
简化从 Tulip 到 AWS 的数据获取,以获得更广泛的分析和集成机会
目的
本指南将逐步介绍如何通过 Lambda 函数从 AWS 获取 Tulip 表数据。
lambda 函数可通过各种资源触发,如事件桥定时器或 API 网关。
下面列出了一个架构示例:
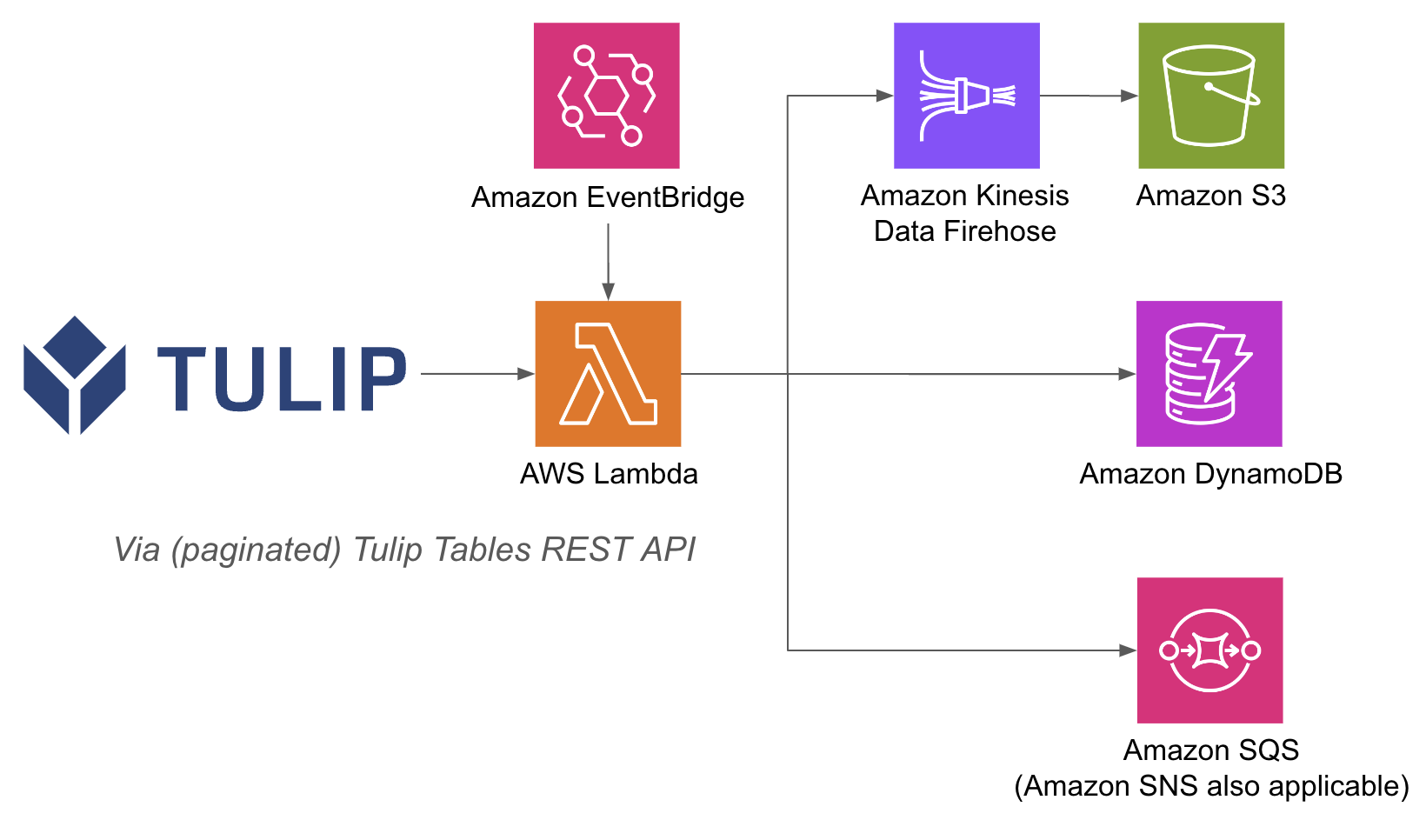
在 lambda 函数内执行 AWS 操作会更容易,因为有了 API Gateway 和 Lambda 函数,您就不需要在 Tulip 端使用用户名和密码验证数据库;您可以依赖 AWS 内部的 IAM 验证方法。 这也简化了如何利用其他 AWS 服务,如 Redshift、DynamoDB 等。
设置
本集成示例需要以下条件:
- 使用郁金香表 API(在账户设置中获取 API 密钥和秘密)
- 郁金香表(获取表唯一 ID
高级步骤: 1.使用相关触发器(API 网关、事件桥定时器等)创建 AWS Lambda 函数 2.使用下面的示例获取郁金香表数据 ```python import json import pandas as pd import numpy as np import requests
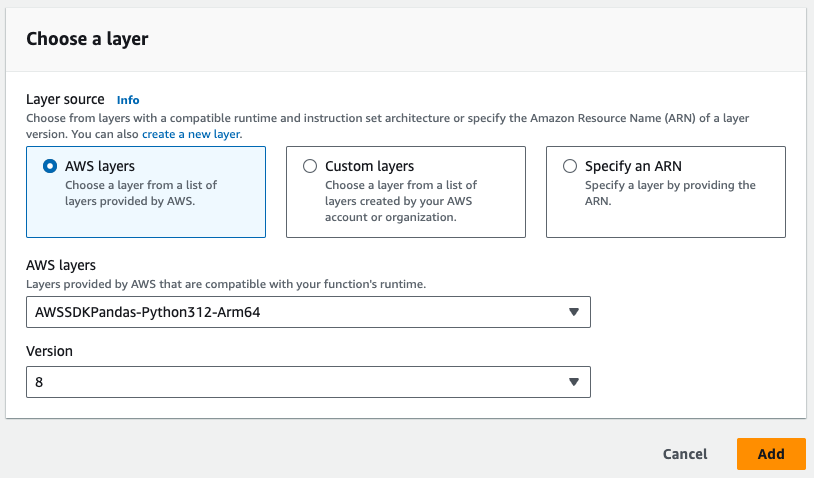
# 注意,需要将 AWS 的 pandas 层
# 添加到 Lambda 函数中
def lambda_handler(event, context): auth_header = OBTAIN FROM API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r. json())json()) df = pd.concat([df, df_append], axis=0) df.shape # 将 100 条记录附加到数据帧,然后可用于 S3、Firehose 等 # 使用数据变量写入 S3、Firehose、
# 数据库,等等 ````
- 触发器可在定时器上运行或通过 URL 触发
- 注意下图中需要的 Pandas 层
- 最后,添加所需的集成。您可以通过 lambda 函数将数据写入数据库、S3 或通知服务。
用例和下一步
完成与 lambda 的集成后,您可以使用 sagemaker 笔记本、QuickSight 或其他各种工具轻松分析数据。
1.缺陷预测- 在缺陷发生之前识别生产缺陷,提高首次正确率。
2.质量成本优化- 在不影响客户满意度的前提下,确定优化产品设计的机会 3.
3.生产能源优化- 确定优化能源消耗的生产杠杆 4.
4.交货和计划预测与优化- 根据客户需求和实时订单计划优化生产计划 5.
5.全球机器/生产线标杆管理- 对类似机器或设备进行标准化标杆管理 6.
6.全球/区域数字化绩效管理- 整合数据以创建实时仪表板