
Az adatok Tulipből az AWS S3-ra történő lekérdezésének egyszerűsítése a szélesebb körű analitikai és integrációs lehetőségek érdekében.
Cél
Ez az útmutató lépésről lépésre bemutatja, hogyan lehet az összes Tulip Tables adatot egy Lambda-funkcióval lekérni és egy S3 vödörbe írni.
Ez túlmutat az alapvető lekérdezésen, és egy adott példányban lévő összes táblán végigmegy; ez nagyszerű lehet egy heti ETL-feladathoz (Extract, Transform, Load).
A lambda-funkciót számos erőforráson keresztül lehet elindítani, például eseményhíd-időzítőkön vagy API-átjárón keresztül.
Egy példa architektúra az alábbiakban látható: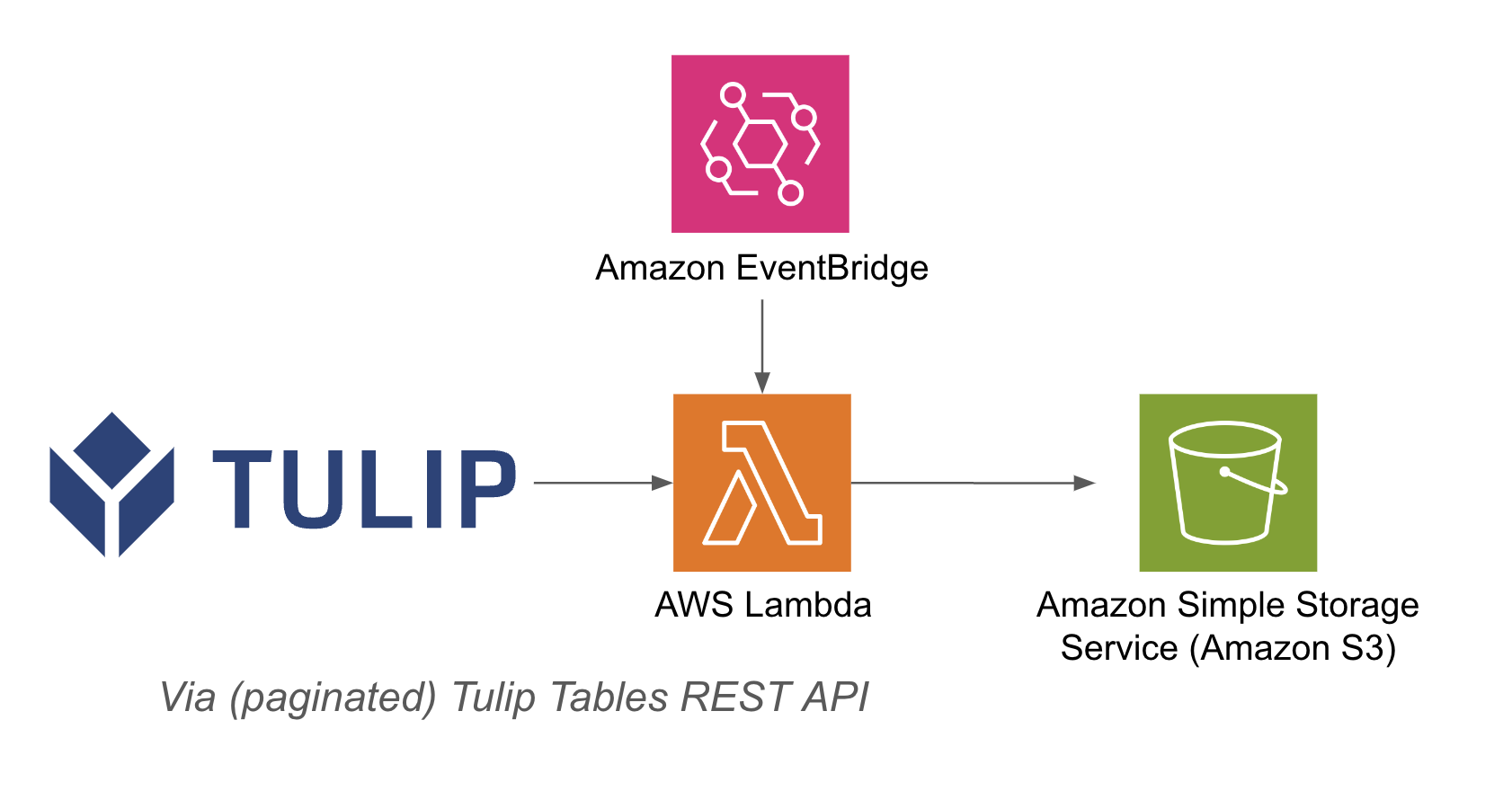
Beállítás
Ehhez a példaintegrációhoz a következőkre van szükség:
- A Tulip Tables API használata (API-kulcs és titok beszerzése a fiókbeállításokban).
- Tulip Table (A tábla egyedi azonosítójának beszerzése.
Magas szintű lépések:1. Hozzon létre egy AWS Lambda függvényt a megfelelő triggerrel (API Gateway, Event Bridge Timer stb.)2. Biztosítsa, hogy a 3. Hívja le a Tulip tábla adatait az alábbi példával```pythonimport jsonimport awswrangler as wrimport boto3from datetime import datetimeimport pandas as pdimport requestsimport os.
# Az aktuális időbélyegző kinyerése egyedi fájlnevekhez
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
bucket = os.getenv('bucket_name')
# Funkció a szótárak karakterláncokká alakítására
def dict_to_str(cell): if isinstance(cell, dict): return str(cell) return cell
def query_table(table_id, base_url, api_header): offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row: row.apply(dict_to_str), axis=1) return df
# Create function
def write_to_s3(row, base_url, api_header, bucket): table = row['label'] id = row['id'] df = query_table(id, base_url, api_header)
path = f's3://{bucket}/{timestamp}/{table}.csv'# DataFrame írása S3-ra CSV-kéntwr.s3.to_csv( df=df, path=path, index=False)print(f "Wrote {table} to {path}")return f "Wrote {table} to {path}"
def lambda_handler(event, context): api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) table_names = pd.DataFrame(r.json())
# táblázat lekérdezése functiontable_names.apply(lambda row: write_to_s3(row, base_url, api_header, bucket), axis=1)return { 'statusCode': 200, 'body': json.dumps('wrote to s3!')}
## Felhasználási esetek és következő lépések
Miután véglegesítette az integrációt a lambdával, könnyen elemezheti az adatokat egy sagemaker notebookkal, a QuickSighttal vagy számos más eszközzel.
**1. Hibák előrejelzése -** A gyártási hibák azonosítása, mielőtt azok bekövetkeznének, és a helyes első alkalommal történő javítás növelése.- A minőséget befolyásoló legfontosabb gyártási tényezők azonosítása a fejlesztések végrehajtása érdekében.
**2. A minőség optimalizálásának költségei -** A terméktervezés optimalizálásának lehetőségeinek azonosítása a vevői elégedettség befolyásolása nélkül.
**3. Termelési energiaoptimalizálás-** Az optimális energiafogyasztás érdekében a termelésben alkalmazott mozgatórugók azonosítása**.**
**4. Szállítási és tervezési előrejelzés és optimalizálás-** A gyártási ütemezés optimalizálása a vevői kereslet és a valós idejű rendelési ütemezés alapján**.**
**5. Globális gép/sor teljesítményértékelés-** Hasonló gépek vagy berendezések összehasonlítása normalizálással.
**6. Globális/regionális digitális teljesítménymenedzsment-** Konszolidált adatok valós idejű műszerfalak létrehozásához**.**