
Korzystanie z funkcji migawki Vision z zewnętrzną usługą OCR
Przechwytywanie i wysyłanie obrazów do zewnętrznego interfejsu API usługi wizji komputerowej
While you can accomplish this with Vision - another alternative is to use CoPilot. Read more about CoPilot and OCR here.
Przegląd
Funkcja Snapshot Vision może być używana w połączeniu z Tulip Connectors i zewnętrzną usługą OCR. W tym artykule dowiesz się, jak szybko zbudować solidny potok OCR (Optical Character Recognition), który wykrywa tekst z migawki wykonanej za pomocą kamery Vision. Wykorzystując tę funkcjonalność, będziesz mógł skanować dokumenty, odczytywać tekst z wydrukowanych etykiet, a nawet tekst wytłoczony lub wytrawiony na przedmiotach.
W poniższym artykule omówimy, jak korzystać z tej funkcji za pomocą Google Vision OCR. Funkcja Google Vision OCR jest w stanie odczytać tekst w bardzo trudnych warunkach obrazu.
Kroki, przez które przeprowadzi Cię ten artykuł:
- Konfiguracja Tulip Vision i Google Cloud Vision API
- Jak utworzyć Tulip Connector do interfejsu API GCV
- Tworzenie aplikacji do robienia migawek i komunikowania się z funkcją konektora OCR.
Wymagania wstępne
Konfiguracja migawki wraz z konfiguracją kamery
Upewnij się, że pomyślnie skonfigurowałeś konfigurację kamery Vision i znasz funkcję Snapshot Vision. Aby uzyskać więcej informacji, zobacz: Korzystanie z funkcji Vision Snapshot
Włącz Google Cloud Vision API i projekt Google Cloud Platform
Utwórz projekt GCP i włącz interfejs Vision API, postępując zgodnie z instrukcjami podanymi w tym artykule: https://cloud.google.com/vision/docs/ocr.
Utwórz klucz API na Google Cloud Platform, który będzie używany do uwierzytelniania
Postępuj zgodnie z instrukcjami podanymi w artykule: https://cloud.google.com/docs/authentication/api-keys, aby utworzyć klucz API dla swojego projektu GCP. Możesz ograniczyć użycie tego klucza API i ustawić odpowiednie uprawnienia. Skonsultuj się z menedżerem sieci, aby pomóc Ci to skonfigurować.
Tworzenie funkcji konektora Tulip dla Google OCR
Utworzony konektor i funkcja konektora zostaną skonfigurowane tak, aby pasowały do typu żądania oczekiwanego przez Vision API, jak pokazano na poniższym obrazku:
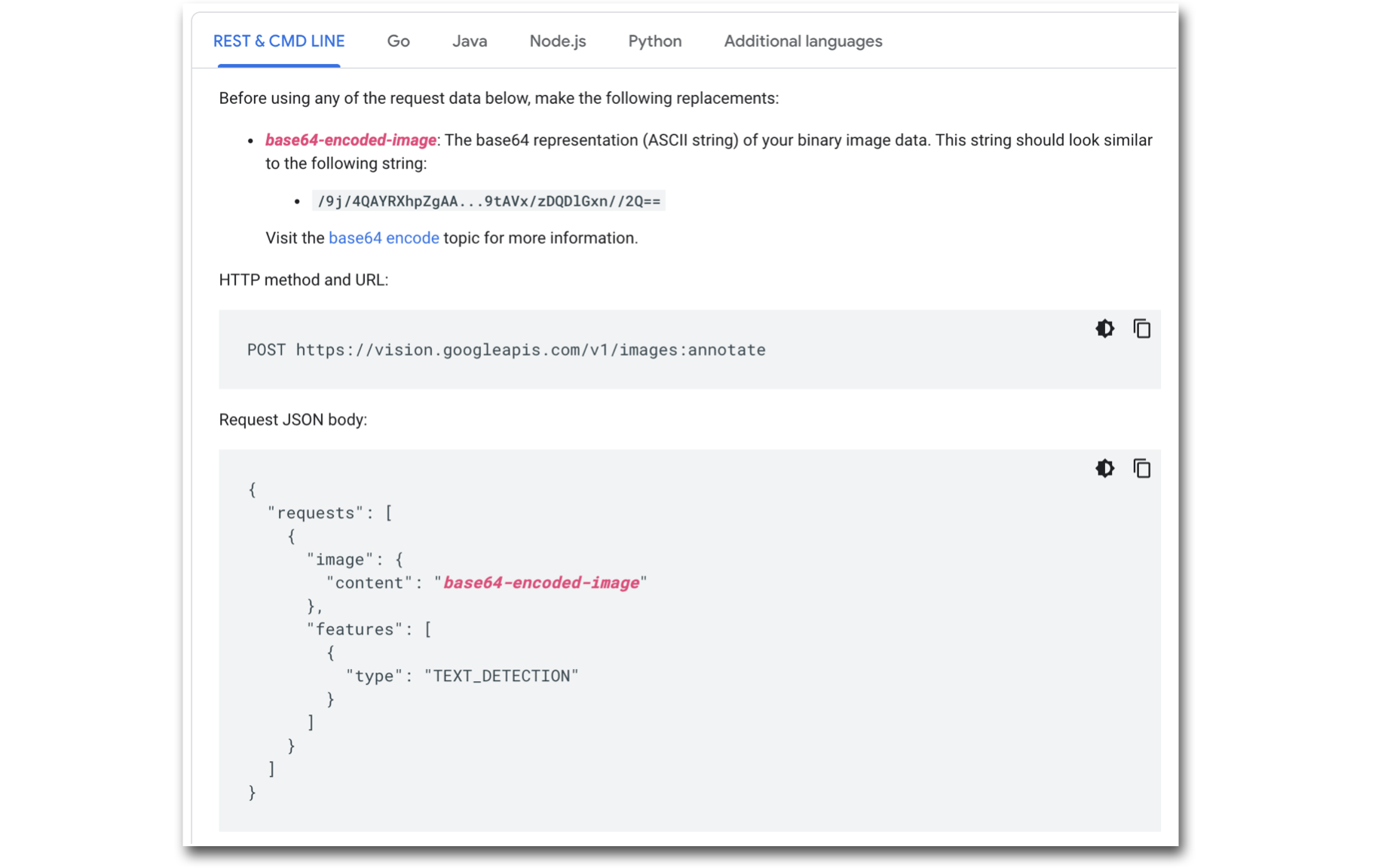
Konfigurowanie funkcji konektora:
- Utwórz konektor HTTP.
- Skonfiguruj konektor tak, aby wskazywał punkt końcowy Google Vision API.
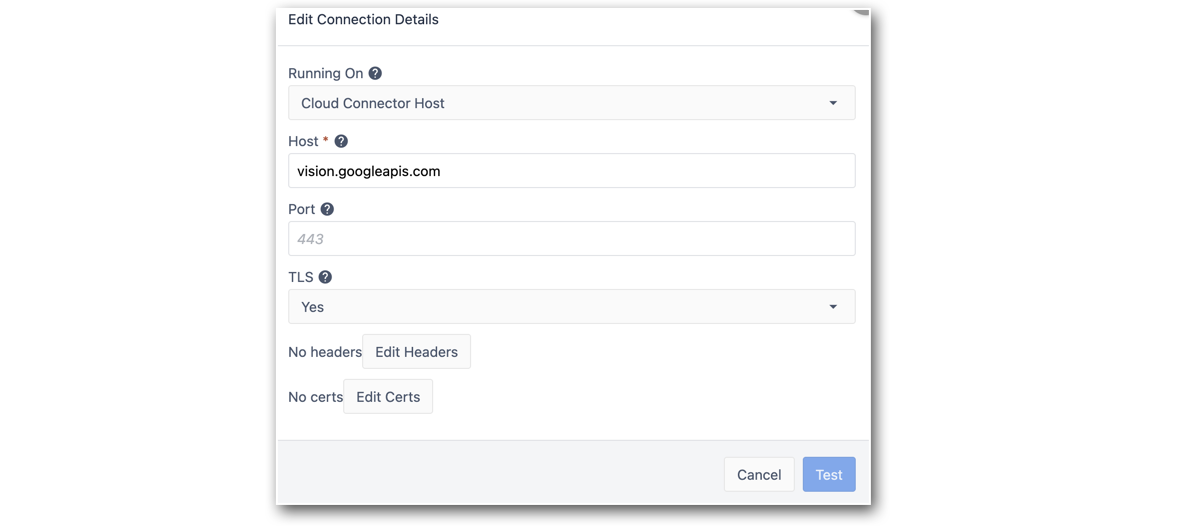
Host: vision.googleapis.com
TLS: Tak3. Edytuj nagłówki połączenia, aby uwzględnić Content-Type.
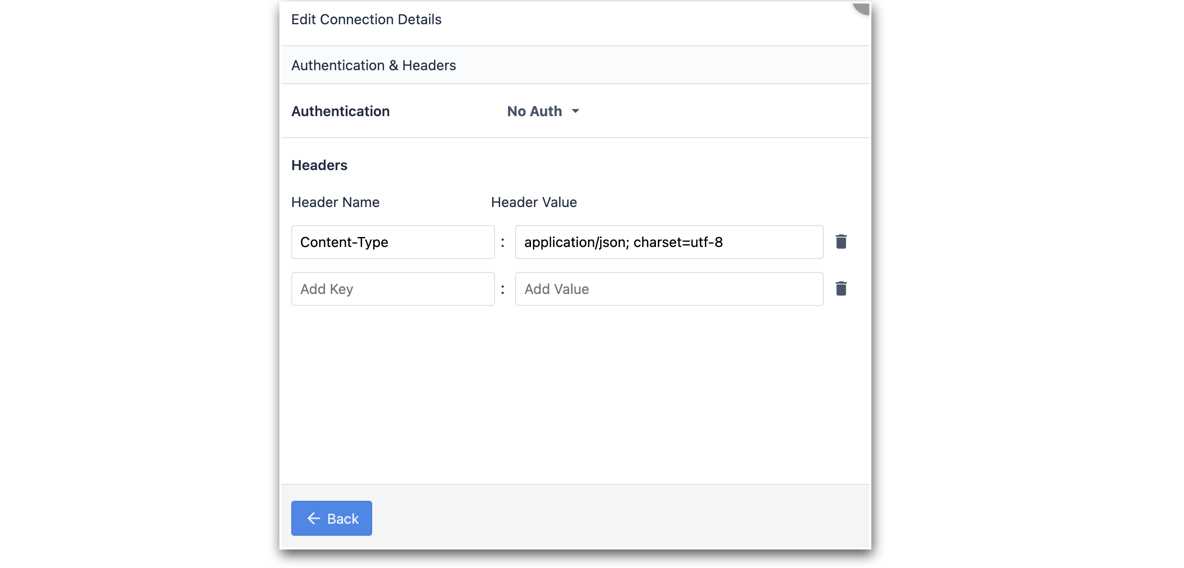
- Przetestuj Connector i zapisz konfigurację.
- Następnie utwórz funkcję konektora żądania POST i dodaj następującą ścieżkę do punktu końcowego: v1/images:annotate
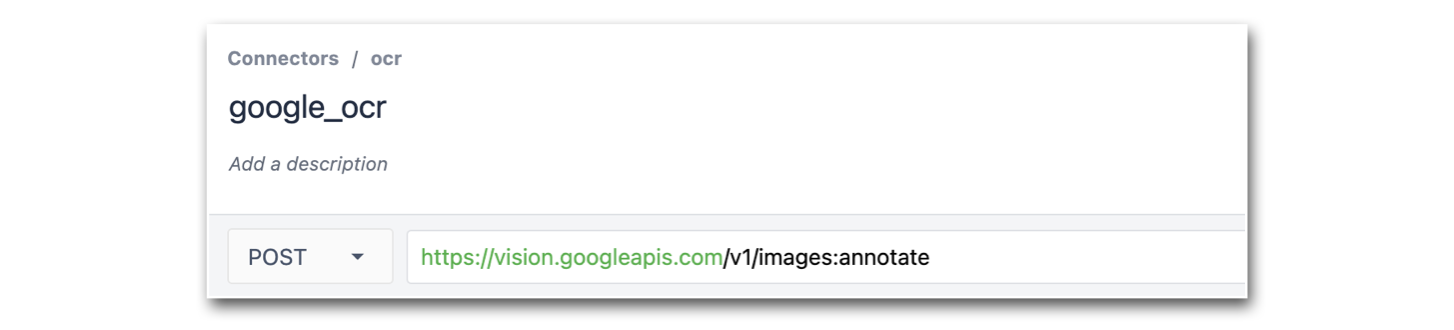
- Dodaj obraz jako dane wejściowe do funkcji łącznika. Upewnij się, że typ danych wejściowych to Text.

- Upewnij się, że typ żądania to JSON, a treść żądania jest zgodna z typem żądania Google Vision API:
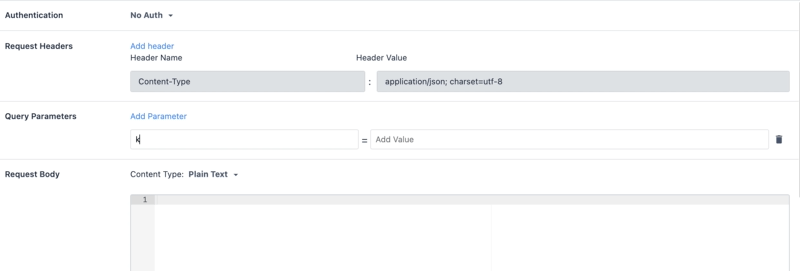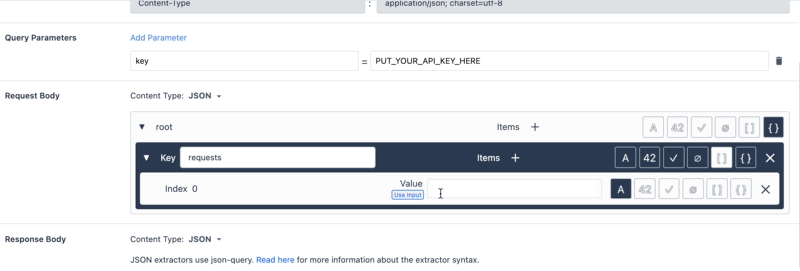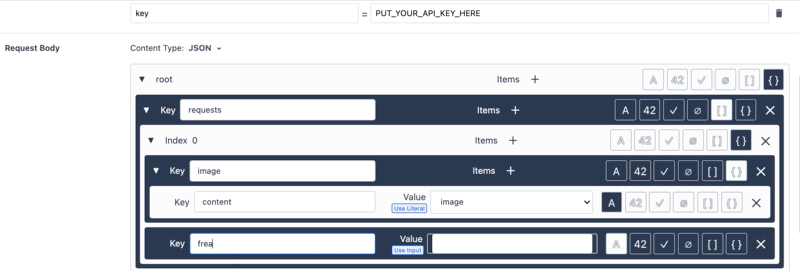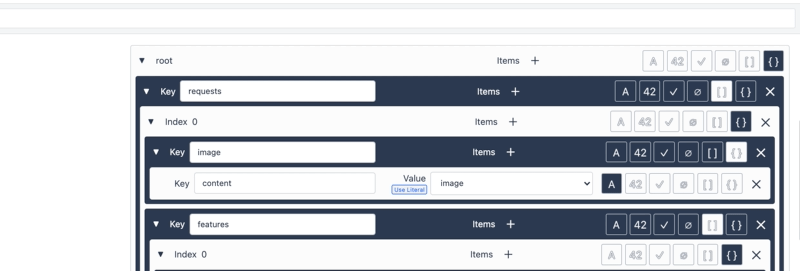
Uwaga: Zastąp PUT_YOUR_API_KEY_HERE własnym kluczem API utworzonym w powyższych krokach.8. Następnie przetestuj tę funkcję łącznika, konwertując obraz tekstu na ciąg base64string (aby to zrobić, możesz skorzystać z tej strony internetowej). Użyj tego ciągu jako wartości testowej dla zmiennej wejściowej obrazu.
Powinieneś otrzymać odpowiedź podobną do:
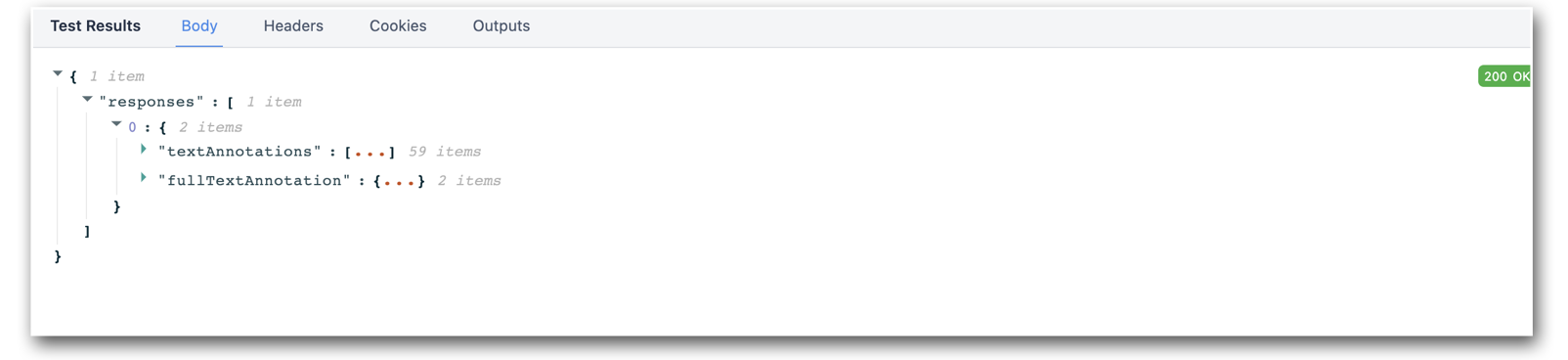
- Ustaw zmienną wyjściową tak, aby wskazywała na**.responses.0.textAnnotations.0.description**
- Zapisz funkcję łącznika.
Tworzenie aplikacji Tulip wykorzystującej Snapshots i Google OCR Connector
- Przejdź do edytora aplikacji i użyj aplikacji utworzonej podczas konfigurowania wyzwalacza migawki: Korzystanie z funkcji migawki
- Następnie utwórz przycisk z wyzwalaczem, aby wywołać funkcję konektora. Użyj zmiennej obrazu, która jest przechowywana przez wyjście Snapshot jako dane wejściowe do funkcji łącznika.
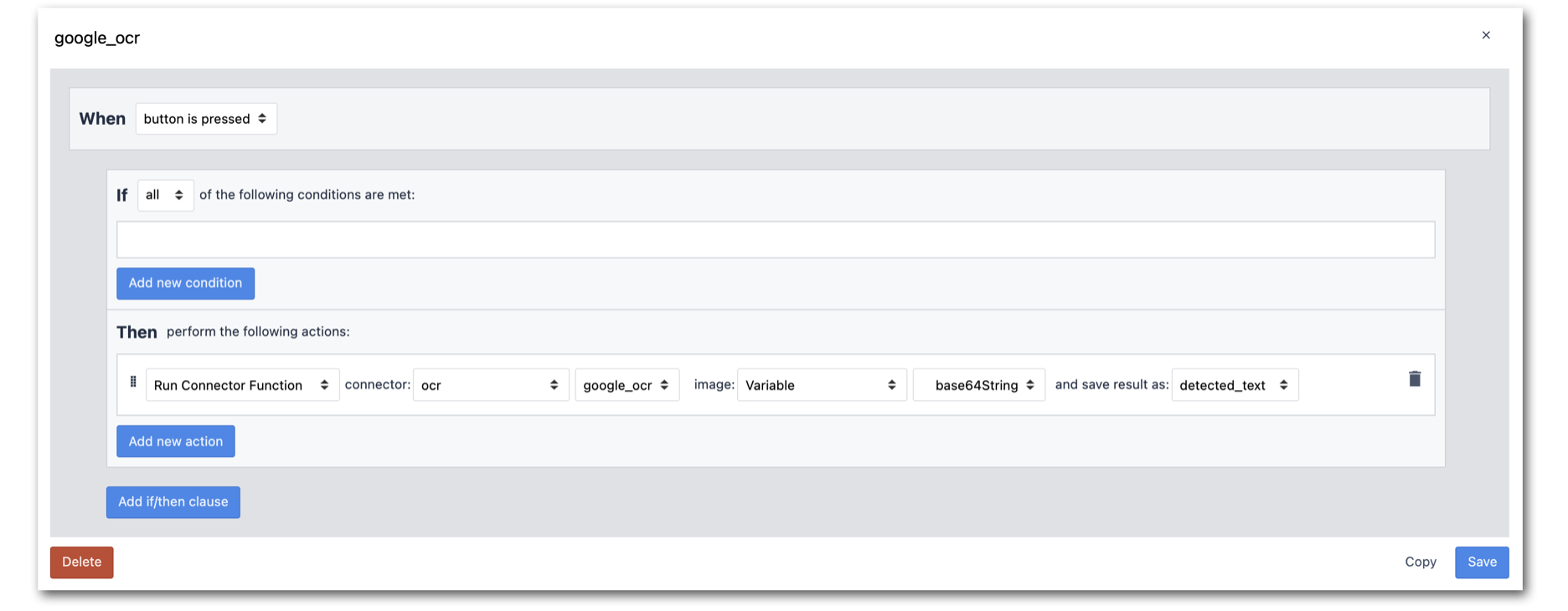
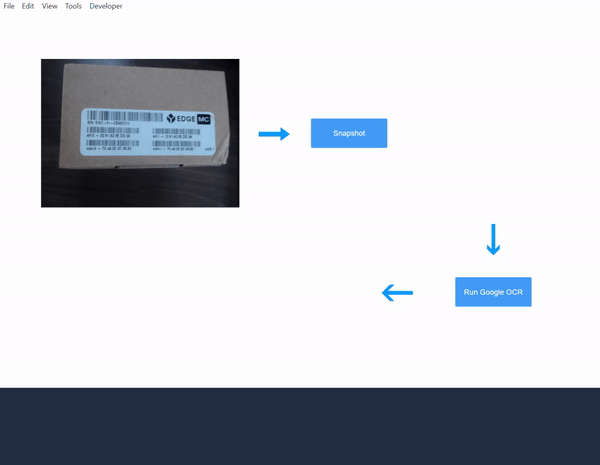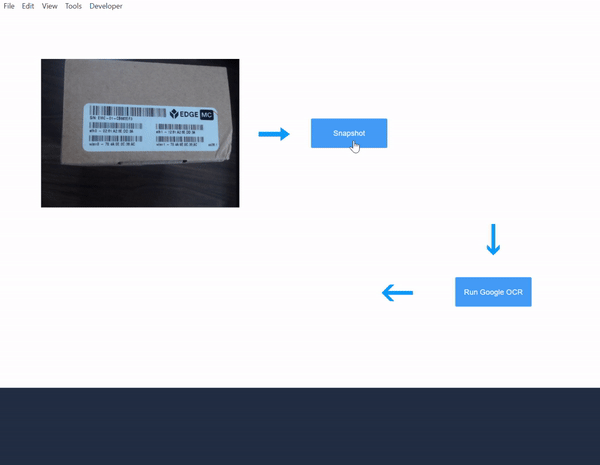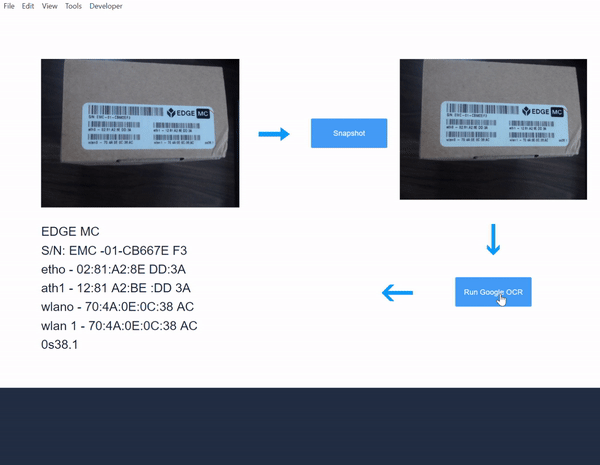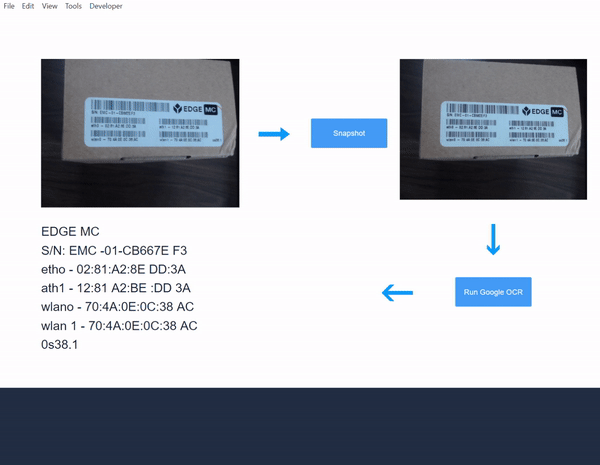
- Dodaj zmienną detected_text do kroku aplikacji, aby wyświetlić wyniki zwrócone przez funkcję konektora:
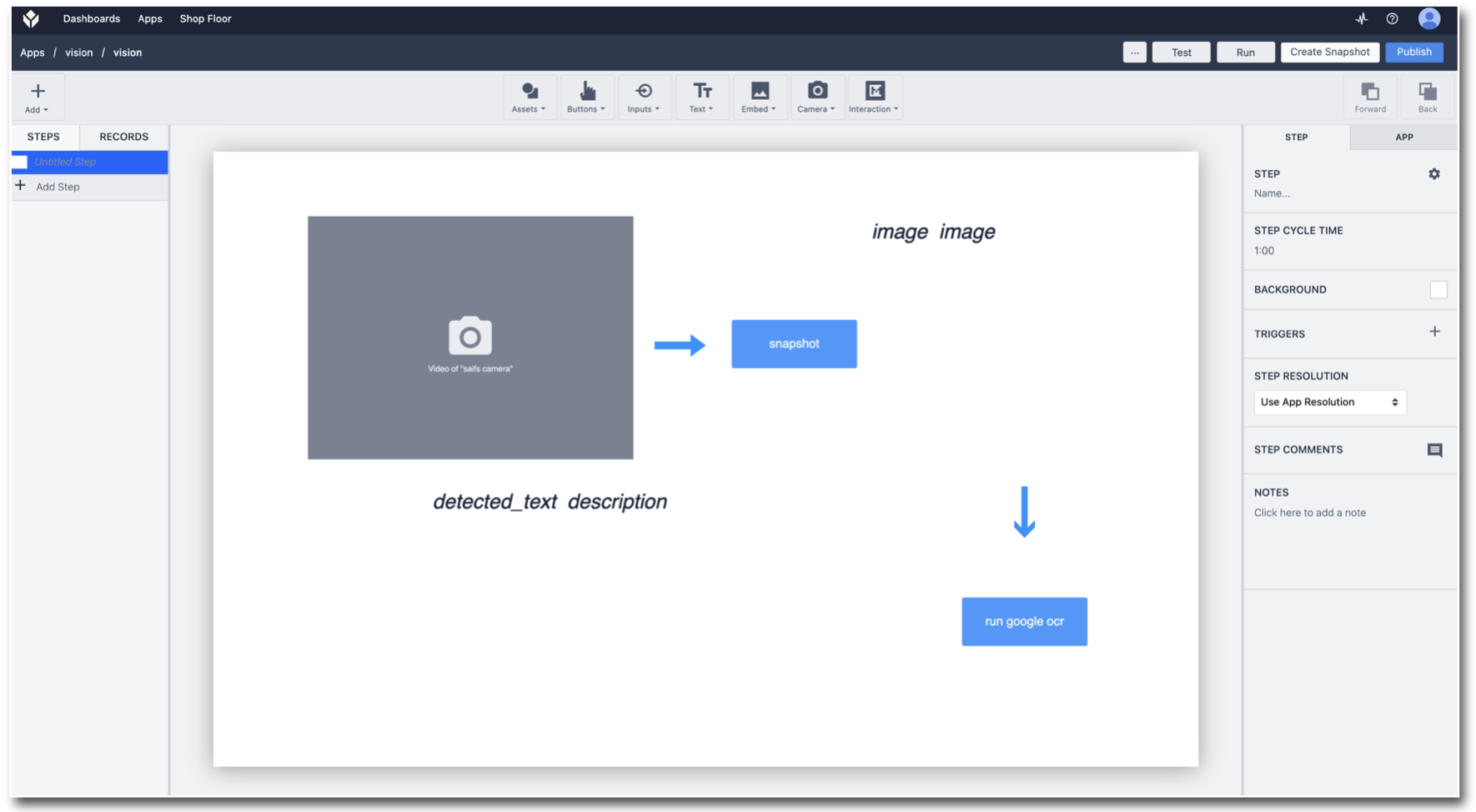
- Przetestuj aplikację i obserwuj wyniki OCR:
Stworzyłeś teraz aplikację Tulip Vision, która łączy się z usługą Google Vision API OCR. Wypróbuj ją teraz w swojej hali produkcyjnej!