

개요
XML 기반 API 작업을 위한 팁과 요령이 담긴 가이드
튤립 커넥터는 다양한 유형의 외부 데이터 소스와 상호 작용하는 데 사용할 수 있습니다. 이 문서에서는 XML을 사용하여 정보를 교환하는 HTTP API에 초점을 맞춥니다. 이 범주에는 SOAP API도 포함됩니다.
Tulip에서 XML 데이터 보내기
요청 본문에 XML 콘텐츠를 보내려면 $value$ 표기법을 사용하여 매개변수를 삽입해야 함을 표시합니다.
예를 들어 요청 본문 필드에 다음과 같이 입력합니다:
xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:mes="http://mes.myexample.com"
xmlns:get="http://getInfo.mes.myexample.com"
>
>
>
>
> $input1$
> $input2$
>
>
>
> ```
>
>
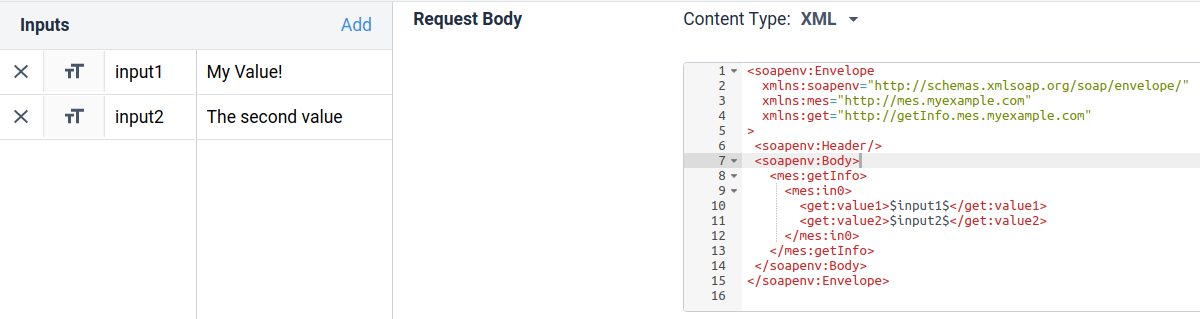
를 커넥터 함수에 입력으로 `입력1과` `입력2` 값을 입력하면 요청 본문에 `입력1과` `입력2` 값을 대입하여 요청이 이루어집니다.
이는 아래의 튤립 커넥터 함수 인터페이스에 나와 있습니다:
{height="" width=""}
## Tulip에서 XML 데이터 파싱하기
### 간단한 API 예제
XML API의 간단한 예제 응답부터 시작해 보겠습니다.
xml version="1.0" encoding="UTF-8"?
일상 이탈리아어
Giada De Laurentiis
2005
30.00
해리 포터
J K. Rowling
2005
29.99
XML 학습
에릭 T. 레이
2003
39.95
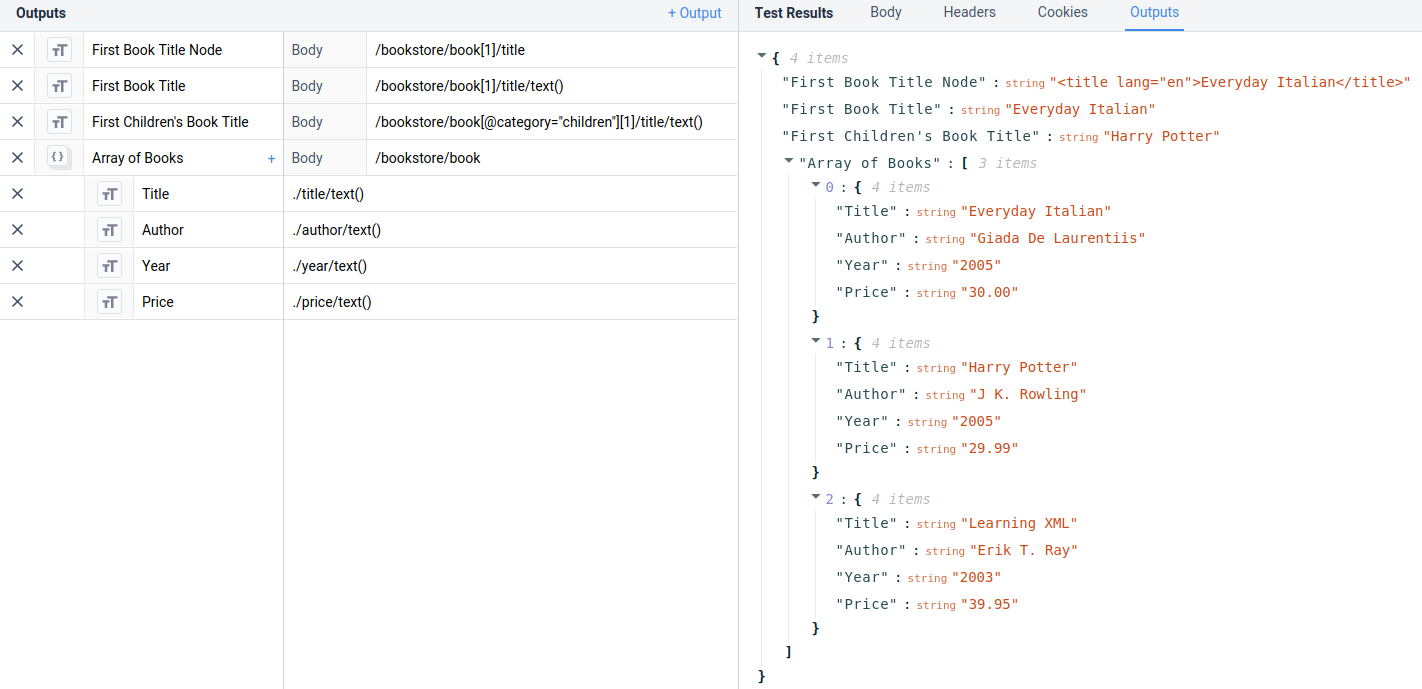
다음 예제는 Tulip 내의 다양한 정보에 접근하는 방법을 보여줍니다.
추출기
`/bookstore/book[1]/title`
을 반환합니다:
`<title lang="en">Everyday Italian</title>`
XML의 배열은 "1-인덱스"로, "0-인덱스"인 {{glossary.JSON}} 쿼리와 달리 첫 번째 요소가 "1" 위치에 있다는 것을 의미한다는 점에 유의하세요.
추출기는 다음과 같습니다:
`/bookstore/book[1]/title/text()`
가 반환합니다:
`일상 이탈리아어`
`text()` 함수는 선택한 노드에 포함된 텍스트 값을 추출하는 데 사용됩니다.
추출기는 다음과 같습니다:
`/bookstore/book[@category="children"][1]/title/text()`
를 반환합니다:
`Harry Potter`
선택기를 사용하면 노드의 속성 내에서 검색할 수 있다는 점에 유의하세요.
이 예제는 아래와 같이 Tulip에서 직접 사용할 수 있습니다:
### SOAP API 예제
이제 SOAP API의 일반적인 기능인 네임스페이스를 사용하여 좀 더 복잡한 경우를 살펴보겠습니다.
```<soap:Envelope
xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
>
>
>
>
> 0
>
>
> 정보 검색 성공
>
>
>
> 내 작업
> 없음
> 1234567-890
> B
>
>
>
> 부품 번호
> 1234567-890
>
>
> PartRevision
> B
>
>
> 부품 설명
> 내 예제 부품
>
>
>
> Normal
>
>
>
>
>
> ```
>
>
이 응답은 XML 네임스페이스를 사용하므로 복잡성이 추가됩니다. 대부분의 경우 `//*` 및 `.//*` 연산자를 사용하는 전역 검색을 사용하면 매우 간단하게 추출할 수 있습니다.
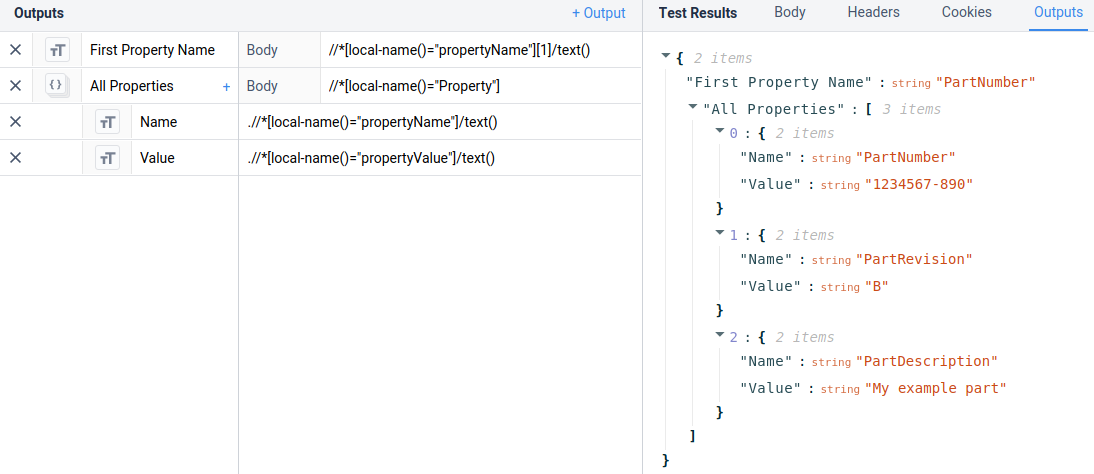
추출기
`//*[local-name()="propertyName"][1]/text()`
를 반환합니다:
`PartNumber`
XML의 배열은 "1-인덱스"로, "0-인덱스"인 json-query와 달리 첫 번째 요소가 "1"의 위치에 있다는 것을 의미합니다.
추출기
`//*[local-name()="Property"]`
를 반환합니다:
`<Property xmlns="http://getInfo.mes.myexample.com"> <propertyName>PartNumber</propertyName> <propertyValue>1234567-890</propertyValue> </Property> <Property xmlns="http://getInfo.mes.myexample.com"> <propertyName>PartRevision</propertyName> <propertyValue>B</propertyValue> </Property> <Property xmlns="http://getInfo.mes.myexample.com"> <propertyName>부품 설명</propertyName> <propertyValue>내 예제 부품</propertyValue> </Property>`
여기서 네임스페이스가 이 결과로 "가져온" 것에 주목하세요. 따라서 하위 쿼리는 여전히 전역 네임스페이스를 검색합니다.
객체 배열을 추출하려면 이전 예제에 표시된 글로벌 검색을 사용하여 배열을 추출한 다음 로컬 검색 추출기를 사용하여 다음과 같이 추출합니다:
`.//*[local-name()="propertyName"]/text()`
를 사용하여 해당 형식의 객체 배열을 검색합니다:
`[ { "Name": "PartNumber" "Value": "1234567-890" }, { "Name": "PartRevision" "Value": "B" }, { "Name": "PartDescription" "값": "내 예제 부품" } ]`
이러한 예제는 아래의 튤립 커넥터 인터페이스에 나와 있습니다:
---
원하는 것을 찾았나요?
[community.tulip.co로](https://community.tulip.co/?utm_source=intercom&utm_medium=article-link&utm_campaign=all) 이동하여 질문을 게시하거나 다른 사람들이 비슷한 문제를 겪었는지 확인할 수도 있습니다!