
더 광범위한 분석 및 통합 기회를 위해 Tulip에서 AWS S3로 데이터 가져오기를 간소화하세요.
목적
이 가이드에서는 Lambda 함수를 통해 모든 Tulip 테이블 데이터를 가져와 S3 버킷에 쓰는 방법을 단계별로 안내합니다.
이것은 기본 가져오기 쿼리를 넘어 주어진 인스턴스의 모든 테이블을 반복하는 것으로, 주간 ETL 작업(추출, 변환, 로드)에 유용할 수 있습니다.
람다 함수는 이벤트 브리지 타이머나 API 게이트웨이와 같은 다양한 리소스를 통해 트리거될 수 있습니다.
아키텍처 예시는 다음과 같습니다: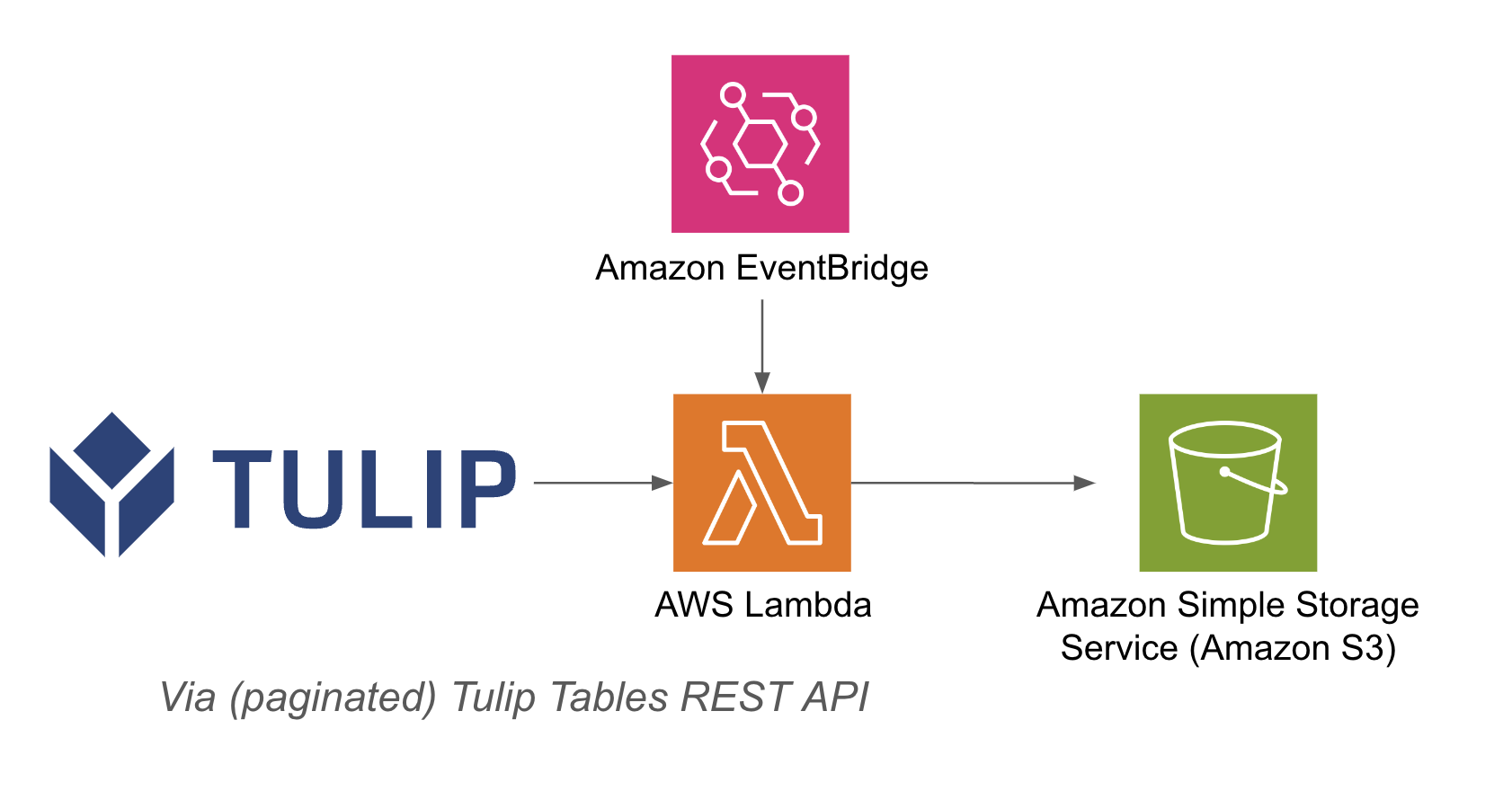
설정
이 예제 연동에는 다음이 필요합니다:
- 튤립 테이블 API 사용(계정 설정에서 API 키 및 비밀번호 가져오기)
- 튤립 테이블(테이블 고유 ID 가져오기
상위 단계: 1. 관련 트리거(API 게이트웨이, 이벤트 브리지 타이머 등)가 있는 AWS Lambda 함수를 생성합니다.2. 아래 예제를 사용하여 3. Tulip 테이블 데이터를 가져옵니다```pythonimport jsonimport awswrangler as wrimport boto3from datetime import datetimeimport pandas as pdimport requestsimport os.
# 고유 파일 이름에 대한 현재 타임스탬프 가져오기
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
bucket = os.getenv('bucket_name')
# 딕셔너리를 문자열로 변환하는 함수
def dict_to_str(cell): if isinstance(cell, dict): return str(cell) return cell
def query_table(table_id, base_url, api_header): offset = 0 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=api_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df = df.apply(lambda row: row.apply(dict_to_str), axis=1) return df
# 함수 생성
def write_to_s3(row, base_url, api_header, bucket): table = row['label'] id = row['id'] df = query_table(id, base_url, api_header)
경로 = f's3://{버킷}/{타임스탬프}/{테이블}.csv'# 데이터 프레임을 CSV로 S3에 쓰기wr.s3.to_csv( df=df, 경로=패스, 인덱스=False)print(f"{테이블}을 {경로}에 썼습니다")return f"{테이블}을 {경로}에 썼습니다"
def lambda_handler(event, context): api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')} instance = os.getenv('tulip_instance') base_url = f'https://{instance}.tulip.co/api/v3' get_tables_function = '/tables' r = requests.get(base_url+get_tables_function, headers=api_header) table_names = pd.DataFrame(r.json()))
# 쿼리 테이블 functiontable_names.apply(lambda row: write_to_s3(row, base_url, api_header, bucket), axis=1)return { 'statusCode': 200, 'body': json.dumps('wrote to s3!')}
## 사용 사례 및 다음 단계
람다와의 통합을 완료한 후에는 새그메이커 노트북, QuickSight 또는 기타 다양한 도구를 사용하여 데이터를 쉽게 분석할 수 있습니다.
**1. 결함 예측 -** 생산 결함이 발생하기 전에 미리 파악하여 개선하기 위한 핵심 생산 동인을 파악합니다.
**2. 품질 최적화 비용-** 고객 만족도에 영향을 주지 않고 제품 설계를 최적화할 수 있는 기회 파악
**3. 생산 에너지 최적화-** 에너지 소비 최적화를 위한 생산 레버 식별
**4. 납기 및 계획 예측 및 최적화-** 고객 수요 및 실시간 주문 일정에 따라 생산 일정 최적화
**5. 글로벌 기계/라인 벤치마킹-** 유사 기계 또는 장비의 표준화를 통한 벤치마킹
**6. 글로벌/지역별 디지털 성과 관리-** 통합된 데이터로 실시간 대시보드 생성