS Lambda 函数2.确保在 AWS Lambda 函数中使用相关触发器3.使用下面的示例获取郁金香表数据```pythonimport jsonimport awswrangler as wrimport boto3from datetime import datetimeimport pandas as pdimport requestsimport os
# 获取唯一文件名的当前时间戳
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
bucket = os.getenv('bucket_name')
# 将字典转换为字符串的函数
def dict_to_str(cell): if isinstance(cell, dict): return str(cell) return cell
def query_table(table_id, base_url, api_header): offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) 长度 = len(r.json()df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row: row.apply(dict_too_str), axis=1) return df
# 创建函数
def write_to_s3(row, base_url, api_header, bucket): table = row['label'] id = row['id'] df = query_table(id, base_url, api_header)
path = f's3://{bucket}/{timestamp}/{table}.csv'# 以 CSV 格式将数据帧写入 S3wr.s3.to_csv( df=df, path=path, index=False)print(f "Wrote {table} to {path}")return f "Wrote {table} to {path}"
def lambda_handler(event, context): api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) table_names = pd.DataFrame(r.json())
# 查询表 functiontable_names.apply(lambda row: write_to_s3(row, base_url, api_header, bucket), axis=1)return { 'statusCode': 200, 'body': json.dumps('wrote to s3!')} ``3.
## 使用案例和下一步
完成与 lambda 的集成后,您可以使用 sagemaker 笔记本、QuickSight 或其他各种工具轻松分析数据。
**1.缺陷预测--**在缺陷发生之前识别生产缺陷,提高首次正确率。
**2.**2.**优化质量成本--**在不影响客户满意度的前提下,确定优化产品设计的机会 3.
**3.生产能源优化--**确定优化能源消耗的生产杠杆 4.
**4.交货和计划预测与优化--**根据客户需求和实时订单计划优化生产计划 5.
**5.全球机器/生产线基准--**对类似机器或设备进行标准化基准**测试** 6.
**6.全球/区域数字化绩效管理--**整合数据,创建实时仪表板