
Упорядочить получение данных из Tulip в AWS S3 для расширения возможностей аналитики и интеграции.
Цель
В этом руководстве пошагово описано, как получить все данные Tulip Tables с помощью функции Lambda и записать их в ведро S3.
Это выходит за рамки базового запроса fetch и итерирует все таблицы в данном экземпляре; это может быть полезно для еженедельной работы ETL (Extract, Transform, Load).
Лямбда-функция может быть запущена с помощью различных ресурсов, например таймеров Event Bridge или API-шлюза.
Пример архитектуры приведен ниже: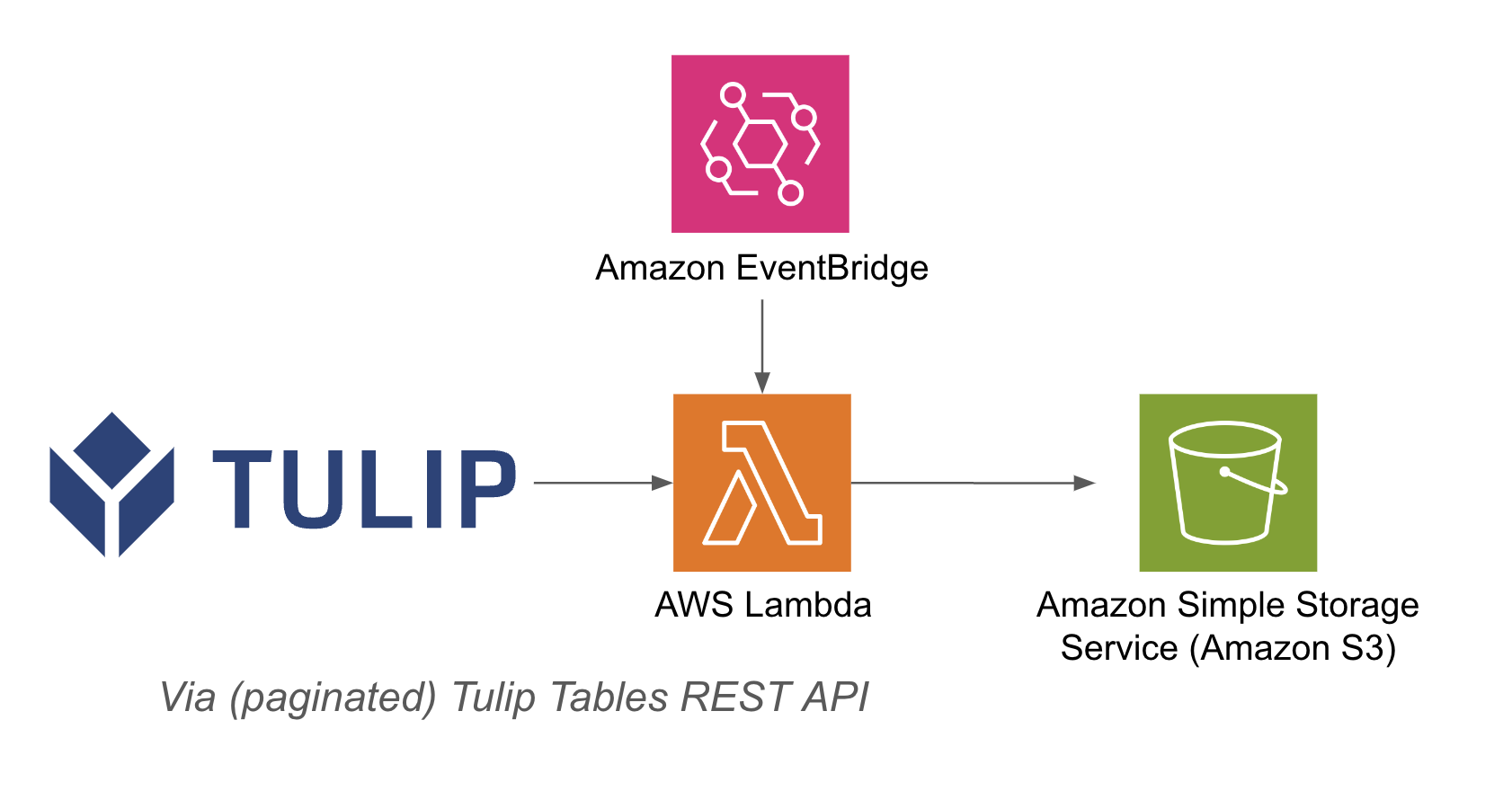 {height="" width=""}.
{height="" width=""}.
Установка
Для этого примера интеграции необходимо следующее:
- Использование API Tulip Tables (Получение ключа и секрета API в настройках аккаунта)
- Tulip Table (Получение уникального идентификатора таблицы).
Высокоуровневые шаги:1. Создайте функцию AWS Lambda с соответствующим триггером (API Gateway, Event Bridge Timer и т.д.)2. Убедитесь, что 3. Получите данные таблицы Tulip с помощью примера ниже``pythonimport jsonimport awswrangler as wrimport boto3from datetime import datetimeimport pandas as pdimport requestsimport os
# Получение текущей временной метки для уникальных имен файлов
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
bucket = os.getenv('bucket_name')
# Функция для преобразования словарей в строки
def dict_to_str(cell): if isinstance(cell, dict): return str(cell) return cell
def query_table(table_id, base_url, api_header): offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row: row.apply(dict_to_str), axis=1) return df
# создать функцию
def write_to_s3(row, base_url, api_header, bucket): table = row['label'] id = row['id'] df = query_table(id, base_url, api_header)
path = f's3://{bucket}/{timestamp}/{table}.csv'# Запись DataFrame в S3 как CSVwr.s3.to_csv( df=df, path=path, index=False)print(f "Wrote {table} to {path}")return f "Wrote {table} to {path}"
def lambda_handler(event, context): api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) table_names = pd.DataFrame(r.json())
# запрос таблицы functiontable_names.apply(lambda row: write_to_s3(row, base_url, api_header, bucket), axis=1)return { 'statusCode': 200, 'body': json.dumps('записали в s3!')}
## Примеры использования и дальнейшие шаги
После завершения интеграции с лямбдой вы можете легко анализировать данные с помощью блокнота sagemaker, QuickSight или других инструментов.
**1. Прогнозирование дефектов -** выявление производственных дефектов до их возникновения и увеличение количества первых правильных заказов. Выявление основных производственных факторов качества для внедрения улучшений.
**2. Оптимизация затрат на качество -** выявление возможностей для оптимизации дизайна продукции без ущерба для удовлетворенности клиентов**.**
**3. Оптимизация энергопотребления на производстве -** выявление производственных рычагов для оптимального энергопотребления
**4. Прогнозирование и оптимизация поставок и планирования -** оптимизация графика производства на основе спроса клиентов и графика заказов в режиме реального времени**.**
**5. Глобальный бенчмаркинг машин/линий -** бенчмаркинг аналогичных машин или оборудования с нормализацией**.**
**6. Глобальное / региональное цифровое управление производительностью -** консолидированные данные для создания информационных панелей в режиме реального времени