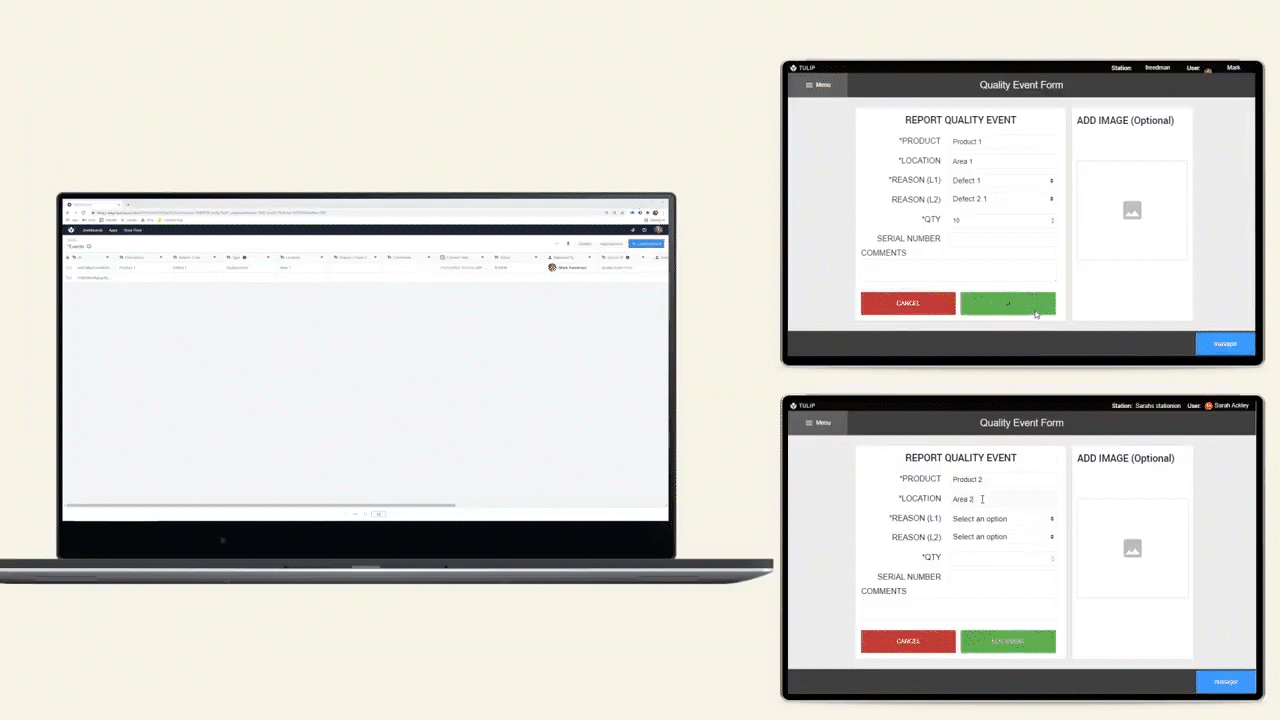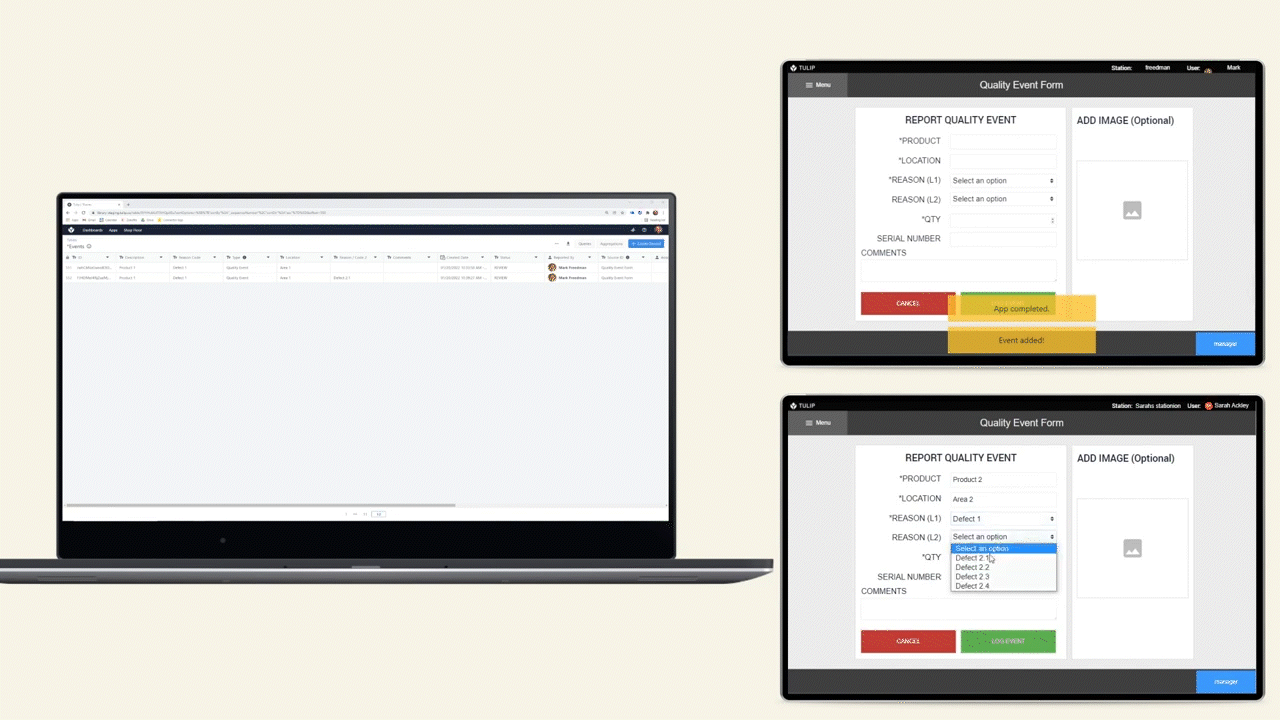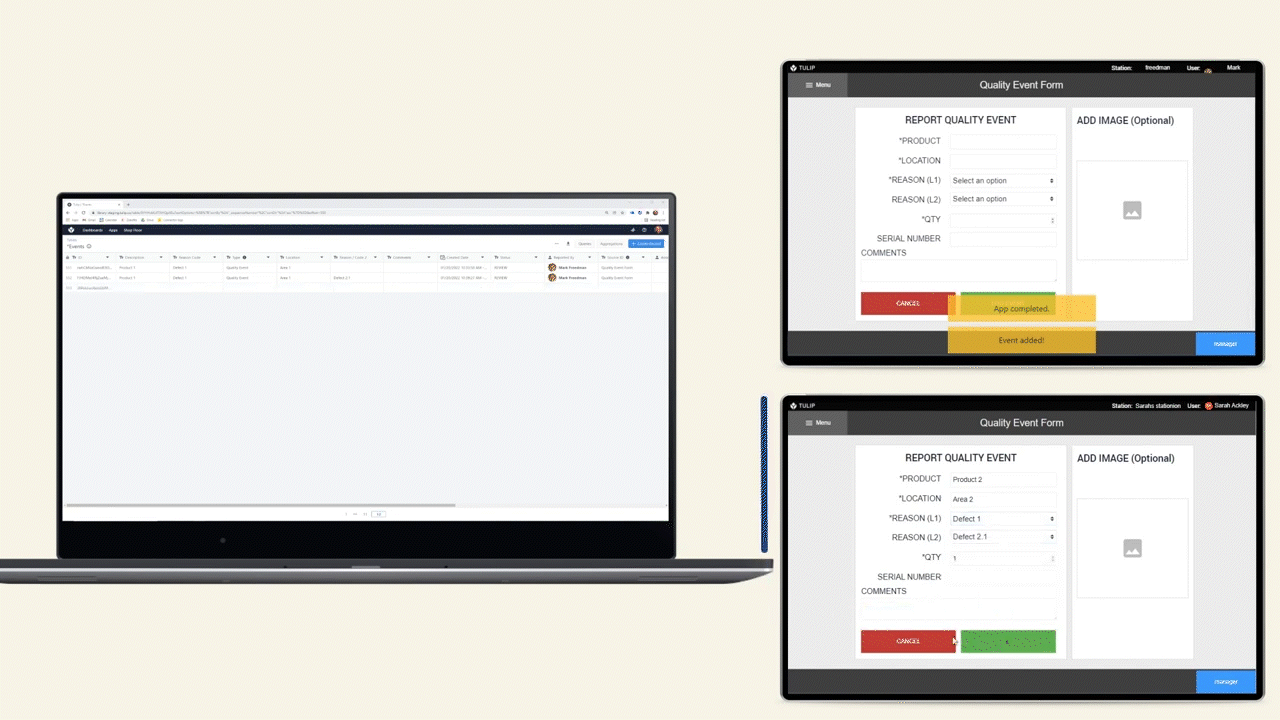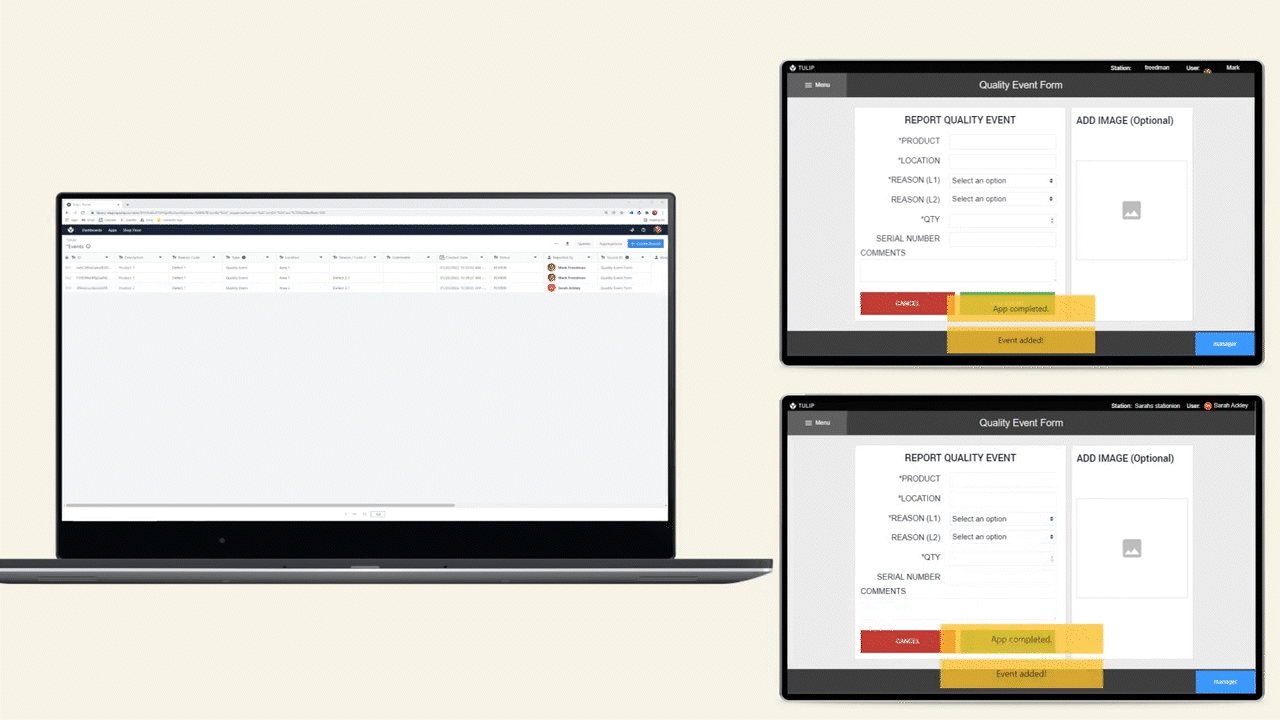
The Extract Text from Image trigger action extracts text from an image based on a query. Another way to describe this is “Query based OCR (optical character recognition)” or “Extract text from an image by asking for it.”
The trigger will always only return text that is actually present in the image. It will not add additional information or interpretation to it. This makes it very powerful for transferring data from the physical into the digital world.
Example use cases:
- Ingest data from an order form coming from an outside vendor. Forget manually transferring that 14 character PO number from a supplier invoice into your WMS, combine a simple app and "Extract Text from Image" to pull this data in seconds.
- Digitize paper forms. The data contained on existing paper travelers is even more valuable when it can be accessed within Tulip apps. "Extract Text from Image" actions are a great mechanism to bridge the physical and digital world.
- Work with text in languages foreign to your operators, reliably. The manufacturing world is global, give your operators superpowers by combining the "Extract Text from Image" and "Translate" trigger actions to turn paper-based information into something your operators can act on.
Trigger example
Use a mobile app to take a picture of a label on a product to get the batch number.
| Image | Trigger | Result |
|---|---|---|
 |
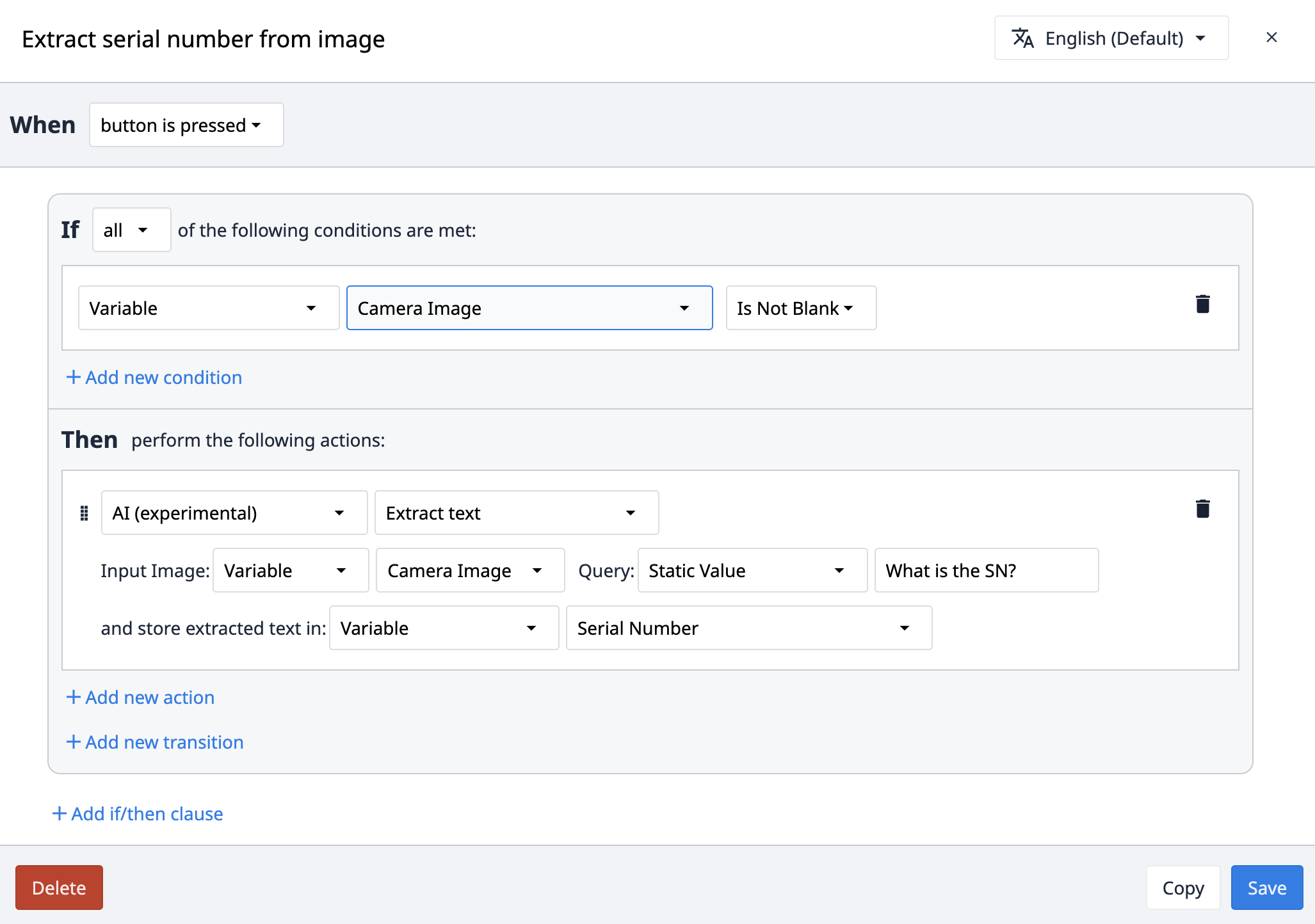 |
11EP8F4WA58CCX |
Extract value from image
Inputs and outputs
The trigger action has two inputs, Input Image and Query, and one output, the extracted text.
Input: input image
This is the image from which the text should be extracted. This can come from the camera input widget, Tulip Vision, or external systems.
| Supported data type | |
|---|---|
| Input | Image URL |
Input: query
This is the query that is used for extracting the text from the image or document.
Query best practices:
- Where possible, use words from the document. This is particularly helpful for acronyms and abbreviations (e.g. SN, ID, SSN, Lot No., etc.). The extract text trigger actions support less complex queries than the Answer Question from Data/Document Trigger actions.
- Ex. Great Input: "Who is the supplier?"
- Ex. Bad Input: "Who do you think could have sent this to us?"
- Specifying the location of information can also help (e.g. “What is the reference number on the bottom?”)
| Supported data type | |
|---|---|
| Input | Text |
Output: extracted text
This is the text that was extracted from the image based on the query.
| Supported data type | |
|---|---|
| Output | Text |
Extract values from image/document
Extracting values from documents is a relatively slow operation. We limit documents to 10 pages to limit execution time.
Extract Values from Image/Document works just like Extract value from image, but supports an array of questions. This will be significantly more performant than running the extract value from image trigger action.
Input: input image/document
This is the image from which the text should be extracted. This can come from the camera input widget, Tulip Vision, or external systems. For files, this can be set statically, input with the file input widget, or reference files stores in Tables.
| Supported data type | |
|---|---|
| Input | Image URL |
Input: query
This is the query that is used for extracting the text from the image. This should be an array/list of text values.
| Supported data type | |
|---|---|
| Input | Text List |
Output: extracted text
This is the text that was extracted from the image based on the query.
| Supported data type | |
|---|---|
| Output | Object Array. Each element will have an "Question" and "Answer" attribute. |
Extract all text from image/document
In some cases, the key:value paradigm of the extract value trigger actions does not make sense for your use case. Reading all data from an image provides nearly infinite flexibility in what problems that can be addressed by copilot. "Extract All Text" Trigger actions provide you this flexibility.
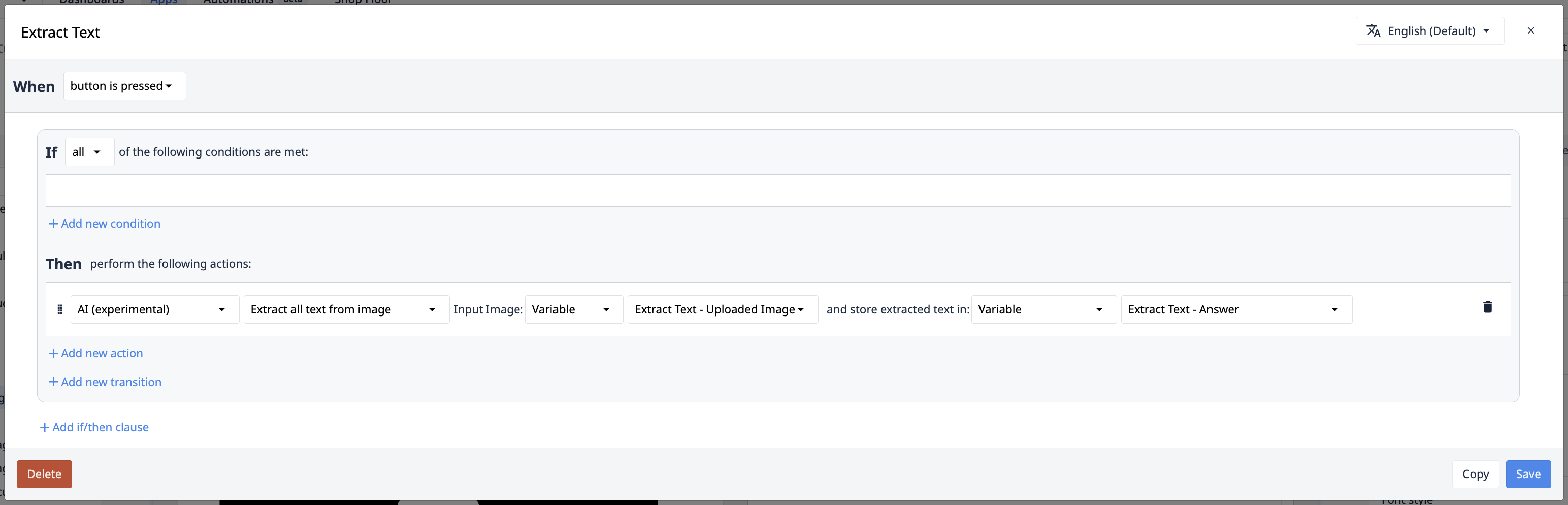
Input: input image/document
This is the image from which the text should be extracted. This can come from the camera input widget, Tulip Vision, or external systems. For files, this can be set statically, input with the file input widget, or reference files stores in Tables.
| Supported data type | |
|---|---|
| Input | Image URL or File URL |
Output: extracted text
This is all of the text found on the respective image or document. Documents will return an array of data, with each item representing the text from one page of the provided document.
| Supported data type | |
|---|---|
| Output | (for images) Text. (for documents) Text List |
Edge cases
No input image and/or no query provided
If no input image or no query is provided to the trigger action, the App will show the following system error:
Your Input or Query is empty
This happens for all of the following cases:
- The input image and/or query input do not have a value assigned. This is equivalent to “null”.
- The query has an empty string assigned.
No result for query
If no result could be found for the query, the trigger action will return an empty text.
Limits
The following languages are the only ones supported for documents where values are being extracted: English, Spanish, Italian, Portuguese, French, German.
These limits are tracked on an Instance level. In a case where these limits have been exceeded, the Extract Text from Image trigger action will fail.
The following limits exist for Extract Text from Image triggers:
| Limit | |
|---|---|
| Image size | 5MB |
| Monthly limit | 10,000 requests per month |
| Rate limit | 10 requests per minute |
| Count of values being extracted | 15 values extracted per action |
For additional limits, including account usage, see Tulip AI usage and pricing.
Did you find what you were looking for?
You can also head to community.tulip.co to post your question or see if others have solved a similar topic!