
Упорядочить получение данных из Tulip в AWS для расширения возможностей аналитики и интеграции
Цель
В этом руководстве пошагово описано, как получить данные Tulip Tables в AWS с помощью функции Lambda.
Лямбда-функция может быть запущена с помощью различных ресурсов, таких как таймеры Event Bridge или API-шлюз.
Пример архитектуры приведен ниже:
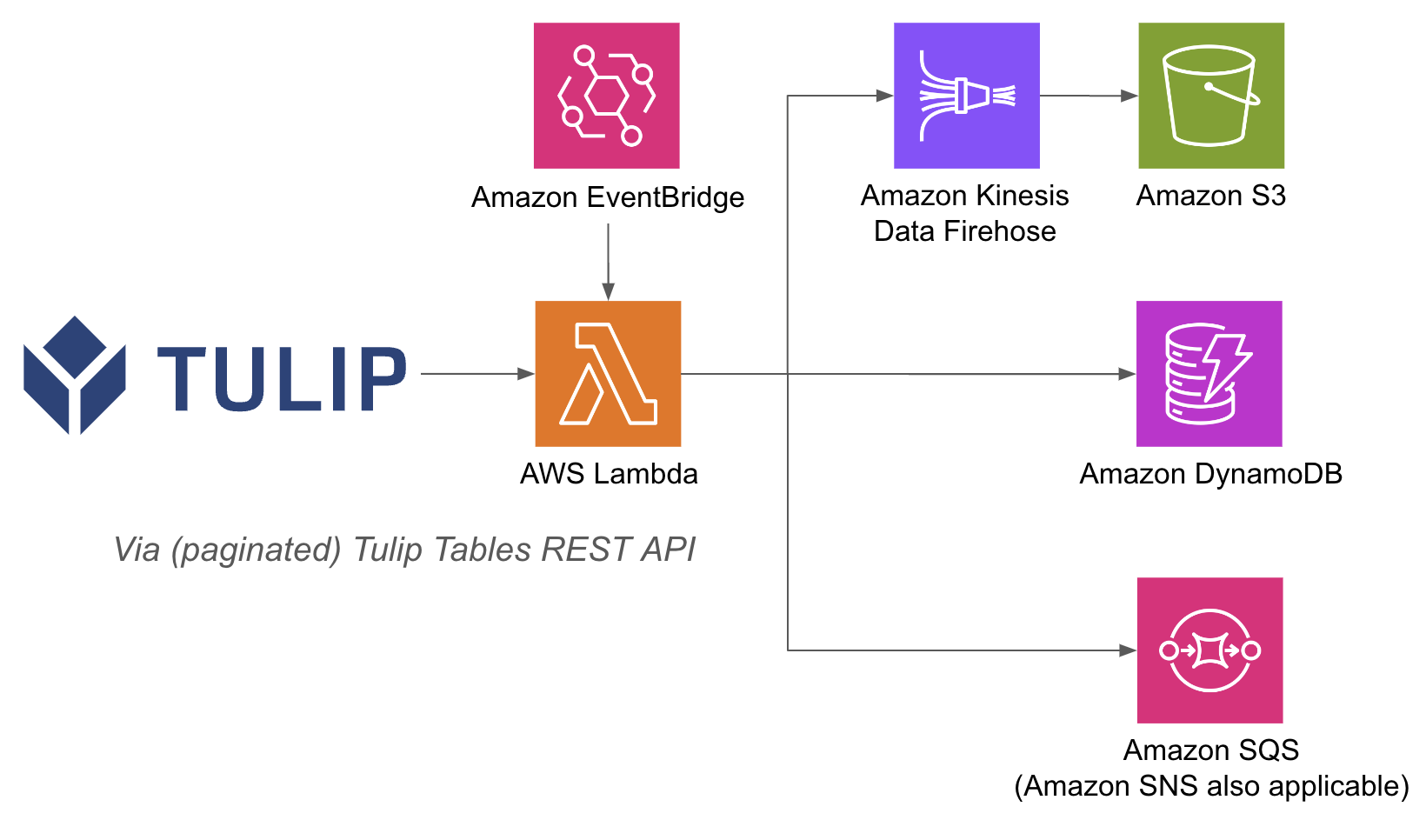
Выполнение операций AWS внутри лямбда-функции может быть проще, потому что с API Gateway и лямбда-функциями вам не нужно аутентифицировать базы данных с помощью имени пользователя и пароля на стороне Tulip; вы можете полагаться на методы аутентификации IAM внутри AWS. Это также упрощает использование других сервисов AWS, таких как Redshift, DynamoDB и т. д.
Настройка
Для этого примера интеграции требуется следующее:
- Использование API Tulip Tables (получение ключа и секрета API в настройках учетной записи).
- Tulip Table (получение уникального идентификатора таблицы).
Высокоуровневые шаги: 1. Создайте функцию AWS Lambda с соответствующим триггером (API Gateway, Event Bridge Timer и т. д.) 2. Получите данные из таблицы Tulip, используя пример ниже ``python import json import pandas as pd import numpy as np import requests
# ПРИМЕЧАНИЕ: слой pandas из AWS необходимо
# добавить в функцию Lambda
def lambda_handler(event, context): auth_header = OBTAIN FROM API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df.shape # это добавляет 100 записей к датафрейму и затем может быть использовано для S3, Firehose и т.д. # используйте переменную data для записи в S3, Firehose,
# базы данных и многое другое ```
- Триггер может выполняться по таймеру или запускаться по URL-адресу.
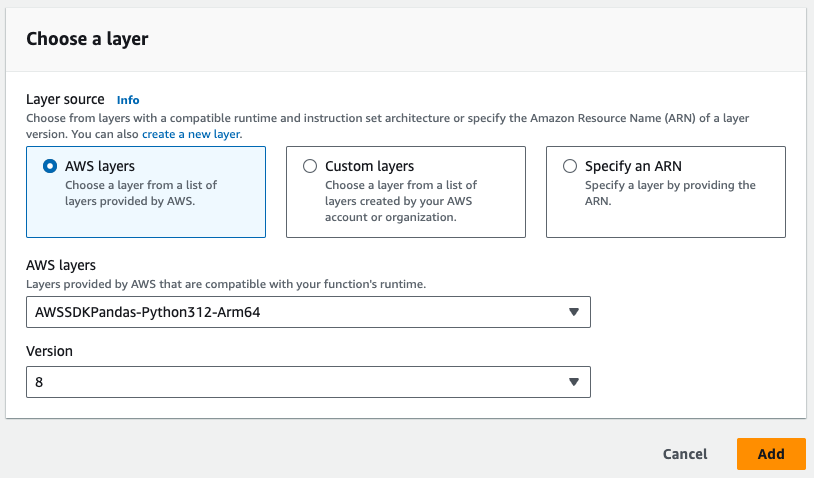
- Обратите внимание на слой Pandas, необходимый на изображении ниже.
- Наконец, добавьте все необходимые интеграции. Вы можете записывать данные в базу данных, S3 или сервис уведомлений из лямбда-функций.
Примеры использования и следующие шаги
После завершения интеграции с лямбдой вы можете легко проанализировать данные с помощью блокнота sagemaker, QuickSight или других инструментов.
1. Прогнозирование дефектов- выявление производственных дефектов до их возникновения и увеличение количества правильных решений с первого раза. - Определение основных производственных факторов качества для внедрения улучшений.
2. Оптимизация затрат на качество- определение возможностей для оптимизации конструкции продукции без ущерба для удовлетворенности клиентов.
3. Оптимизация энергопотребления на производстве- определение производственных рычагов для оптимального энергопотребления
4. Прогнозирование и оптимизация поставок и планирования- Оптимизация графика производства на основе спроса клиентов и графика заказов в режиме реального времени.
5. Глобальный бенчмаркинг машин/линий- бенчмаркинг аналогичных машин или оборудования с нормализацией.
6. Глобальное / региональное цифровое управление производительностью- консолидированные данные для создания приборных панелей в режиме реального времени