
Usprawnienie pobierania danych z Tulip do AWS S3 dla szerszych możliwości analitycznych i integracyjnych
Cel
W tym przewodniku opisano krok po kroku, jak pobrać wszystkie dane z Tulip Tables za pomocą funkcji Lambda i zapisać je w zasobniku S3.
Wykracza to poza podstawowe zapytanie pobierające i iteruje przez wszystkie tabele w danej instancji; może to być świetne rozwiązanie dla cotygodniowego zadania ETL (Extract, Transform, Load).
Funkcja lambda może być wyzwalana za pomocą różnych zasobów, takich jak timery Event Bridge lub API Gateway
Przykładowa architektura znajduje się poniżej: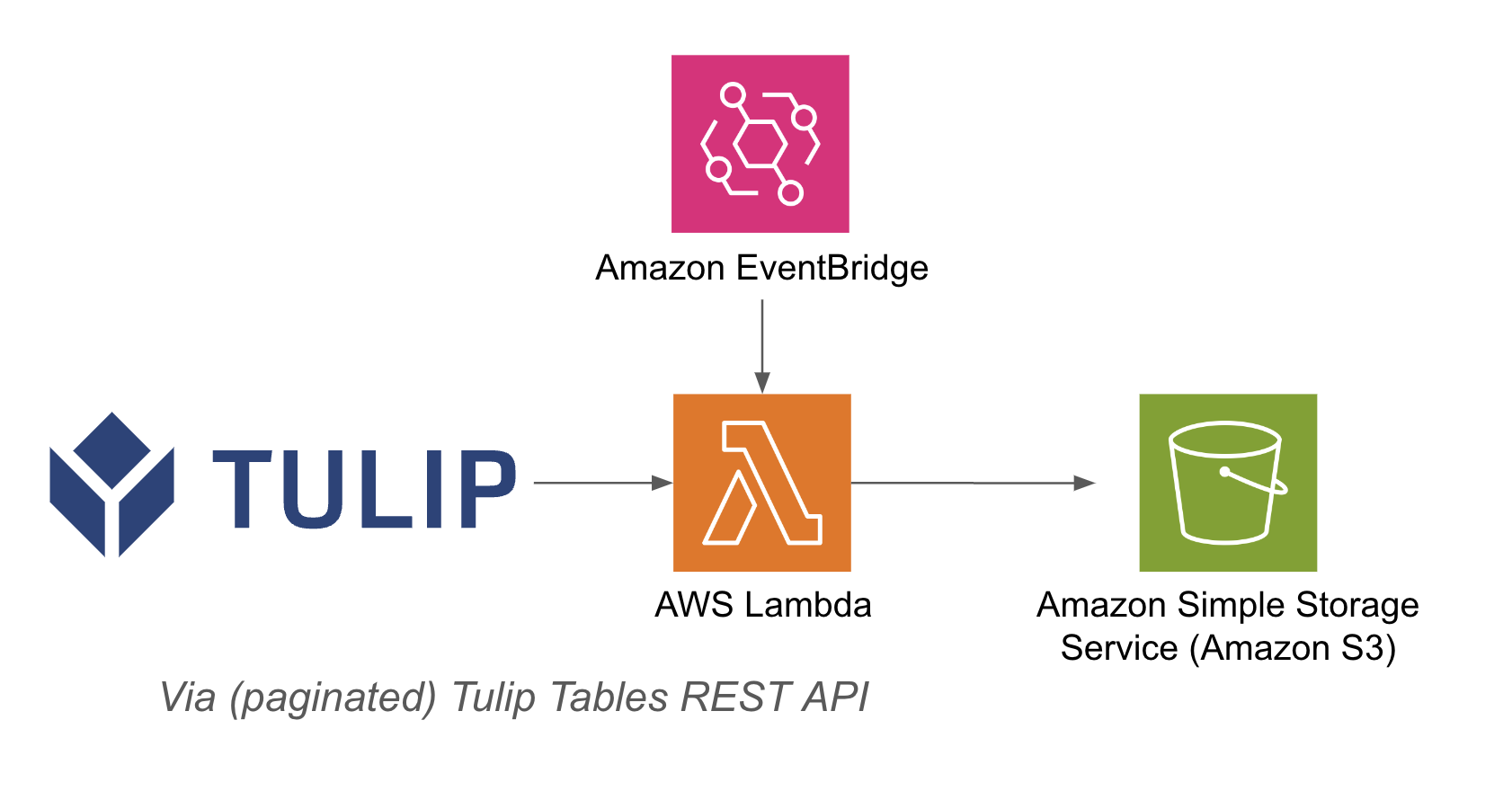
Konfiguracja
Ta przykładowa integracja wymaga następujących elementów:
- Korzystanie z API Tulip Tables (Uzyskaj klucz API i sekret w ustawieniach konta)
- Tabela Tulip (Uzyskaj unikalny identyfikator tabeli)
Kroki na wysokim poziomie:1. Utwórz funkcję AWS Lambda z odpowiednim wyzwalaczem (API Gateway, Event Bridge Timer itp.)2. Upewnij się, że 3. Pobierz dane z tabeli Tulip za pomocą poniższego przykładu``pythonimport jsonimport awswrangler as wrimport boto3from datetimeimport datetimeimport pandas as pdimport requestsimport os
# Pobierz bieżący znacznik czasu dla unikalnych nazw plików
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
bucket = os.getenv('bucket_name')
# Funkcja konwertująca słowniki na ciągi znaków
def dict_to_str(cell): if isinstance(cell, dict): return str(cell) return cell
def query_table(table_id, base_url, api_header): offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all" r = requests.get(base_url+function, headers=api_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row: row.apply(dict_to_str), axis=1) return df
# tworzenie funkcji
def write_to_s3(row, base_url, api_header, bucket): table = row['label'] id = row['id'] df = query_table(id, base_url, api_header)
path = f's3://{bucket}/{timestamp}/{table}.csv'# Write DataFrame to S3 as CSVwr.s3.to_csv( df=df, path=path, index=False)print(f "Wrote {table} to {path}")return f "Wrote {table} to {path}"
def lambda_handler(event, context): api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) table_names = pd.DataFrame(r.json())
# query table functiontable_names.apply(lambda row: write_to_s3(row, base_url, api_header, bucket), axis=1)return { 'statusCode': 200, 'body': json.dumps('wrote to s3!')}
## Przypadki użycia i kolejne kroki
Po sfinalizowaniu integracji z lambda można łatwo analizować dane za pomocą notatnika sagemaker, QuickSight lub wielu innych narzędzi.
**1. Przewidywanie usterek**- identyfikacja usterek produkcyjnych przed ich wystąpieniem i zwiększenie liczby poprawek za pierwszym razem - identyfikacja głównych czynników wpływających na jakość produkcji w celu wdrożenia ulepszeń.
**2. Optymalizacja kosztów jakości -** identyfikacja możliwości optymalizacji projektu produktu bez wpływu na zadowolenie klienta.
**3. Optymalizacja zużycia energii -** identyfikacja dźwigni produkcyjnych w celu optymalizacji zużycia energii.
**4. Przewidywanie i optymalizacja dostaw i planowania -** optymalizacja harmonogramu produkcji w oparciu o zapotrzebowanie klientów i harmonogram zamówień w czasie rzeczywistym.
**5. Globalna analiza porównawcza maszyn/linii -** analiza porównawcza podobnych maszyn lub urządzeń z normalizacją.
**6. Globalne / regionalne cyfrowe zarządzanie wydajnością -** skonsolidowane dane do tworzenia pulpitów nawigacyjnych w czasie rzeczywistym