
This feature is only available on "Enterprise" plans and above.
Diagrama de exportación e importación
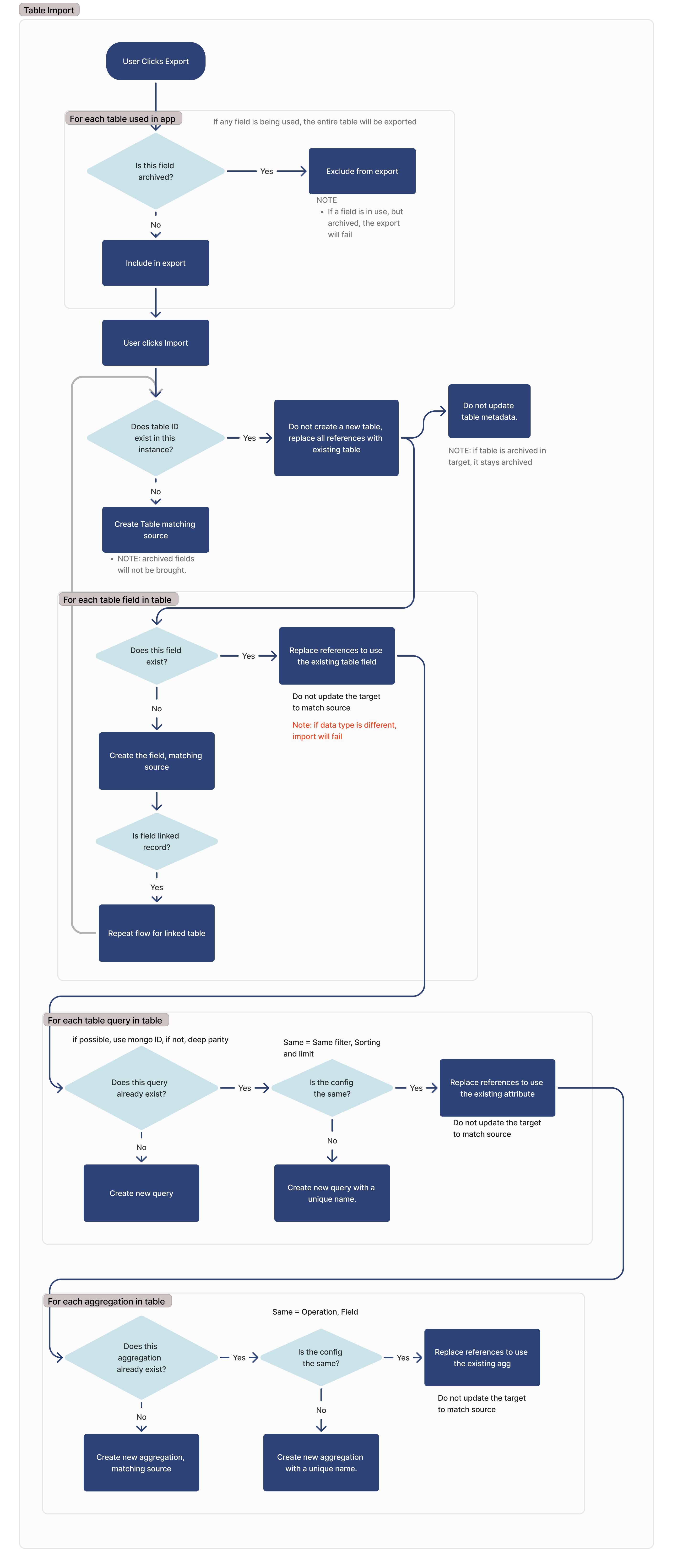
A continuación se muestra el flujo de transferencia completo para las tablas, consultas y agregaciones de Tulip. Este documento proporcionará una explicación detallada de este flujo.
Campos de Usuario Personalizados y Tablas de Actividad de Máquinas
El flujo descrito a continuación también se aplica a cómo se exportan e importan las tablas de campos de usuario personalizados y las tablas de campos de actividad de máquina.
Exportar
Durante el proceso de exportación, la aplicación o automatización exportada informará de cada tabla en uso dentro de esa aplicación. Se considera que una tabla está en uso si se cumple alguna de las siguientes condiciones:
- Se muestra en un widget "Registro de tabla
- Se utiliza en un widget de entrada
- Se muestra en una tabla interactiva
- Se utiliza en un activador
- Se utiliza en una acción de automatización
- Utilizado en un bloque de eventos de automatización
- Se utiliza en un filtro para una consulta de tabla, una tabla interactiva o un widget de análisis
- Utilizado como entrada o salida de un widget personalizado
Si un campo está archivado, no se exportará. Si un campo está archivado pero en uso, la exportación fallará.
Importar
Archived table fields will not be exported, and any references to those fields within applications will need to be remapped on import.
Buscar una misma tabla
Para identificar tablas coincidentes en la importación, buscamos IDs coincidentes. Si se encuentra una tabla con el mismo ID, no creamos una nueva tabla y nos basamos en la existente.
Si la tabla en el sitio de importación está archivada, permanecerá archivada.
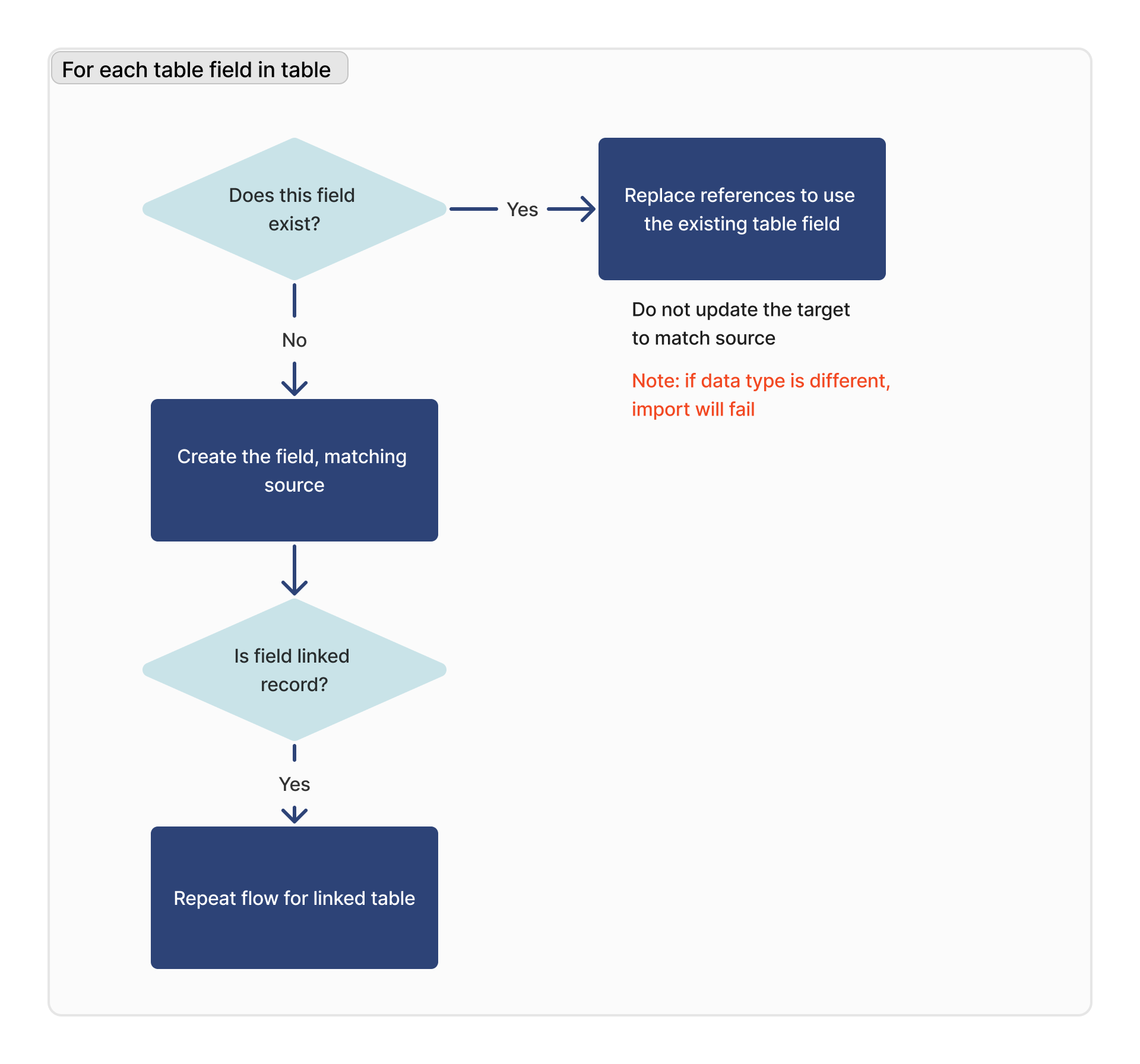
Para cada campo de tabla
Para cada campo de tabla, buscamos un campo coincidente basado en el ID de columna de ese campo respectivo.
Si el tipo de datos del campo coincidente es diferente, la importación fallará.
Si el campo es un campo de registro vinculado, la tabla vinculada se añadirá a la lista de dependencias para la importación, y este flujo se repetirá para esa tabla.
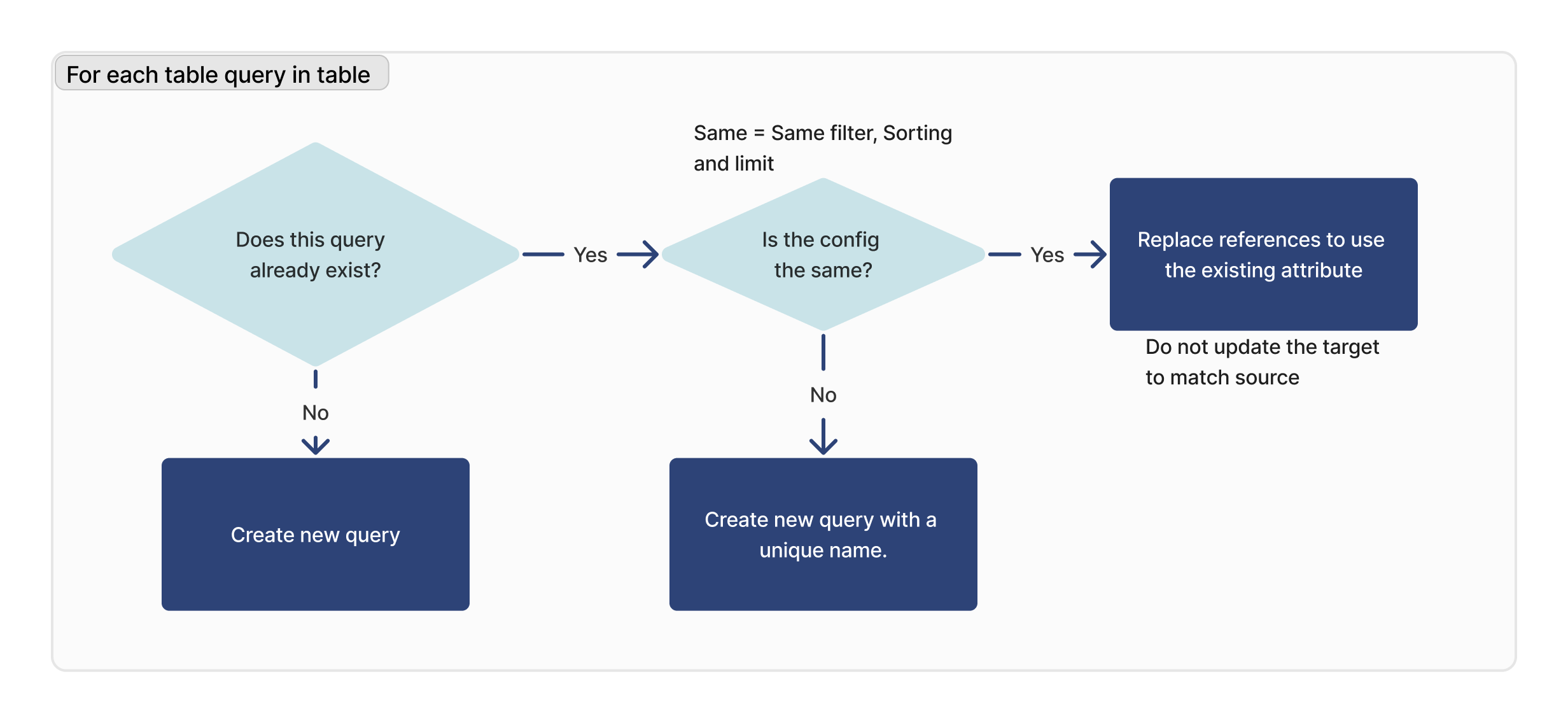
Para cada consulta
Para cada consulta de la tabla importada, comprobamos si existe. Si se encuentra un ID coincidente, verificamos que la configuración sea idéntica (límite, ordenación y filtrado) entre el destino y el origen.
Si no se encuentra una consulta coincidente, se creará una nueva. Si se encuentra una consulta coincidente, pero no es idéntica a la instancia de destino, se creará una nueva consulta con un nuevo nombre.
Nota: Esto no se aplica a los campos de usuario personalizados ni a las tablas de actividad de las máquinas.
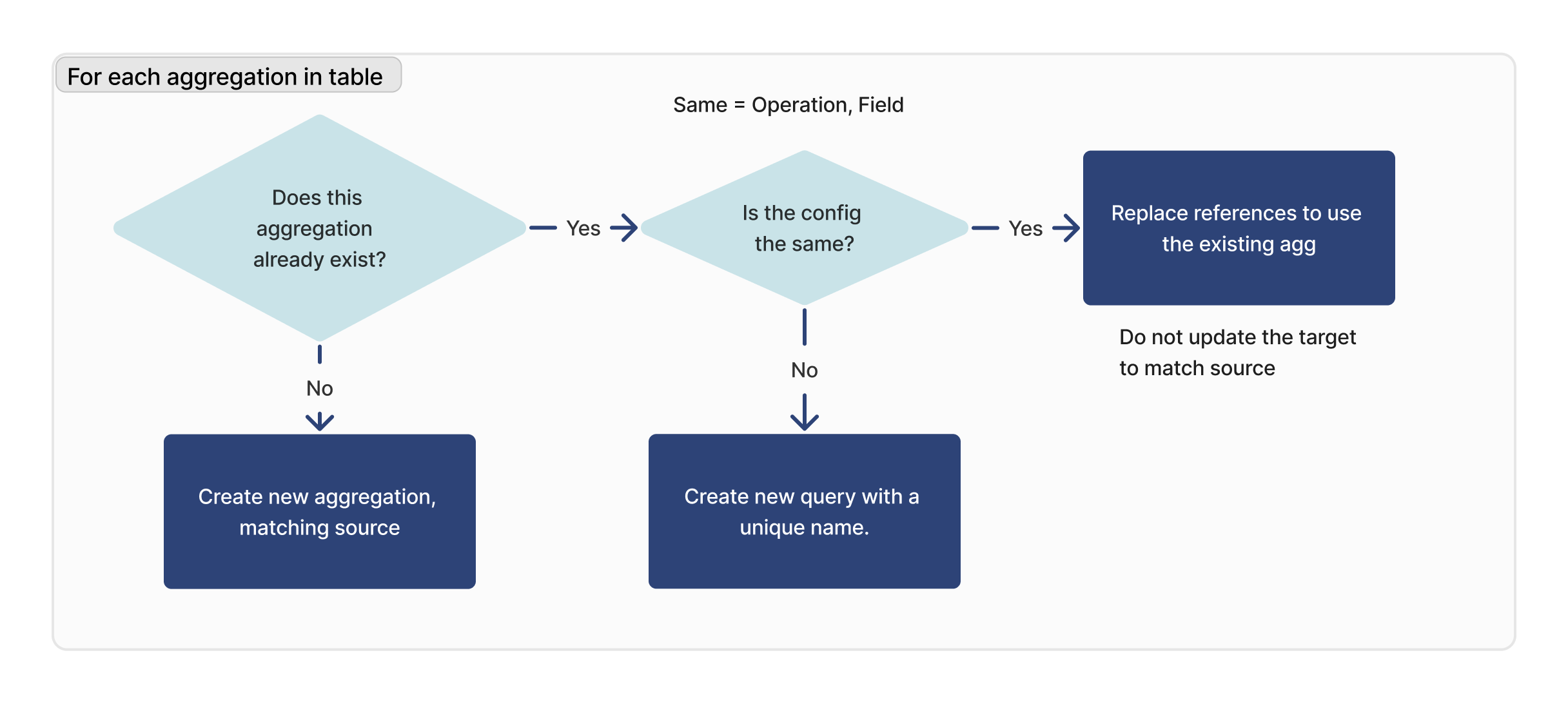
Para cada agregación
Para cada agregación en la tabla importada, comprobamos si existe esa consulta. Si se encuentra un ID coincidente, verificamos que la configuración sea idéntica (operación, campo) entre el destino y el origen.
Si no se encuentra una consulta coincidente, se creará una nueva. Si se encuentra una consulta coincidente, pero no es idéntica a la instancia de destino, se creará una nueva consulta con un nuevo nombre.
Nota: Esto no se aplica a los campos de usuario personalizados ni a las tablas de actividad de las máquinas.