
为各种其他副驾驶员选项启用外部模型
目的
本文介绍如何通过 API Gateway 和简单的 Lambda 函数使用自定义基岩模型和端点来调用模型。
高级架构
以下是使用客户租户自定义 Bedrock 模型的高级架构摘要: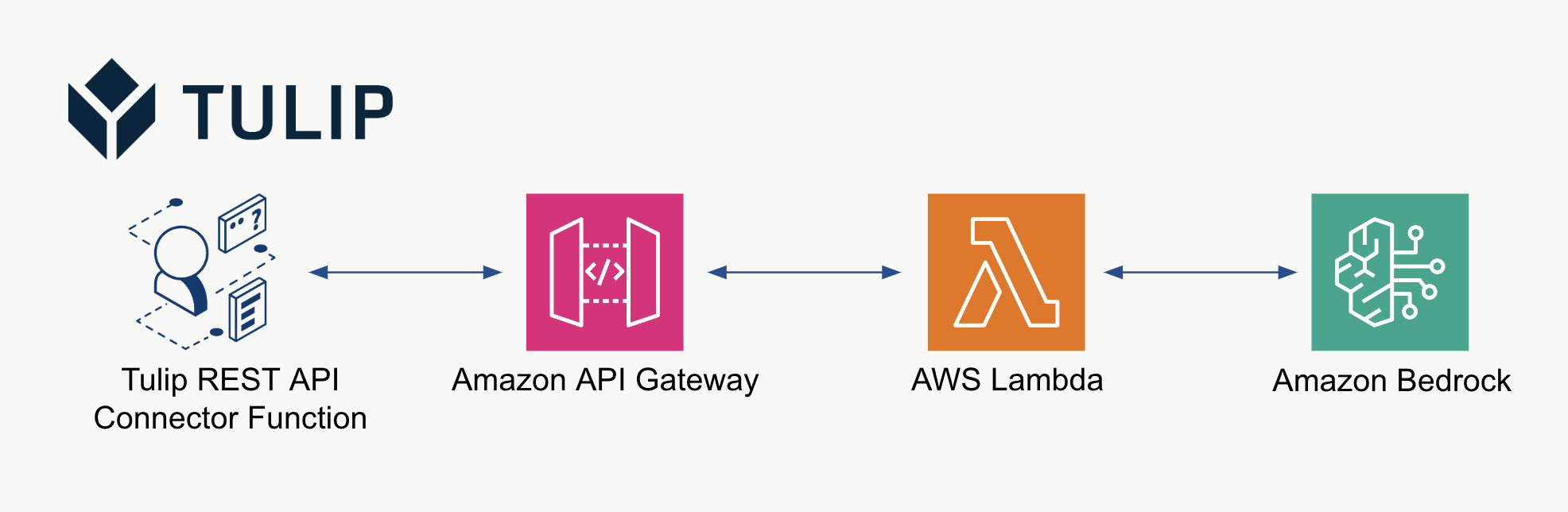
示例架构和 lambda 函数(见下节)可通过连接器函数(如下面的函数)加以利用。注意:可以使用 OAuth2.0 等多种身份验证方法来确保所使用的 API 网关的安全。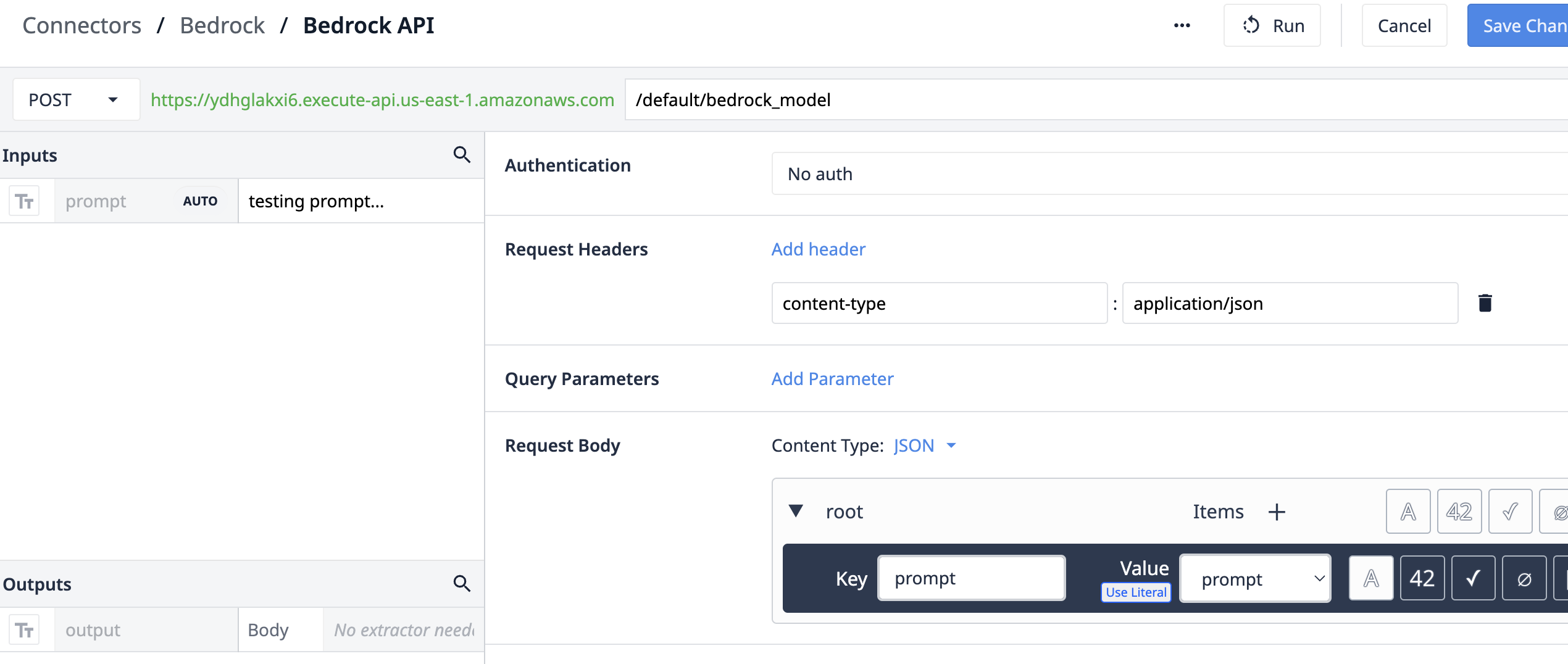
示例 Lambda 函数
下面是一个 lambda 函数示例脚本,用于调用 Amazon Bedrock 中的自定义模型。此脚本可用作为自定义 Bedrock 模型创建自定义推理的起点。
``python import json import boto3 import logging logger = logging.getLogger**(name**)
def lambda_handler(event, context): print(event) brt = boto3.client(service_name='bedrock-runtime') event_dict = json.loads(event['body']) prompt = event_dict['prompt']
body = json.dumps({ "prompt": f"\n\nHuman: "+prompt+"\n\nAssistant:", "max_tokens_to_sample":300, "temperature":0.1, "top_p":0.9, }) modelId = 'anthropic.claude-v2' accept = 'application/json' contentType = 'application/json' response = brt.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType) response_body = json.loads(response.get('body').read()) completion_output = response_body.get('completion') return { "statusCode":200, "body": completion_output
} ```
规模考虑
利用自定义模型的一个主要情况是,您需要在自己的 AWS 租户上使用 Tulip 之外的训练数据。这些数据可能包括供应链数据、采购数据以及核心制造之外的其他数据源。这就为在 Amazon Bedrock 中利用自定义模型创造了机会,但至关重要的是要制定规模策略,包括调用自定义模型、模型调整等。
下一步计划
如需进一步阅读,请查看Amazon Well-Architected Framework。这是了解大规模调用模型的最佳方法和推理策略的重要资源