
Usprawnienie pobierania danych z Tulip do AWS dla szerszych możliwości analitycznych i integracyjnych
Cel
W tym przewodniku opisano krok po kroku, jak pobierać dane z Tulip Tables do AWS za pomocą funkcji Lambda.
Funkcja lambda może być wyzwalana za pomocą różnych zasobów, takich jak liczniki czasu Event Bridge lub API Gateway
Przykładowa architektura znajduje się poniżej:
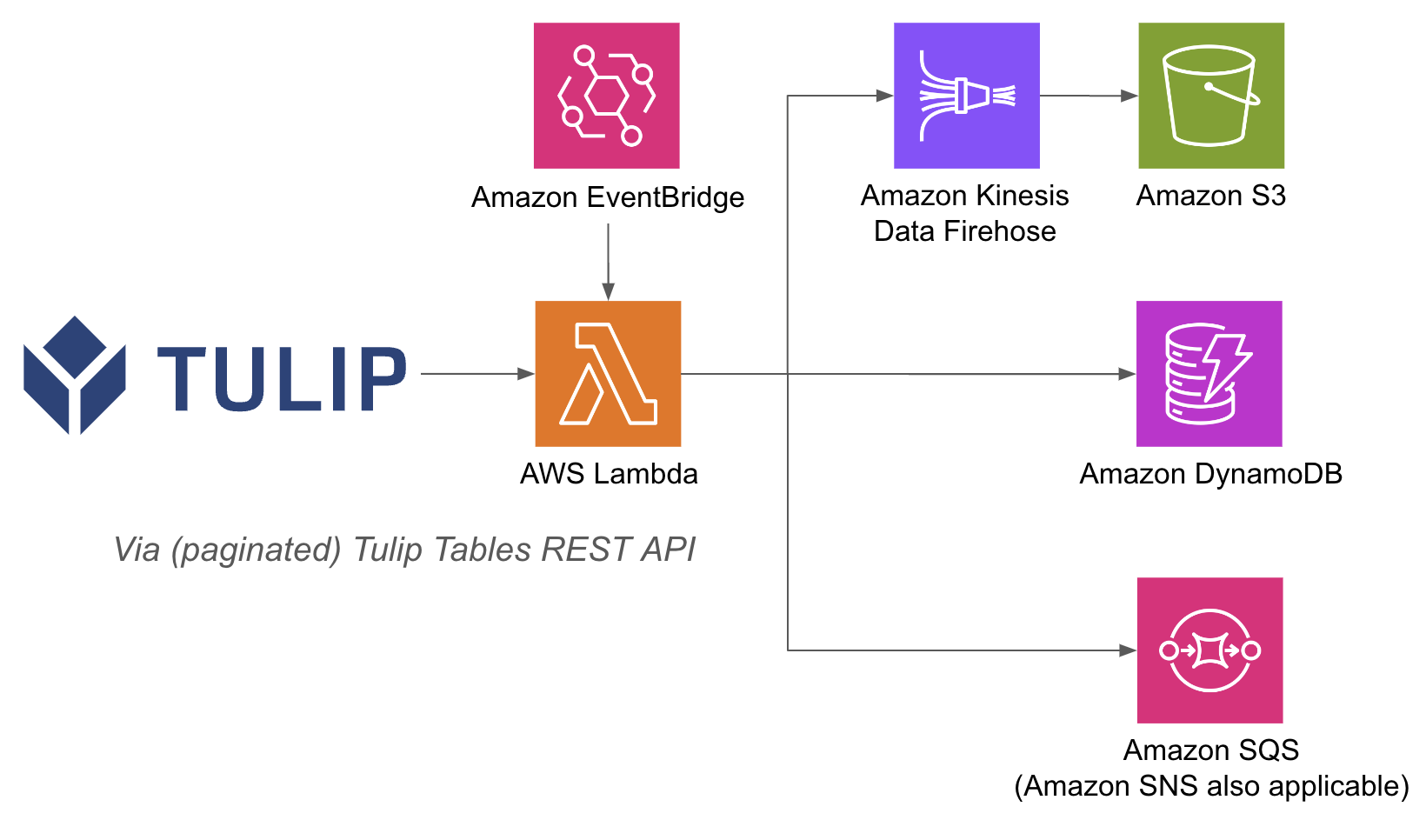
Wykonywanie operacji AWS wewnątrz funkcji lambda może być łatwiejsze, ponieważ dzięki API Gateway i funkcjom Lambda nie trzeba uwierzytelniać baz danych za pomocą nazwy użytkownika i hasła po stronie Tulip; można polegać na metodach uwierzytelniania IAM wewnątrz AWS. Usprawnia to również wykorzystanie innych usług AWS, takich jak Redshift, DynamoDB i innych.
Konfiguracja
Ta przykładowa integracja wymaga następujących elementów:
- Korzystanie z interfejsu API Tulip Tables (Uzyskaj klucz API i sekret w ustawieniach konta)
- Tabela Tulip (Uzyskaj unikalny identyfikator tabeli)
Kroki wysokiego poziomu: 1. Utworzenie funkcji AWS Lambda z odpowiednim wyzwalaczem (API Gateway, Event Bridge Timer itp.) 2. Pobierz dane z tabeli Tulip za pomocą poniższego przykładu ``python import json import pandas as pd import numpy as np import requests
# UWAGA: warstwa pandas z AWS będzie musiała zostać
# zostać dodana do funkcji Lambda
def lambda_handler(event, context): auth_header = OBTAIN FROM API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all" r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all" r = requests.get(base_url+function, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df.shape # to dołącza 100 rekordów do ramki danych i może być następnie użyte dla S3, Firehose, itp. # użyj zmiennej danych do zapisu do S3, Firehose,
# baz danych i nie tylko ```
- Wyzwalacz może być uruchamiany za pomocą timera lub adresu URL.
- Zwróć uwagę na warstwę Pandas wymaganą na poniższym obrazku
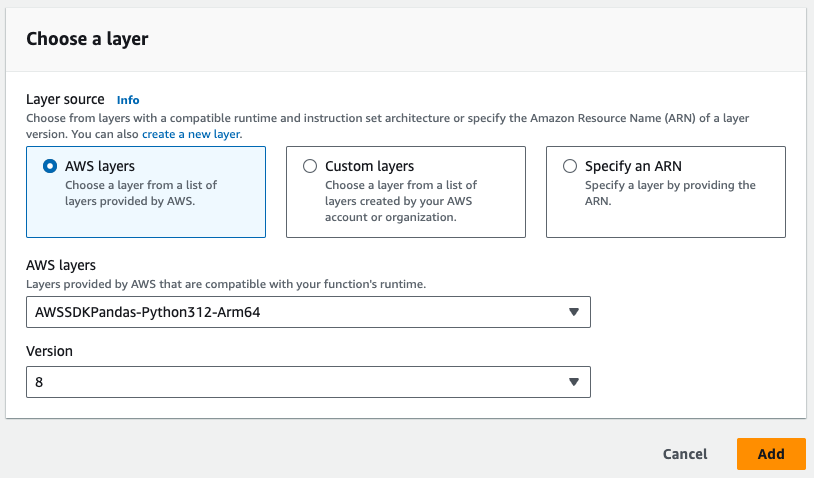
- Na koniec dodaj wszelkie wymagane integracje. Możesz zapisywać dane do bazy danych, S3 lub usługi powiadomień z funkcji lambda.
Przypadki użycia i kolejne kroki
Po sfinalizowaniu integracji z lambda można łatwo analizować dane za pomocą notatnika sagemaker, QuickSight lub wielu innych narzędzi.
1. Przewidywanie usterek- Identyfikacja usterek produkcyjnych przed ich wystąpieniem i zwiększenie liczby poprawek za pierwszym razem - Identyfikacja głównych czynników wpływających na jakość produkcji w celu wdrożenia ulepszeń.
2. Optymalizacja kosztów jakości- identyfikacja możliwości optymalizacji projektu produktu bez wpływu na zadowolenie klienta.
3. Optymalizacja zużycia energiipodczas produkcji - identyfikacja czynników wpływających na optymalne zużycie energii podczas produkcji.
4. Przewidywanie i optymalizacja dostaw i planowania- optymalizacja harmonogramu produkcji w oparciu o zapotrzebowanie klientów i harmonogram zamówień w czasie rzeczywistym.
5. Globalna analiza porównawcza maszyn/linii- analiza porównawcza podobnych maszyn lub urządzeń z normalizacją.
6. Globalne / regionalne cyfrowe zarządzanie wydajnością- skonsolidowane dane do tworzenia pulpitów nawigacyjnych w czasie rzeczywistym