

Wyobraź sobie, że jesteś kierownikiem produkcji w branży podlegającej regulacjom prawnym, która musi zapewnić dokładną dokumentację genealogiczną do celów identyfikowalności. Operatorzy spędzają czas na ręcznym zapisywaniu danych procesowych, co wiąże się z dużym prawdopodobieństwem wystąpienia błędów, takich jak nieprawidłowe pomiary, słabe pismo ręczne lub zapomniane pola. Błędy te prowadzą do kwestii zgodności, które mogą być szkodliwe dla całej organizacji. Wprowadzasz cyfrowe rozwiązanie aplikacji procesowych, które przechwytuje dane w standardowych formatach, eliminując typowe rozbieżności. W oddzielnej aplikacji identyfikowalności można sortować i filtrować dane w celu znalezienia trendów, które napędzają usprawnienia procesów. Rozwiązanie to oszczędza czas, pozwala uniknąć podatnego na błędy ręcznego wprowadzania danych i tworzy przejrzyste, identyfikowalne dane dla klientów i kontroli jakości.
Genealogia i identyfikowalność pozwalają zakładowi produkcyjnemu zobaczyć kontekst konfiguracji powykonawczej. W przypadku produkcji dyskretnej może to obejmować numery części, numery seryjne, numery partii nieserializowanych części i surowców, z których składają się podzespoły i zespoły końcowe. Ten przypadek użycia obejmuje pobranie wszystkich danych przechwyconych podczas procesu kompilacji i przechowywanie ich do przeglądu wraz z metadanymi (kto co zrobił, kiedy, wszelkie kontrole potwierdzające).

Dwa główne cele tego przypadku użycia to: 1. Przechwytywanie zgodnych z przepisami branżowymi zapisów genealogicznych dostępnych dla klienta końcowego i/lub audytoraPonieważ zgodność z przepisami jest regulowana w produkcji, jest to istotny element działalności. Możesz skompilować pełną ścieżkę audytu za pomocą rozwiązania cyfrowego, które minimalizuje wysiłek przy jednoczesnym spełnieniu niezbędnych standardów.
- Cyfrowaidentyfikowalnośćproduktu od produkcji do wysyłki zapewnia odpowiedzialność. Poniższy wykres pokazuje, w jaki sposób cyfrowa identyfikowalność może przynieść korzyści w różnych scenariuszach produkcyjnych:
| Scenariusz | Korzyści z cyfrowej identyfikowalności | | --- | --- | | Praca standardowa: Produkt przechodzi przez partie materiałów i podzespoły | Metadane aplikacji (uzupełnienia) automatycznie przechowują dane, w tym informacje o operatorze, czasy dat, wszelkie wybrane wartości | | Przeróbka: produkt lub komponent wymaga dodatkowej uwagi, zanim będzie można go użyć w montażu | Niezmienne dane zapewniają pełną historię części na jednym etapie w celu łatwego odniesienia | | Klient prosi o zapisy dotyczące określonego produktu | | Odzyskaj wszystkie istotne dane produktu, które są przechowywane cyfrowo za pomocą aplikacji | | Wycofanie gwarancji lub problem z partią zidentyfikowany przez dostawcę | | Personel ds. jakości może wyszukiwać i pobierać listę produktów, które wykorzystywały odpowiednią wadliwą część |
Wpływ i wymagania
Cyfrowe i tradycyjne metody genealogiczne dają ten sam rezultat, ale rozwiązanie cyfrowe oferuje łatwiejszą i bardziej automatyczną identyfikowalność. Jeśli obecnie korzystasz z aplikacji do śledzenia produkcji w swoim procesie, to już przechwytujesz ważne dane dla genealogii. Rozwiązanie cyfrowe gromadzi odpowiednie dane dla każdej partii, a następnie wyświetla je w razie potrzeby, aby zapewnić pełną historię.
Główne cele genealogii dotyczą zgodności z następującymi metodami: * Obniżenie kosztów zgodnościObsługa i analiza danych oraz ograniczenie błędów ludzkich dzięki zautomatyzowanemu gromadzeniu danych * Uproszczenie procesu w celu zapewnienia identyfikowalnościPrzygotuj dane i udostępnij je tym, którzy ich potrzebują, dzięki cyfrowemu przechowywaniu * Otwórz się na ulepszeniaprocesu Wykorzystaj trendy danych, aby zidentyfikować problemy, gdy się pojawią, i kluczowe obszary, które w rezultacie można poprawić.
Dostępność danych jest kluczowym czynnikiem umożliwiającym osiągnięcie tych celów. Możesz wyszukiwać, filtrować i udostępniać informacje z łatwością i mniejszą liczbą błędów niż w przypadku standardowego procesu papierowego. Różne osoby wymagają danych w różnych kontekstach, takich jak przegląd jakości lub identyfikacja trendów w operacjach.
Dodatkową korzyścią jest to, że zgodność z przepisami prowadzi również do zwiększenia jakości produktów. Obejmuje to szybką identyfikację i ponowną obróbkę towarów w toku, na które wpłynęło przekroczenie jakości. Wyższa rentownośćZwiększenie ROI i ogólnych przychodów przy jednoczesnym zmniejszeniu kosztów obsługi wynikających z wad * Zmniejszenieryzyka Uniknięcie niepowodzeń i potencjalnych kar, które mogą wynikać z wadliwych produktów.
Genealogia jest istotna dla wszystkich branż i wymagana w branżach regulowanych. Ten przypadek użycia ma niską/średnią złożoność, w zależności od konkretnej operacji. Na przykład wielopoziomowe przetwarzanie wsadowe wymaga dodatkowej konfiguracji, podczas gdy prosty, dyskretny montaż ma relację 1:1 z aplikacjami, co ułatwia gromadzenie danych. Minimalna konfiguracja obejmuje podstawowe tworzenie aplikacji i gromadzenie danych za pomocą tabel i rekordów ukończenia.
Jak zacząć
Istnieją dwa główne elementy genealogii cyfrowej: 1. Gromadzeniedanych 2. Przeglądanie danych w jednym miejscu
Przejdźmy przez oba, aby zrozumieć, jak wyglądają w tym przypadku użycia.
Zbieranie danych
Użyj kombinacji tabel i uzupełnień do przechowywania danych produktów i procesów.
Tabele
Ponieważ genealogia obejmuje dane zebrane podczas wielu procesów, należy ustanowić skalowalną strukturę tabel. Skalowalna struktura tabel: * Jest zgodna z modelem cyfrowego bliźniaka (tabele odzwierciedlające fizyczne lokalizacje / halę produkcyjną) * Zawiera tabele reprezentujące artefakty fizyczne (np. pozycje magazynowe, sprzęt i aktywa) lub operacyjne (np. zdarzenie defektu, zlecenia pracy) * NIE przechowuje danych podstawowych (danych utworzonych poza operacjami) ani zduplikowanych danych z rekordów ukończenia (metadanych aplikacji).
W architekturze aplikacji struktura tabel jest tym, co łączy każdą aplikację ze sobą. Na poniższym diagramie można zauważyć, że aplikacje (niebieskie kwadraty) nie są ze sobą bezpośrednio połączone. Tabele (zielone diamenty) przenoszą informacje o zleceniach pracy przez produkcję.
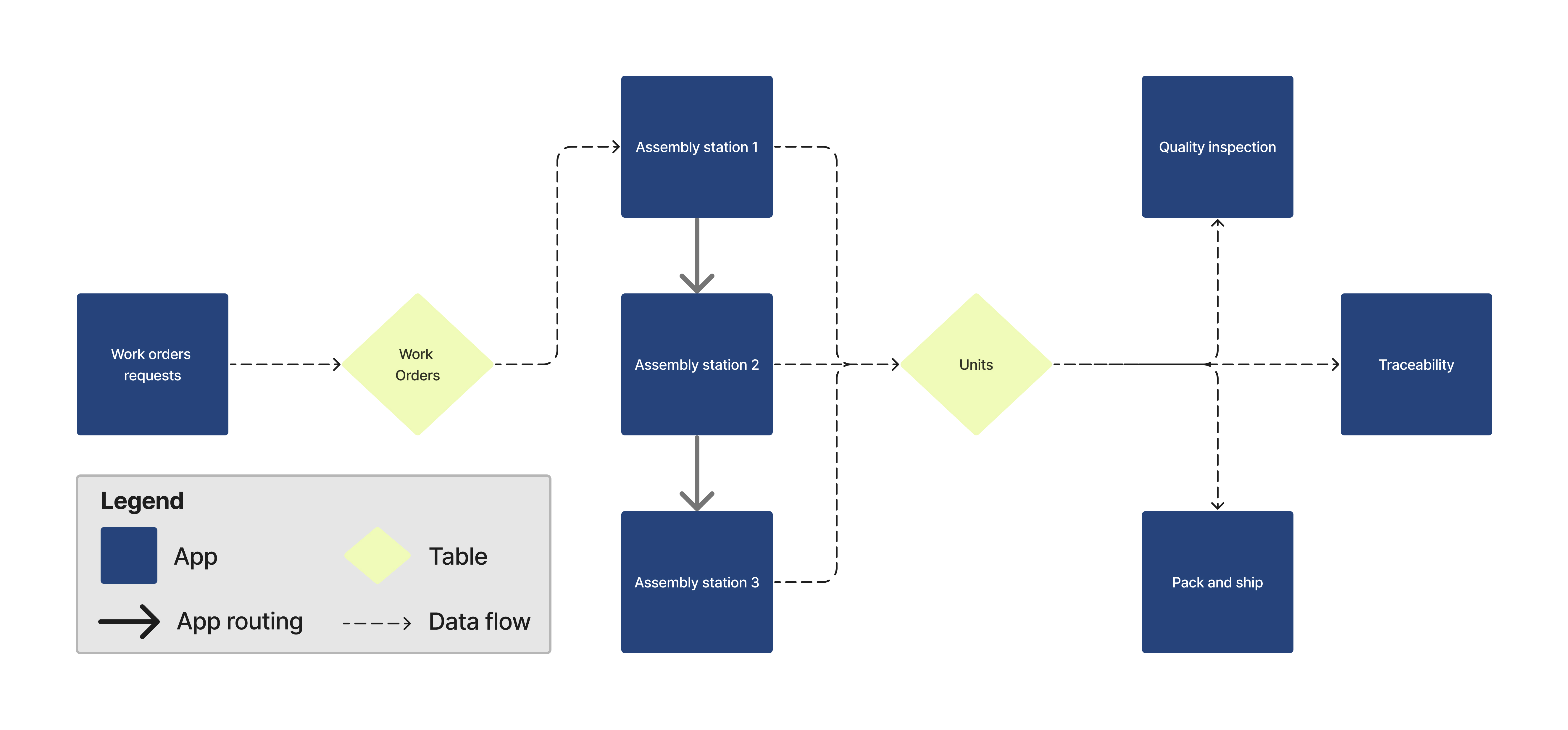
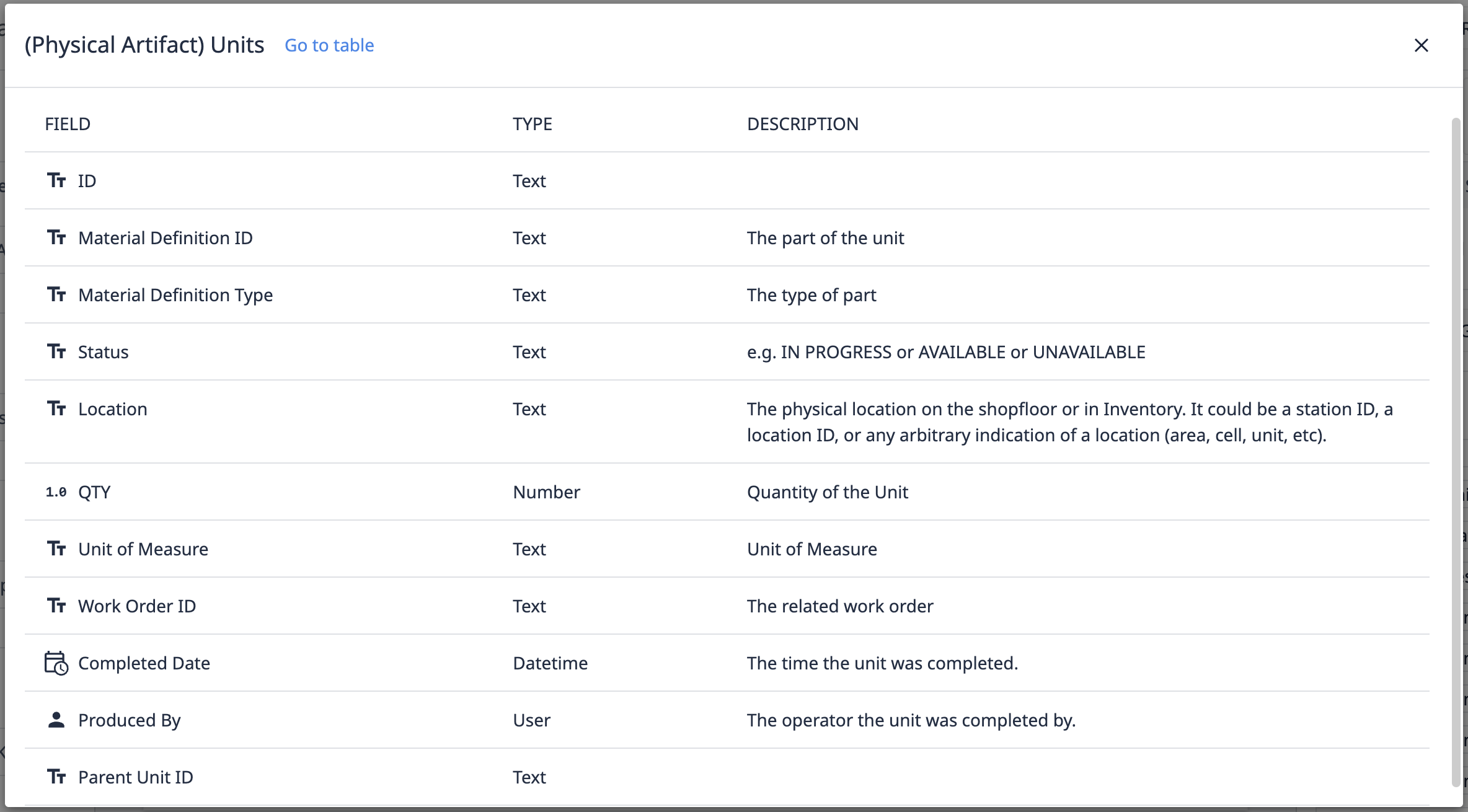
Na tym diagramie zlecenia pracy są przechowywane w tabeli Work Orders. Pierwsza stacja montażowa wykorzystuje informacje o zleceniu pracy, aby je rozpocząć. Każda stacja przechowuje dane dotyczące jednostki w tabeli jednostek. Tabela Units (przykład poniżej) zawiera informacje o każdej jednostce. Rekordy te mogą być następnie wykorzystane w aplikacji identyfikowalności lub innych aplikacjach, takich jak kontrola jakości oraz pakowanie i wysyłka.
Taka architektura zapewnia, że dane są dokładne we wszystkich stacjach i nie znajdują się w wielu lokalizacjach. Ponieważ dane gromadzone na potrzeby genealogii pochodzą z różnych aplikacji procesowych, należy upewnić się, że wyzwalacze zapisują i aktualizują rekordy tabeli w odpowiednich tabelach. Struktura tabeli nie musi być rozbudowana. Możesz użyć lub odnieść się do wspólnego modelu danych Tulip jako punktu wyjścia i dostosować go do swoich konkretnych potrzeb.
Uzupełnienia
Completions przechowują niezmienne metadane aplikacji, ale można także skonfigurować wyzwalacze do zapisywania wartości Variable. Informacje te informują o tym, co wydarzyło się podczas sesji aplikacji. W przypadku genealogii rekordy ukończenia przechwytują informacje o warunkach produkcji.
Należy pamiętać, że rekordy ukończenia są specyficzne dla każdej aplikacji, podobnie jak dziennik. Chociaż nie można używać tych informacji w innych aplikacjach, można wizualizować dane ukończenia za pomocą Analytics.
Wyświetlanie danych genealogicznych w jednym miejscu
Po zebraniu danych z różnych procesów w tabelach prawdopodobnie będziesz chciał wyświetlić informacje o jednostce w osobnej aplikacji. Aplikacja genealogiczna powinna być prosta, aby użytkownicy mogli łatwo uzyskać dostęp do danych.
W przykładowej aplikacji poniżej użytkownik może wybrać jednostkę z interaktywnego widżetu tabeli.

Następnie aplikacja przechodzi do następnego kroku, który wyświetla dane wybranej jednostki w widżecie rekordu tabeli.

Jest to podstawowy projekt aplikacji do wyszukiwania informacji o określonych jednostkach. Aplikację genealogiczną można dostosować do różnych osób w zależności od warunków, których potrzebują do wyszukiwania rekordów.
Poniższa tabela zawiera przykłady dodatkowych funkcji aplikacji, które można rozważyć:
| Scenariusz | Funkcja aplikacji | | --- | --- | Kierownik ds. jakości zauważa powtarzający się problem z wyprodukowaną częścią | Utwórz filtr tabeli dla jednostek, które zostały wyprodukowane w określonym przedziale czasowym | | Sprzedawca wydaje wycofanie jednego z materiałów używanych w produkcji | Utwórz zapytanie do tabeli, które pobiera rekordy zawierające odpowiedni identyfikator materiału | | Klient prosi o wyświetlenie pełnej historii jednostki | Wyeksportuj plik CSV z interaktywnego widżetu tabeli historii jednostki | | Wyeksportuj plik CSV z interaktywnego widżetu tabeli historii jednostki.
Zasoby Tulip
Niezależnie od tego, czy chcesz dowiedzieć się więcej o funkcjach Tulip, aby zbudować aplikację genealogiczną / identyfikowalności, czy też chcesz skorzystać z gotowych szablonów Tulip, mamy narzędzia, które pomogą Ci zacząć.