

Some AI tigger actions are currently in open beta. Reach out to copilot@tulip.co if you are interested in joining the beta.
Use of Beta Versions offered by Tulip is optional and is at your sole risk. Due to the untested/unproven nature of Beta versions, they are provided “as is,” “as available,” and without warranty. This means that any warranties, indemnities and other obligations of Tulip under any terms of service or MSA do not apply to Beta Versions.* Tulip AI is powerful! We will help to guide, but you are ultimately responsible for the impact of what you build.* We reserve the right to turn off any and all AI Trigger Actions at any time if we notice something unexpected.* We reserve the right to limit AI Trigger Actions during the course of the beta if and as needed.* You will not be charged for the usage of AI Trigger Actions during the program. You will have three months after the conclusion of the program to decide to continue with the feature or not. * At some point in the future, we may implement usage based pricing for beta features.
"문서에서 질문에 답변" 및 "데이터에서 질문에 답변" 트리거 작업은 PDF, 이미지, 데이터 목록 또는 텍스트의 텍스트 기반 정보를 분석하여 사용자가 제공한 질문에 대한 답변을 반환합니다. 또한 질문에 답하는 데 사용된 입력의 일부를 참조로 반환하면 사용자가 원하는 경우 답변을 생성하는 데 사용된 소스를 검토할 수 있습니다.
사용 사례 예시:
- 긴 사용 설명서나 유지보수 매뉴얼을 일일이 찾아볼 필요 없이 기계 문제에 대한 빠른 해결책 찾기
- 요약 요청을 통해 문제 설명에서 핵심 정보를 추출합니다.
입력 및 출력
트리거 작업에는 문서/데이터와 질문이라는 두 가지 입력과 답변과 참조라는 두 가지 출력이 있습니다.
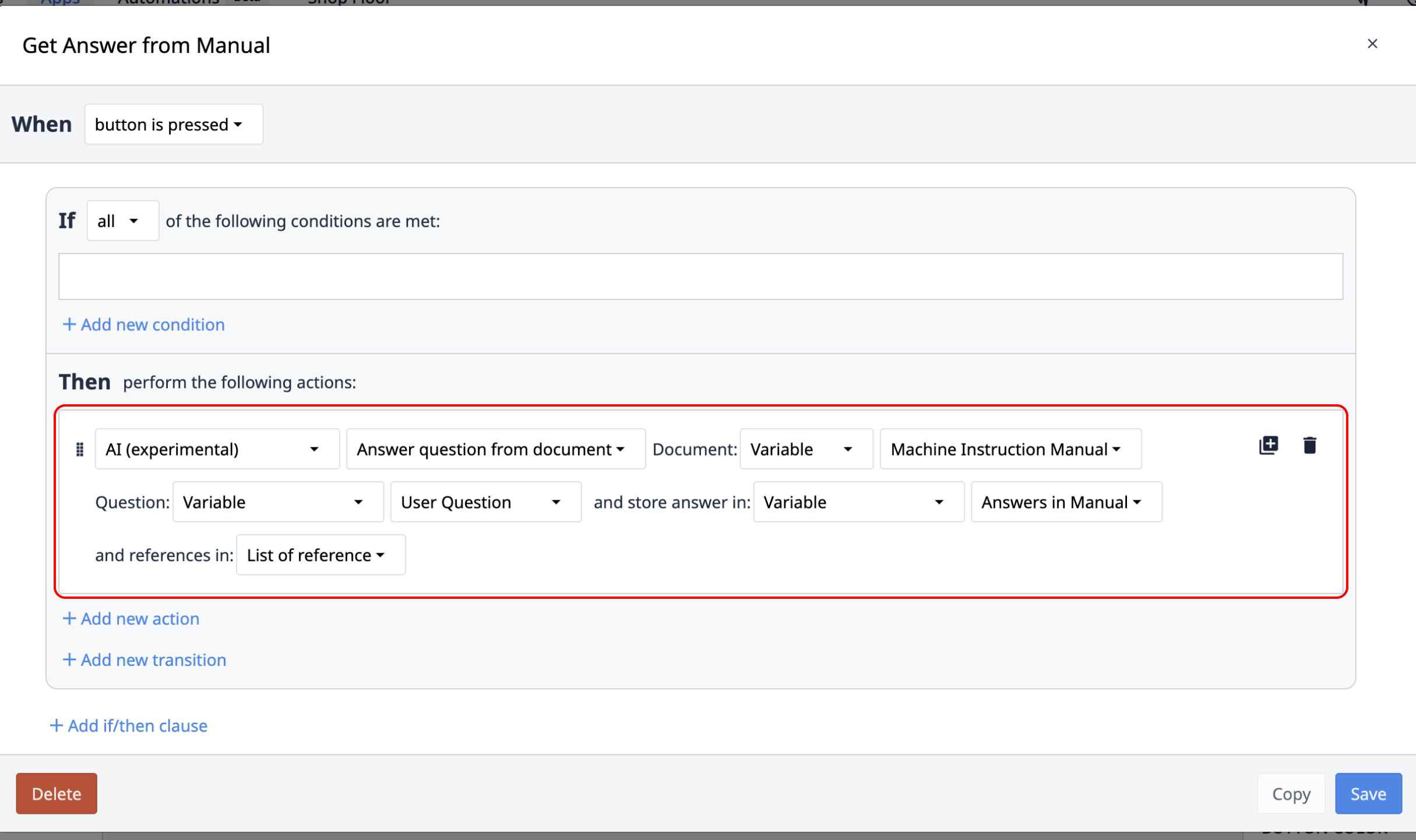
Input: Input
다음에 대한 정보 소스로 사용될 데이터입니다.
지원되는 데이터 유형입니다:
| 문서에서 질문에 답하기 | 데이터에서 질문에 답하기 |
|---|---|
| 파일(PDF*) | 배열 |
| 이미지 | 텍스트 |
*비밀번호로 보호된 PDF는 현재 지원되지 않습니다.:::(Info) (NOTES)
"Answer Question" works best with text based data in the Input. For numeric data, we recommend storing the data in a Tulip Table and using Tulip Analytics.
:::
현재 지원되는 언어(PDF 및 이미지): *영어* 프랑스어* 독일어* 이탈리아어* 포르투갈어* 스페인어
입력: 질문
데이터를 기반으로 답변할 질문입니다.
지원되는 데이터 유형:* 텍스트
현재 지원 언어:* 영어* 프랑스어* 독일어* 이탈리아어* 포르투갈어* 스페인어
출력: 답변 Answer
입력에 따라 트리거 액션에 의해 식별된 질문에 대한 답변입니다.
| 지원되는 데이터 유형 | |
|---|---|
| 출력 | 텍스트 |
출력입니다: 참조
트리거 동작에서 답을 식별하는 데 사용된 입력 부분의 배열입니다. 이 출력은 입력에 대해 선택한 데이터 유형에 따라 달라집니다.
입력은 파일(PDF) 또는 이미지입니다.
속성이 "페이지" 및 "텍스트"인 객체 목록 * PDF의 경우 목록의 항목은 질문에 답하는 데 사용된 각 페이지의 페이지 번호 및 추출된 텍스트입니다. 이미지의 경우 목록에는 페이지 번호 1과 이미지에서 감지된 텍스트가 있는 항목이 하나만 있습니다.
입력은 모든 유형의 목록입니다.
입력과 동일한 유형의 목록 * 목록에는 질문에 답하는 데 사용된 모든 레코드가 포함됩니다.
작동 방식 및 고려해야 할 사항
'질문에 답하기' 트리거 작업의 핵심은 문서에서 가장 관련성이 높은 답변을 찾는 스마트한 방법을 사용하는 것입니다. 다음은 PDF(=여러 페이지) 또는 레코드 목록과 같이 여러 참조가 있을 수 있는 입력의 예를 사용하여 작동하는 방식입니다:
- 사용자가 입력으로 제공한 문서/기록의 각 페이지를 가져와 고유한 '지문'을 생성합니다. 이를 통해 각 페이지의 내용을 이해하는 데 도움이 됩니다.
- 사용자가 질문을 하면 해당 지문을 기반으로 질문과 가장 관련성이 높은 페이지/기록을 식별합니다.
- 그런 다음 질문과 관련된 페이지 또는 레코드를 가져와 AI 시스템에 입력으로 제공하여 해당 페이지에 기반한 질문에 답변합니다.
- 그러면 트리거 작업은 답변과 함께 질문에 답변하는 데 사용된 페이지 또는 레코드도 반환하므로 사용자는 두 가지를 모두 검토할 수 있습니다.
명심해야 할 한 가지 중요한 점은 이 시스템이 매우 강력하지만 한 번에 '읽을 수 있는' 양에는 한계가 있다는 것입니다. 즉, 질문에 대한 답변에 항상 모든 정보(예: PDF의 페이지)를 사용할 수는 없습니다. 따라서 일부 유형의 질문은 다른 유형의 질문보다 시스템에 더 적합합니다. 예를 들어, 전체 문서에 걸쳐 개수를 세도록 요청하면 모든 페이지나 레코드를 포함할 수 없는 경우 정확한 결과가 나오지 않을 수 있습니다. 따라서 저희 시스템은 가능한 한 정확하도록 설계되었지만, 특히 중요한 주제에 대해서는 사람이 직접 참여하는 것이 좋습니다. 이는 시스템이 신뢰할 수 없어서가 아니라 AI를 보완하는 인간의 판단의 가치를 믿기 때문입니다. 이렇게 하면 최고 수준의 정확성과 맥락 이해를 보장할 수 있습니다.
엣지 사례
입력이 없거나 쿼리가 제공되지 않은 경우
트리거 동작에 입력이 없거나 쿼리가 제공되지 않으면 앱에 다음과 같은 시스템 오류가 표시됩니다.입력 또는 쿼리가 비어 있습니다.
다음 모든 경우에 발생합니다.* 입력 및/또는 쿼리에 값이 할당되지 않았습니다. 쿼리에 빈 문자열이 할당되어 있습니다.
제공된 입력으로 질문에 답할 수 없음
주어진 컨텍스트에 제공된 정보가 없습니다 [...] 라는 답변이 나옵니다.
제한 사항
The following languages are the only languages supported for documents: English, Spanish, Italian, Portuguese, French, German.
현재 AI 트리거에는 다음과 같은 제한이 있습니다. 이러한 제한은 인스턴스 수준에서 추적됩니다. 이러한 제한을 초과한 경우에는 트리거 작업이 실패합니다.
'``문서에서 질문에 답변:월별 한도: 10,000건의 요청/월 속도 한도: 분당 10건의 요청/분
데이터의 질문에 대한 답변:월별 한도: 100,000건/월요청량 한도: 분당 10건``