
Simplifique a obtenção de dados do Tulip para o AWS para oportunidades mais amplas de análise e integração
Objetivo
Este guia explica passo a passo como buscar dados da Tulip Tables no AWS por meio de uma função Lambda.
A função lambda pode ser acionada por meio de uma variedade de recursos, como temporizadores do Event Bridge ou um API Gateway
Um exemplo de arquitetura está listado abaixo:
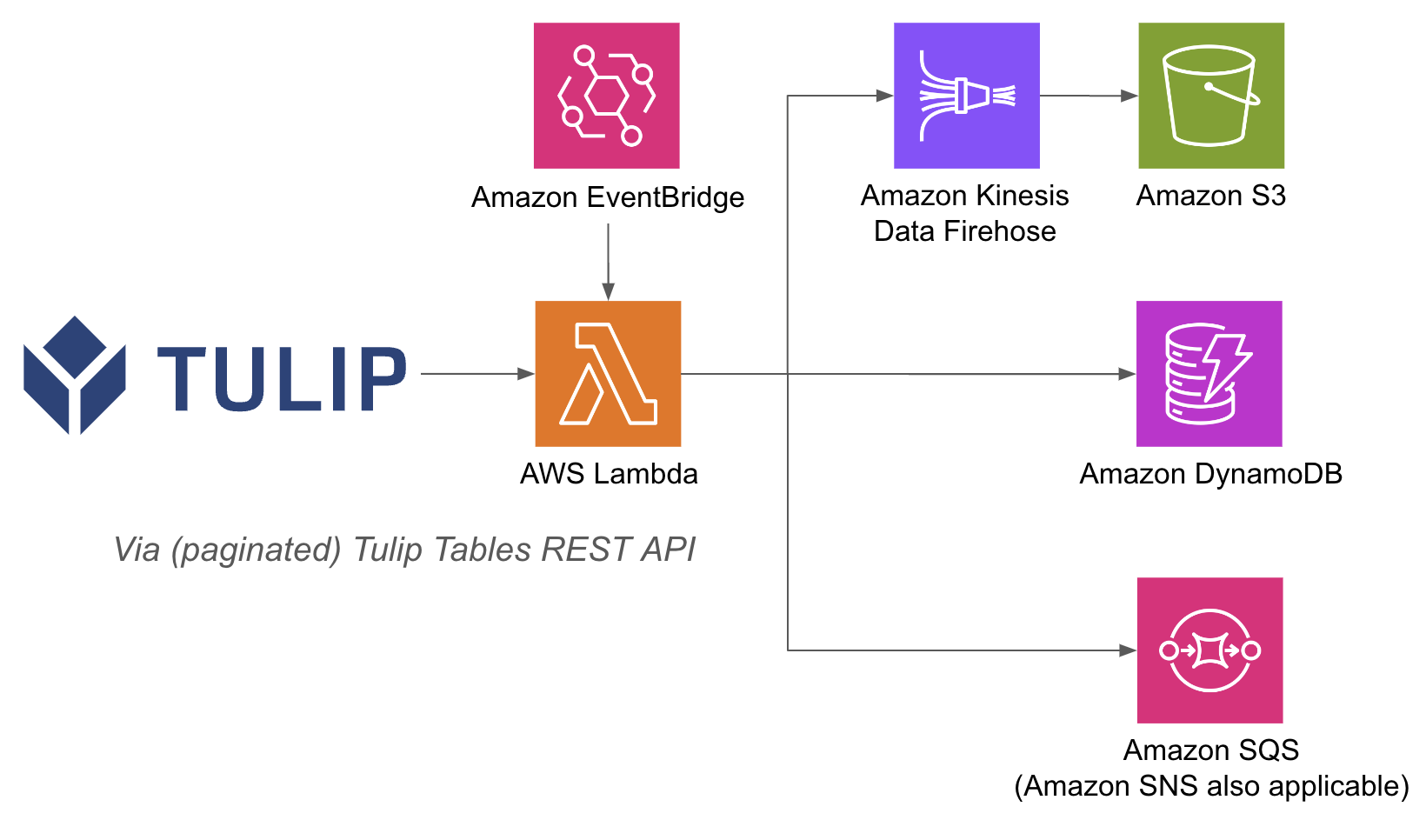
Realizar operações do AWS dentro de uma função lambda pode ser mais fácil, porque com o API Gateway e as funções Lambda, você não precisa autenticar bancos de dados com nome de usuário e senha no lado da Tulip; você pode confiar nos métodos de autenticação IAM dentro do AWS. Isso também simplifica a forma de aproveitar outros serviços do AWS, como Redshift, DynamoDB e outros.
Configuração
Este exemplo de integração requer o seguinte:
- Uso da API Tulip Tables (obtenha a chave e o segredo da API nas configurações da conta)
- Tabela Tulip (obtenha o ID exclusivo da tabela)
Etapas de alto nível: 1. Crie uma função AWS Lambda com o acionador relevante (API Gateway, Event Bridge Timer, etc.). 2. Busque os dados da tabela Tulip com o exemplo abaixo ```python import json import pandas as pd import numpy as np import requests
# OBSERVE que a camada do pandas do AWS precisará
# ser adicionada à função Lambda
def lambda_handler(event, context): auth_header = OBTAIN FROM API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID]/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID]/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df.shape # isso acrescenta 100 registros a um dataframe e pode ser usado para S3, Firehose etc. # use a variável data para gravar em S3, Firehose,
# bancos de dados e outros ```
- O acionador pode ser executado em um cronômetro ou acionado por meio de um URL
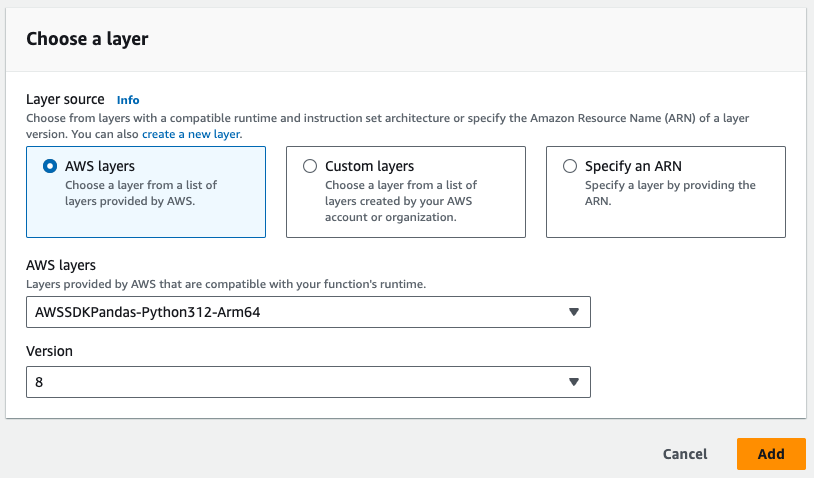
- Observe a camada do Pandas necessária na imagem abaixo
- Por fim, adicione as integrações necessárias. Você pode gravar os dados em um banco de dados, no S3 ou em um serviço de notificação a partir de funções lambda
Casos de uso e próximas etapas
Depois de finalizar a integração com o lambda, você pode analisar facilmente os dados com um notebook sagemaker, QuickSight ou várias outras ferramentas.
1. Previsão de defeitos- Identifique os defeitos de produção antes que eles ocorram e aumente o número de acertos na primeira vez - Identifique os principais fatores de qualidade da produção para implementar melhorias
2. Otimização do custo da qualidade- Identificar oportunidades para otimizar o design do produto sem afetar a satisfação do cliente
3. Otimização da energia de produção- Identificar alavancas de produção para otimizar o consumo de energia
4. Previsão e otimização de entrega e planejamento- otimizar a programação da produção com base na demanda do cliente e na programação de pedidos em tempo real
5. Benchmarking global de máquinas/linhas- Faça o benchmarking de máquinas ou equipamentos semelhantes com normalização
6. Gerenciamento de desempenho digital global/regional- Dados consolidados para criar painéis de controle em tempo real