

Akcja wyzwalacza Wyodrębnij tekst z obrazu wyodrębnia tekst z obrazu na podstawie zapytania. Innym sposobem na opisanie tego jest "OCR oparty na zapytaniu (optyczne rozpoznawanie znaków)" lub "Wyodrębnij tekst z obrazu, pytając o niego".
Wyzwalacz zawsze zwróci tylko tekst, który jest faktycznie obecny na obrazie. Nie doda do niego dodatkowych informacji ani interpretacji. Sprawia to, że jest on bardzo skuteczny w przenoszeniu danych ze świata fizycznego do cyfrowego.
Przykładowe przypadki użycia:
- Pozyskiwanie danych z formularza zamówienia pochodzącego od zewnętrznego dostawcy. Zapomnij o ręcznym przenoszeniu tego 14-znakowego numeru PO z faktury dostawcy do systemu WMS, połącz prostą aplikację i "Wyodrębnij tekst z obrazu", aby pobrać te dane w ciągu kilku sekund.
- Digitalizacja formularzy papierowych. Dane zawarte na istniejących papierowych dokumentach są jeszcze bardziej wartościowe, gdy można uzyskać do nich dostęp w aplikacjach Tulip. Akcje "Wyodrębnij tekst z obrazu" to świetny mechanizm łączący świat fizyczny i cyfrowy.
- Niezawodna praca z tekstem w językach obcych dla operatorów. Świat produkcji jest globalny, daj swoim operatorom supermoce, łącząc akcje wyzwalające "Wyodrębnij tekst z obrazu" i "Przetłumacz", aby przekształcić informacje papierowe w coś, na czym operatorzy mogą działać.
Przykład wyzwalacza
Użyj aplikacji mobilnej, aby zrobić zdjęcie etykiety na produkcie w celu uzyskania numeru partii.
| Obraz | Wyzwalacz | Wynik |
|---|---|---|
| image.png{height="" width="400"} | image.png{height="" width="400"} | 11EP8F4WA58CCX |
Wyodrębnianie wartości z obrazu
Wejścia i wyjścia
Akcja wyzwalająca ma dwa wejścia, obraz wejściowy i zapytanie, oraz jedno wyjście, wyodrębniony tekst.
Wejście: Obraz wejściowy
Jest to obraz, z którego należy wyodrębnić tekst. Może on pochodzić z widżetu wejściowego kamery, Tulip Vision lub systemów zewnętrznych.
| Obsługiwany typ danych | |
|---|---|
| Wejście | Adres URL obrazu |
Wejście: Zapytanie
Jest to zapytanie używane do wyodrębniania tekstu z obrazu lub dokumentu.
Najlepsze praktyki dotyczące zapytań:* Jeśli to możliwe, użyj słów z dokumentu. Jest to szczególnie pomocne w przypadku akronimów i skrótów (np. SN, ID, SSN, Lot No. itp.). Akcje wyzwalania wyodrębniania tekstu obsługują mniej złożone zapytania niż akcje wyzwalania odpowiedzi na pytanie z danych/dokumentu. * Przykład. Świetne dane wejściowe: "Kto jest dostawcą?" * Przykład. Złe dane wejściowe: "Jak myślisz, kto mógł nam to wysłać? "* Określenie lokalizacji informacji może również pomóc (np. "Jaki jest numer referencyjny na spodzie?").
| Obsługiwany typ danych | |
|---|---|
| Dane wejściowe | Tekst |
Wyjście: Wyodrębniony tekst
Jest to tekst wyodrębniony z obrazu na podstawie zapytania.
| Obsługiwany typ danych | |
|---|---|
| Dane wyjściowe | Tekst |
Wyodrębnianie wartości z obrazu/dokumentu
Extracting values from documents is a relatively slow operation. We limit documents to 10 pages to limit execution time.
Extract Values from Image/Document działa tak samo jak Extract value from image, ale obsługuje tablicę pytań. Będzie to znacznie bardziej wydajne niż uruchamianie akcji wyzwalacza wyodrębniania wartości z obrazu.
Dane wejściowe: Obraz wejściowy/Dokument
Jest to obraz, z którego należy wyodrębnić tekst. Może on pochodzić z widżetu wejściowego kamery, Tulip Vision lub systemów zewnętrznych. W przypadku plików może to być ustawione statycznie, wprowadzone za pomocą widżetu wprowadzania plików lub plików referencyjnych przechowywanych w tabelach.
| Obsługiwany typ danych | |
|---|---|
| Wejście | Adres URL obrazu |
Wejście: Zapytanie
Jest to zapytanie używane do wyodrębniania tekstu z obrazu. Powinna to być tablica/lista wartości tekstowych.
| Obsługiwany typ danych | |
|---|---|
| Wejście | Lista tekstowa |
Wyjście: Wyodrębniony tekst
Jest to tekst wyodrębniony z obrazu na podstawie zapytania.
| Obsługiwany typ danych | |
|---|---|
| Dane wyjściowe | Tablica obiektów. Każdy element będzie miał atrybut "Pytanie" i "Odpowiedź". |
Wyodrębnij cały tekst z obrazu/dokumentu
W niektórych przypadkach paradygmat klucz:wartość akcji wyzwalacza wyodrębniania wartości nie ma sensu dla danego przypadku użycia. Odczytywanie wszystkich danych z obrazu zapewnia niemal nieskończoną elastyczność w rozwiązywaniu problemów przez copilota. Akcje wyzwalające "Wyodrębnij cały tekst" zapewniają taką elastyczność.
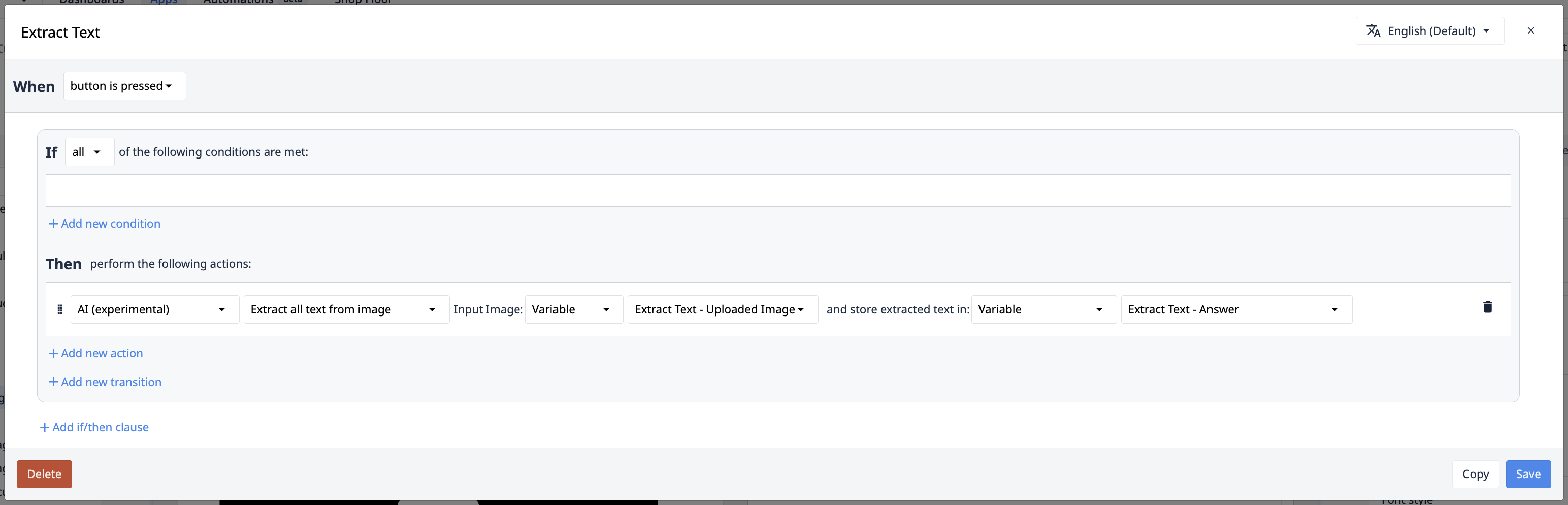
Dane wejściowe: Obraz wejściowy/dokument
Jest to obraz, z którego należy wyodrębnić tekst. Może on pochodzić z widżetu wejściowego kamery, Tulip Vision lub systemów zewnętrznych. W przypadku plików może to być ustawione statycznie, wprowadzone za pomocą widżetu wprowadzania plików lub plików referencyjnych przechowywanych w Tabelach.
| Obsługiwany typ danych | |
|---|---|
| Wejście | Adres URL obrazu lub adres URL pliku |
Wyjście: Wyodrębniony tekst
Jest to cały tekst znaleziony na odpowiednim obrazie lub dokumencie. Documents zwróci tablicę danych, gdzie każdy element reprezentuje tekst z jednej strony dostarczonego dokumentu.
| Obsługiwany typ danych | |
|---|---|
| Dane wyjściowe | (dla obrazów) Tekst. (dla dokumentów) Text List |
Przypadki brzegowe
Brak obrazu wejściowego i/lub zapytania
Jeśli do akcji wyzwalacza nie zostanie dostarczony obraz wejściowy lub zapytanie, aplikacja wyświetli następujący błąd systemowy*:Twoje dane wejściowe lub zapytanie są puste*
Dzieje się tak we wszystkich następujących przypadkach:* Obraz wejściowy i/lub zapytanie wejściowe nie mają przypisanej wartości. Jest to równoważne wartości "null".* Zapytanie ma przypisany pusty ciąg znaków.
Brak wyniku dla zapytania
Jeśli nie można znaleźć wyniku dla zapytania, akcja wyzwalacza zwróci pusty tekst.
Limity
The following languages are the only languages supported for documents where values are being extracted: English, Spanish, Italian, Portuguese, French, German.
Obecnie istnieją następujące limity dla wyzwalaczy "Wyodrębnij tekst z obrazu". Limity te są śledzone na poziomie instancji. W przypadku przekroczenia tych limitów, akcja wyzwalacza "Wyodrębnij tekst z obrazu" zakończy się niepowodzeniem.