
Az adatok Tulipből az AWS-re történő lekérdezésének egyszerűsítése a szélesebb körű analitikai és integrációs lehetőségek érdekében.
Cél
Ez az útmutató lépésről lépésre bemutatja, hogyan lehet a Tulip Tables adatokat AWS-ről lekérni egy Lambda-funkció segítségével.
A lambda-funkciót számos erőforráson keresztül lehet elindítani, például Event Bridge időzítőkön vagy egy API-átjárón keresztül.
Az alábbiakban egy példaarchitektúra látható:
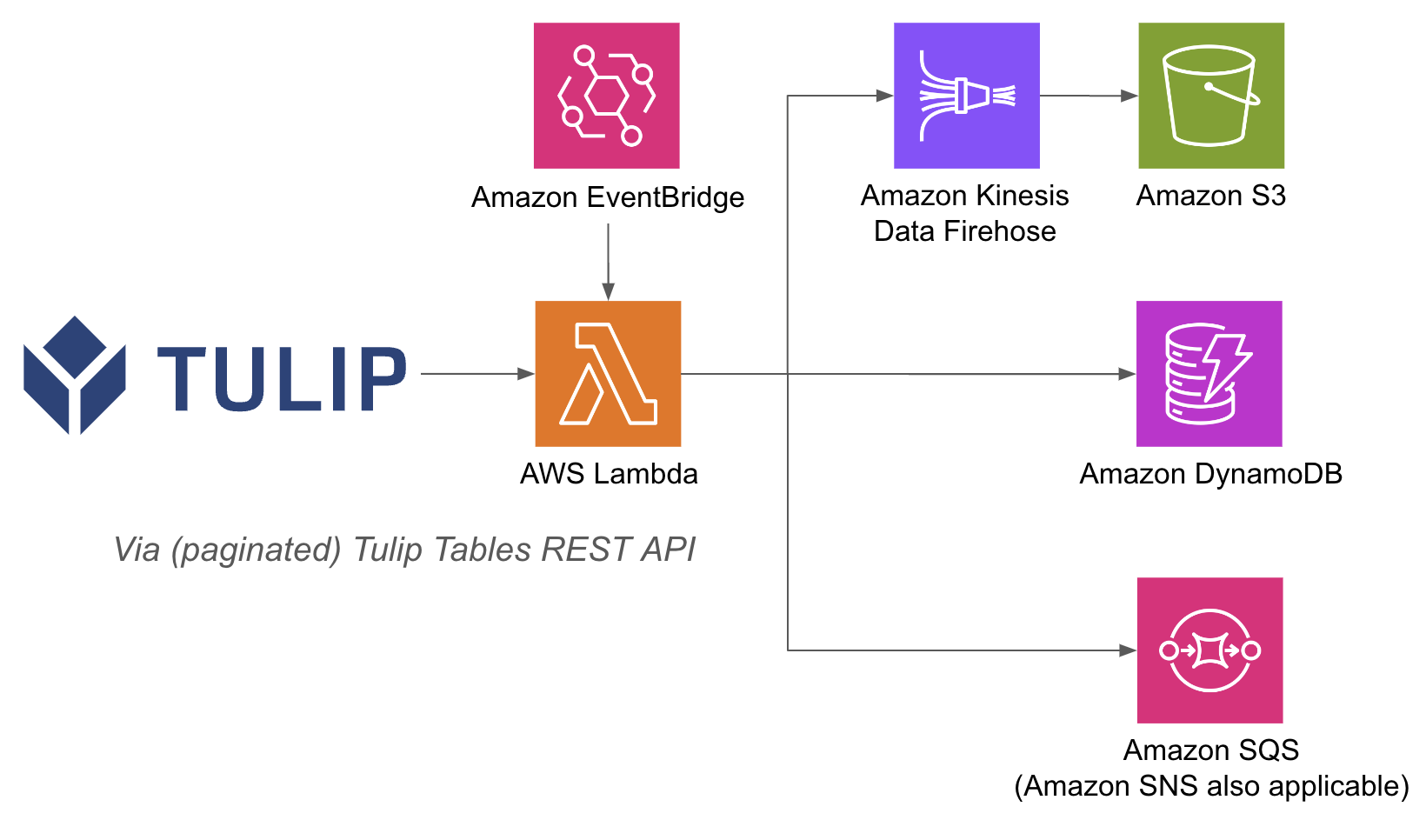
Az AWS műveletek elvégzése egy lambda függvényen belül egyszerűbb lehet, mivel az API Gateway és a Lambda függvények segítségével nem kell az adatbázisokat felhasználónévvel és jelszóval hitelesíteni a Tulip oldalán; az AWS-en belüli IAM hitelesítési módszerekre támaszkodhat. Ez egyszerűsíti más AWS-szolgáltatások, például a Redshift, a DynamoDB és más szolgáltatások kihasználását is.
A beállítása.
Ehhez a példaintegrációhoz a következőkre van szükség:
- A Tulip Tables API használata (API-kulcs és titok lekérése a fiókbeállításokban).
- Tulip Table (A tábla egyedi azonosítójának beszerzése.
Magas szintű lépések: 1. Hozzon létre egy AWS Lambda-funkciót a megfelelő triggerrel (API Gateway, Event Bridge Timer stb.) 2. Hívja le a Tulip tábla adatait az alábbi példával ```python import json import pandas as pd import numpy as np import requests
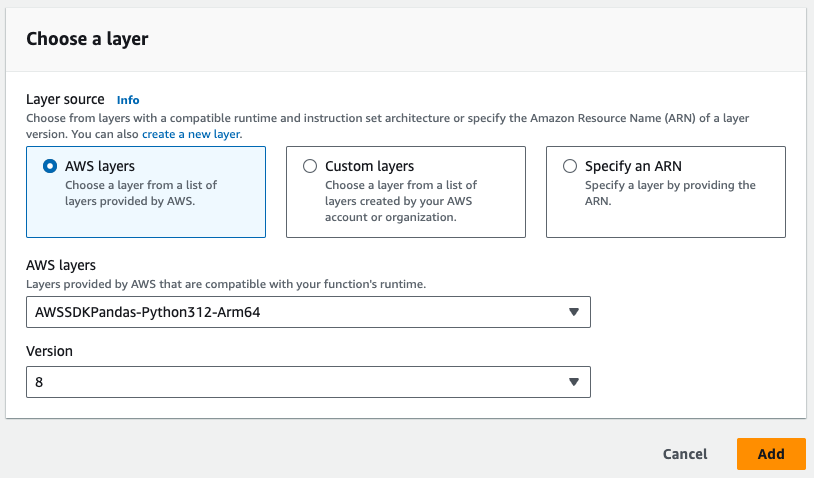
# MEGJEGYZÉS Az AWS-ből származó pandas rétegnek szüksége lesz a következőkre
# hozzá kell adni a Lambda függvényhez
def lambda_handler(event, context): auth_header = OBTAIN FROM API AUTH header = {'Authorization' : auth_header} base_url = 'https://[INSTANCE].tulip.co/api/v3' offset = 0 function = f'/tables/[TABLE_ID/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=header) df = pd.DataFrame(r.json()) length = len(r.json()) while length > 0: offset += 100 function = f'/tables/[TABLE_ID/records?limit=100&offset{offset}&includeTotalCount=false&filterAggregator=all' r = requests.get(base_url+function, headers=cdm_header) length = len(r.json()) df_append = pd.DataFrame(r.json()) df = pd.concat([df, df_append], axis=0) df.shape # ez 100 rekordot csatol egy adatkerethez, és ezután felhasználható S3, Firehose stb. számára # használja az adatváltozót az S3-ra, Firehose-ra való íráshoz,
# adatbázisokba, és így tovább ```
- A kiváltó futhat időzítőn vagy URL-en keresztül kiváltható
- Figyeljük meg az alábbi képen a Pandas réteget, amelyre szükség van
- Végül adjon hozzá bármilyen szükséges integrációt. Lambda függvényekből írhatja az adatokat adatbázisba, S3-ba vagy értesítési szolgáltatásba.
Felhasználási esetek és következő lépések
Miután véglegesítette az integrációt a lambdával, könnyen elemezheti az adatokat egy sagemaker notebookkal, a QuickSighttal vagy számos más eszközzel.
1. Hibák előrejelzése- A gyártási hibák azonosítása, mielőtt azok bekövetkeznének, és a helyes első alkalommal történő javítás növelése - A minőséget befolyásoló alapvető gyártási tényezők azonosítása a fejlesztések végrehajtása érdekében.
2. Minőségi költségek optimalizálása- A terméktervezés optimalizálásának lehetőségeinek azonosítása a vevői elégedettség befolyásolása nélkül.
3. Termelési energiaoptimalizálás- Az optimális energiafogyasztás érdekében a termelésben alkalmazott mozgatórugók azonosítása.
4. Szállítási és tervezési előrejelzés és optimalizálás- A gyártási ütemezés optimalizálása a vevői kereslet és a valós idejű rendelési ütemezés alapján.
5. Globális gép/sor teljesítményértékelés- Hasonló gépek vagy berendezések teljesítményértékelése normalizálással.
6. Globális / regionális digitális teljesítménymenedzsment- Konszolidált adatok valós idejű műszerfalak létrehozásához.