

Tulip 내에서 데이터를 최적으로 저장하고 관리하는 방법을 알아보세요.
앱과 마찬가지로 Tulip의 데이터도 하나의 시스템으로 함께 작동해야 합니다. 데이터를 쉽게 액세스하여 사람과 다른 시스템에 정보를 제공하면 가시성이 향상되고 여러 곳에 데이터가 중복되는 것을 방지할 수 있습니다.
모범 사례
다음은 애플리케이션의 데이터 구조를 계획할 때 따라야 할 몇 가지 원칙입니다:
테이블에 디지털 트윈 구조 채택
디지털 트윈은 부품, 사물, 기계 또는 전체 생산 프로세스의 동적 가상 표현 또는 모델입니다. 이는 물리적 항목 자체, 항목의 가상 표현, 물리적 객체와 가상 객체 간에 데이터를 주고받을 수 있는 연결 기능으로 구성됩니다.
툴테이블은 작업 현장에 있는 것을 가능한 한 1:1로 반영해야 합니다.
정보별로 테이블 구성
테이블의 유형을 식별하고 정의하는 것이 가장 좋습니다. 어떤 정보가 어떤 테이블에 들어가는지 이해하는 것은 솔루션을 설계할 때 특히 중요합니다.
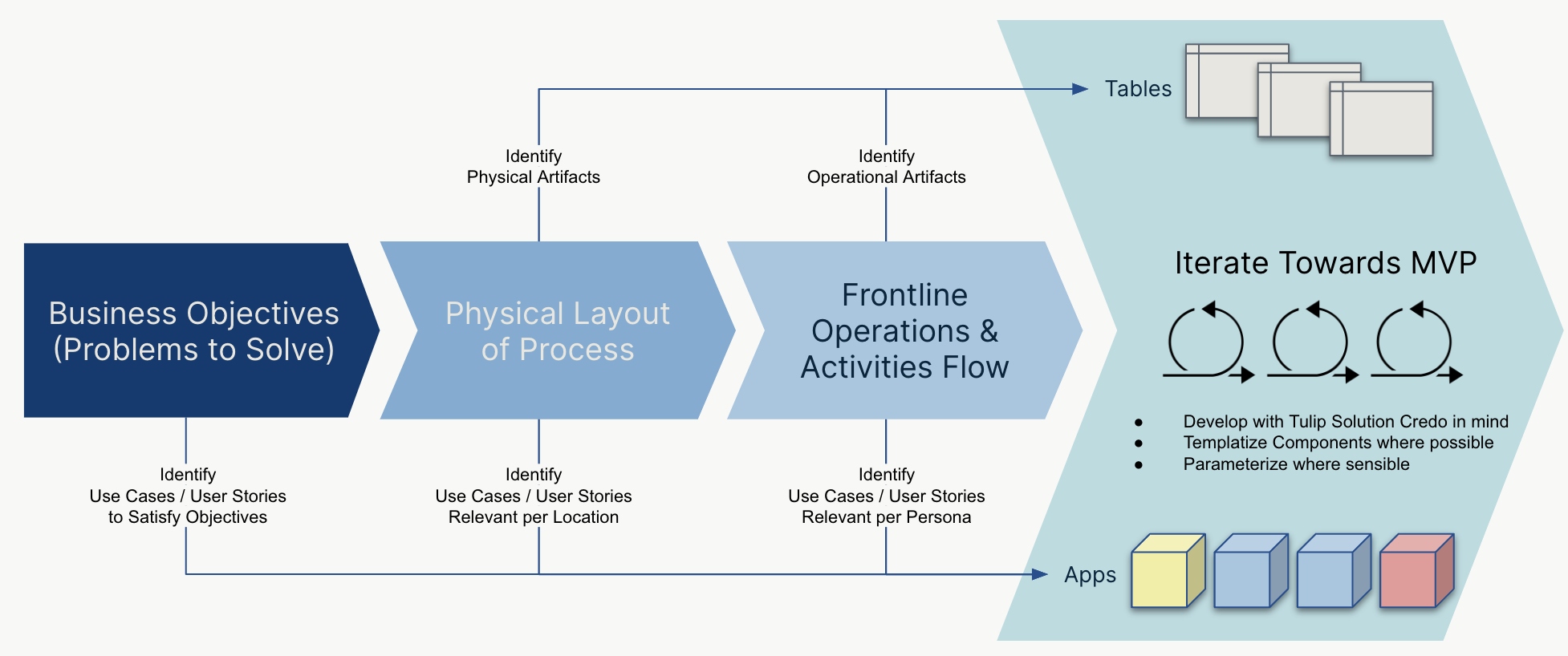
예를 들어, Tulip의 예제 공통 데이터 모델의 테이블은 두 가지 범주로 분류됩니다:
| 카테고리 | 설명 | 예제 |
|---|---|---|
| 물리적 아티팩트 | 작업 현장에서 물리적으로 만질 수 있는 유형의 유물입니다. | 인벤토리 아이템, 장비 및 자산 |
| 운영 아티팩트 | 운영과 관련하여 흔히 볼 수 있는 고유하게 식별되는 무형의 요소입니다. 인쇄된 여행자 또는 티켓으로 흔히 볼 수 있습니다. | 칸반 카드, 작업 지시서 |
It’s important to remember that tables should avoid duplicating external data.
테이블 구조 및 설정
테이블과 필드는 단순해야 하며 어떤 정보를 저장하는지에 대한 명확한 목적이 있어야 합니다. 앞서 설명한 테이블 유형(물리적 아티팩트와 운영 아티팩트)을 사용하면 각 테이블의 목적을 좁게 정의할 수 있습니다.
각 테이블의 필드는 아티팩트와 관련된 정보에 따라 달라집니다. 경험상 대부분의 테이블에는 상태(또는 이와 유사한) 필드가 포함되어야 하며, 추가할 수 있는 다른 일반적인 필드는 다음과 같습니다:
- 자료
- 위치/빈
- ID(작업 주문, 재료, 고객 등)
- 측정값
- 시작, 요청 또는 완료 날짜
- 코멘트
- 사진
계산에 사용하려는 모든 데이터에 대해 쿼리 또는 집계를 만듭니다. 목표 및 KPI를 알려주는 계산을 통해 현재 작업의 스냅샷을 얻을 수 있습니다.
이름 지정 규칙
사용하는 테이블 이름과 열 이름은 다른 시민 개발자나 Tulip 애널리틱스의 운영자가 볼 수 있으므로 소프트웨어 엔지니어가 일반적으로 사용하는 명명 규칙을 사용하는 대신 테이블과 테이블 열에 직관적인 인간 중심의 이름을 사용해야 합니다. 즉, 테이블의 이름은 'eqps_tools'가 아닌 '장비 및 도구'와 같은 이름을 지정하고, 열 이름은 'eqpType'이 아닌 '장비 유형'과 같은 이름을 사용하세요.
Tulip의 요소 이름 지정 모범 사례에 대해 자세히 알아보세요.
완료 레코드를 사용하는 시기
완료 레코드는 앱 / 앱 완료와 같은 전환을 통해 앱을 완료하거나 모든 앱 데이터 저장 트리거 작업을 통해 생성되며, 기록 데이터는 일반적으로 앱 완료를 통해 추적되어 각 앱에 로컬인 완료 레코드에 저장됩니다.
프로세스 기록 및/또는 애널리틱스를 통해 해당 데이터를 분석하기 위한 목적으로만 데이터를 저장해야 하는 경우, 완료 레코드로 충분하며 가장 쉬운 방법으로 데이터를 저장할 수 있습니다.
공통 데이터 모델 고려
공통 데이터 모델은 Tulip을 성공적으로 사용하기 위한 핵심 요소인 컴포저빌리티를 가능하게 합니다. 앱 제품군을 구축할 때, 재사용 가능한 데이터로 앱을 '연결'하기 위한 기반으로 데이터 모델을 갖는 것도 중요합니다.
Tulip 공통 데이터 모델로 시작한 다음 필요에 따라 조정할 수도 있습니다.