
Racionalizar la obtención de datos de Tulip a AWS para ampliar las oportunidades de análisis e integración.
Propósito
Esta guía explica paso a paso cómo obtener datos de Tulip Tables AWS a través de una función lambda.
La función Lambda puede ser activada a través de una variedad de recursos tales como temporizadores de Event Bridge o una API Gateway.
A continuación se muestra un ejemplo de arquitectura:
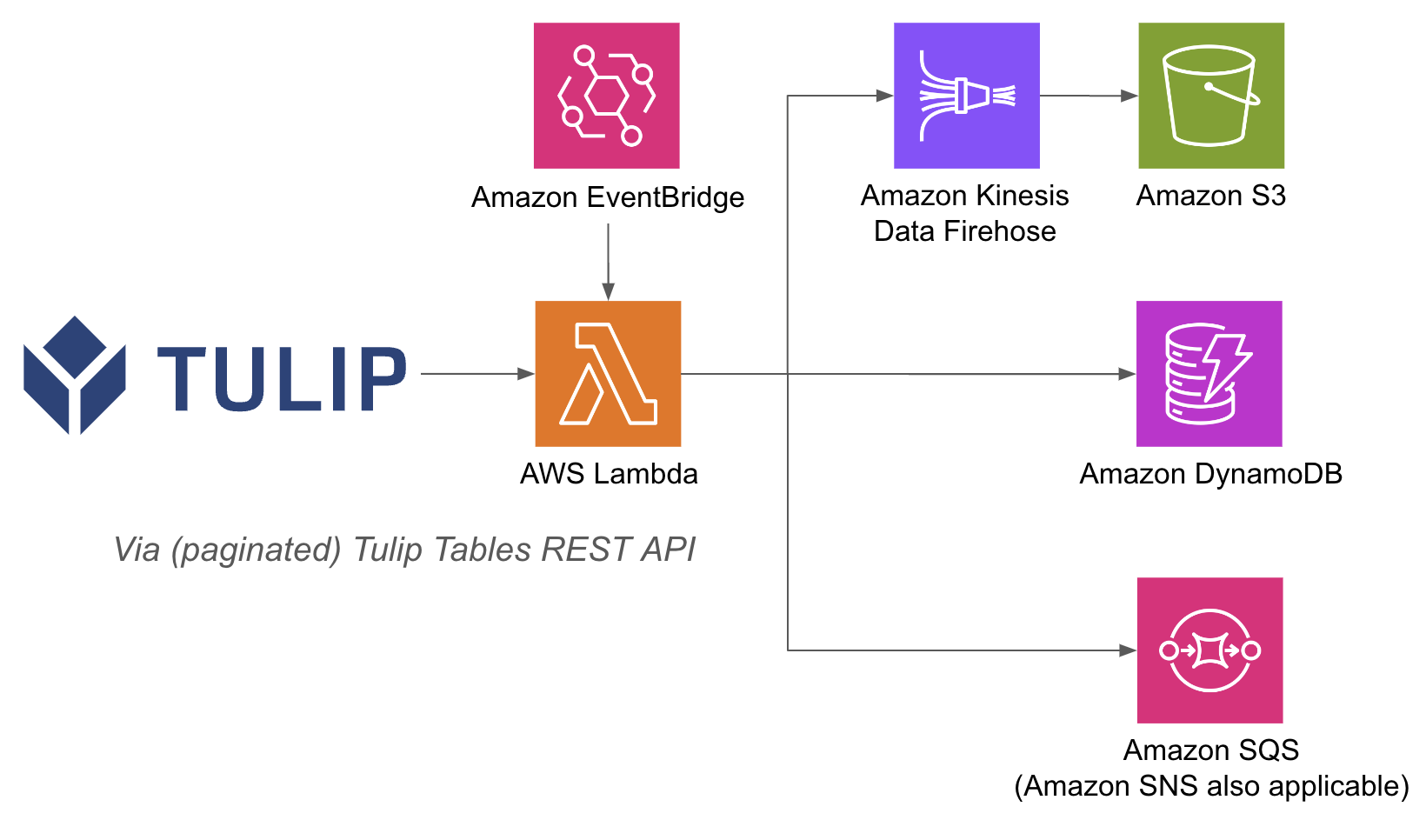
Realizar operaciones de AWS dentro de una función lambda puede ser más fácil, porque con API Gateway y las funciones Lambda, no es necesario autenticar las bases de datos con nombre de usuario y contraseña en el lado de Tulip; puede confiar en los métodos de autenticación de IAM dentro de AWS. Esto también agiliza la forma de aprovechar otros servicios de AWS como Redshift, DynamoDB, etc.
Configuración
Este ejemplo de integración requiere lo siguiente:
- Uso de la API de Tulip Tables (obtenga la clave y el secreto de la API en la configuración de la cuenta)
- Tulip Table (Obtener el ID único de la tabla
Pasos de alto nivel 1. Crear una función AWS Lambda con el activador correspondiente (API Gateway, Event Bridge Timer, etc.). Fetch the Tulip table data with the example below ```python import json import pandas as pd import numpy as np import requests
# NOTA la capa pandas de AWS necesitará
# a la función Lambda
def lambda_handler(event, context): auth_header = OBTENER DE API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df.shape # esto añade 100 registros a un marco de datos y luego se puede utilizar para S3, Firehose, etc. # utilizar la variable de datos para escribir en S3, Firehose,
# bases de datos, y más ```
- El trigger puede ejecutarse en un temporizador o dispararse a través de una URL
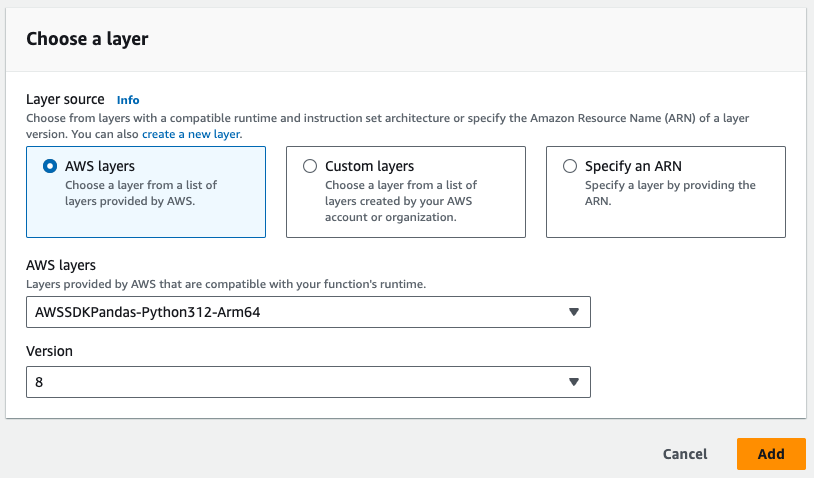
- Tenga en cuenta la capa de Pandas requerida en la imagen de abajo
- Por último, añade las integraciones que sean necesarias. Puedes escribir los datos en una base de datos, S3, o un servicio de notificación desde funciones lambda.
Casos de uso y próximos pasos
Una vez que haya finalizado la integración con lambda, puede analizar fácilmente los datos con un cuaderno sagemaker, QuickSight o una variedad de otras herramientas.
1. Predicción de defectos: identifique los defectos de producción antes de que se produzcan y aumente el número de aciertos a la primera - Identifique los principales impulsores de la calidad en la producción para aplicar mejoras
2. Optimización del coste de lacalidad - Identificar oportunidades para optimizar el diseño del producto sin afectar a la satisfacción del cliente.
3. Optimizaciónde la energía de producción - Identificar palancas de producción para optimizar el consumo de energía
4. Predicción y optimización de la entrega y la planificación- Optimizar el programa de producción en función de la demanda del cliente y el programa de pedidos en tiempo real
5. Benchmarking global de máquinas / líneas- Benchmark de máquinas o equipos similares con normalización
6. Gestión del rendimiento digital global / regional- Datos consolidados para crear cuadros de mando en tiempo real