

根据 API 文档,学习在 HTTP 连接器函数中使用查询参数的基础知识。
.通过查询参数,您可以完善和定制连接器函数的结果。使用参数可以进行排序、过滤、设置限制、偏移索引等操作。本文使用的是郁金香表 API 参数,但其他 API 对参数的要求可能有所不同。请务必查看文档,确保使用正确的语法和规格。
使用过滤器查询
过滤器对于只提取您感兴趣的数据非常有用。这些筛选器的语法有时会比较麻烦。下面以请求记录的 GET 为例,概述了每种筛选器的语法,随后是一个完整的示例。
自定义字段的字段名前总是有一个五位数的字符串标识符。通过 GET 全部请求检查字段的真实名称后,最容易找到这些标识符。
- 例如"field"="maytq_scrap_count
参数值通常很简单。如果是文本值,请务必加上引号。
- 例如"arg":15
匹配您要使用的函数类型。
- 例如"函数类型": "g greaterThan
完整的请求可能是这样的
https://brian.tulip.co/api/v3/tables/W2HPvyCZrjMMHTiip/records?limit=100&sortBy=\_sequenceNumber&sortDir=asc&filters=[{"field": "maytq\_scrap\_count", "arg":15, "functionType": "greaterThan"}]&filterAggregator=any
如何在文档中查找查询参数
要查找请求的可用查询参数,请浏览 API 文档。如果使用的是郁金香表 API,则可在以下网址找到文档:your-instance.tulip.co/apiDocs.选择要使用的请求,然后向下滚动到 "参数"选项卡。
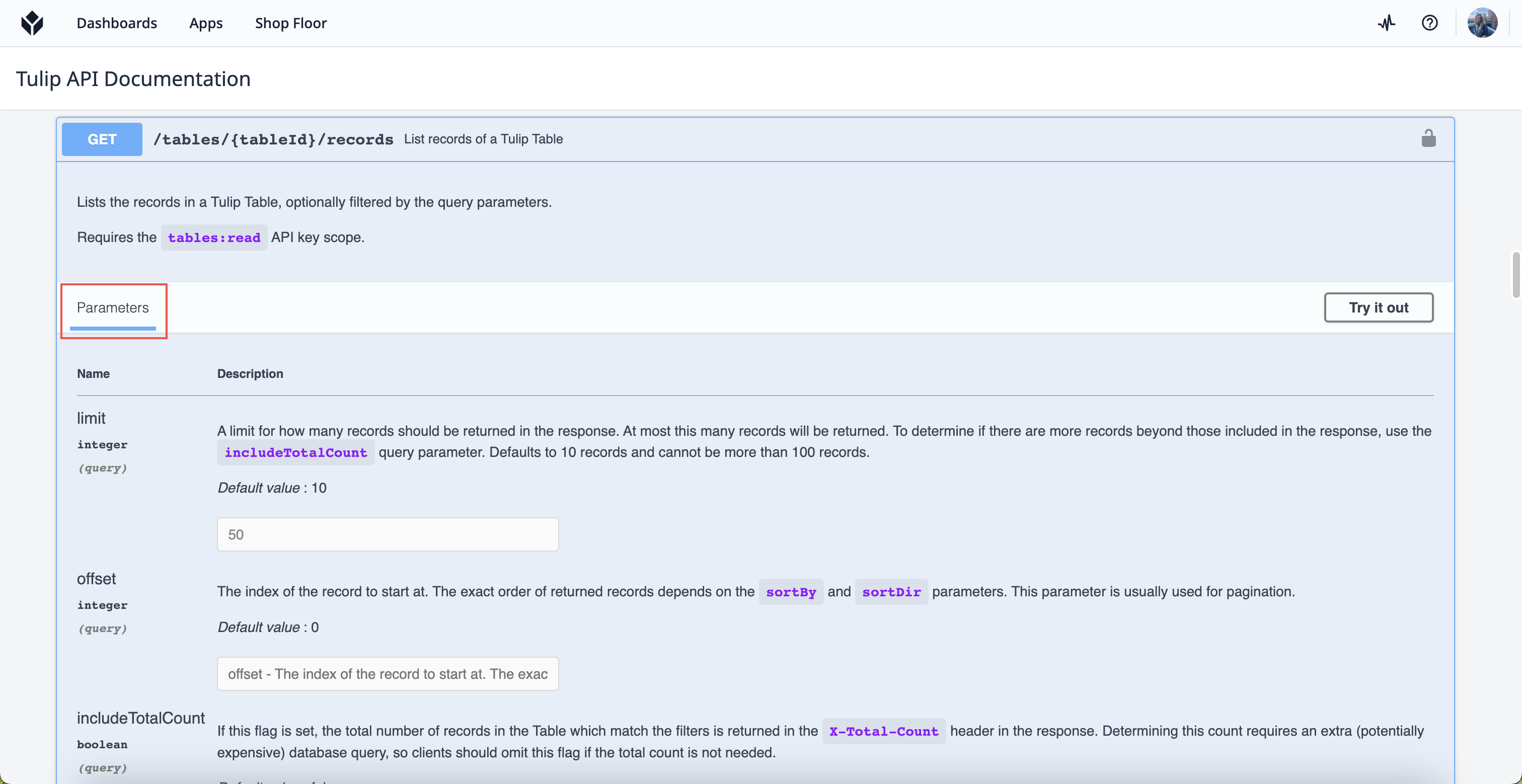
每个方法都有自己的参数集,但并非每个请求都有相关参数。请务必事先注意文档中的可用参数。
查询参数语法
查询参数语法依赖于查询字符串格式。这种格式为指定参数赋值,查询字符串本身就是 URL 的一部分。
在 "连接器函数编辑器 "中,单击 "添加参数 "创建新的查询参数。

查询参数由两部分组成:键和值。键是参数的名称,值是为结果设置参数的信息。
查询参数语法使用 Dot Notation,该语法指定了参数的确切类型。确保书写大小写符合其他系统的 API 标准。
将常用参数应用于连接器函数
要为连接器函数设置参数,首先要在 API 文档中确定要使用的参数。每个参数都有不同的要求,让我们来看看它们是什么样的。
For continuity purposes, we’ll use the same request API Call in each of the examples below. This is the GET request that retrieves a list of records in a tulip Table via the Tulip Table API. Other APIs you use will have different specifications for parameters, be sure to look at the API documentation requirements.
限制
限制为返回的结果设置了指定的上限。请注意,有些限制有默认设置,因此请务必查看 API 文档以了解初始值。
示例我们希望在运行连接器函数时获得不超过 70 条记录。幸运的是,此请求中限制的默认值是 10,最高值是 100。查询参数的语法如下:

过滤器
过滤器根据参数的给定信息对结果进行分离和细化。
过滤器由三部分组成,必须写入单独的参数中:
- 字段 - 表中列的名称
- 函数类型 - 比较函数类型
- 参数 - 比较结果的值
每个过滤器都有 3 个部分,每个完整的过滤器都是一个对象。使用点符号书写每个键,指定参数类型("筛选器")、筛选器编号(0 到 n)以及筛选器的部分("字段"、"函数类型 "或 "参数")。过滤器的三个部分都必须有一个参数。
示例我们要确保连接器函数的结果只显示特定字段(eubmc_value)中等于函数指定输入值(消耗值)的值。由于这是函数参数中的第一个过滤器,因此过滤器编号为 0,这意味着该过滤器的每个键都将以 "filter.0 "开头。该过滤器的语法如下:

排序
排序结果根据参数信息对视图进行优先排序。排序结果决定了哪些结果会被纳入聚合。您可以使用多个排序功能,但选项的顺序决定了排序的优先级。
排序功能包括两个部分:
- sortBy - 对结果进行排序的字段
- sortDir - 排序方向,升序 (asc) 或降序 (desc)
每个排序功能都有 3 个部分。使用点符号写入每个键,指定参数类型("sortOptions")、排序编号(0 到 n)和排序参数("sortBy "或 "sortDir")。排序功能的所有三个部分都必须有一个参数才能起作用。
示例我们希望连接器函数的结果按最近更新的字段升序排序。因为这是第一个排序功能,所以排序编号是 0,这意味着该排序的两个键都将以 "sortOptions.0 "开头。对于 sortBy 关键字,其值是从 API 文档中导出的特殊值('_updatedAt'),用于对更新字段进行排序。这些参数的语法如下:

偏移量
偏移量决定了返回结果的起始索引。该参数用于分页,而不是由排序参数决定的记录顺序。参数值必须是大于或等于 0 的整数。
示例我们只想查看第 5 位以后的记录,这样就看不到前 5 位的结果了。查询参数的语法如下:

过滤器聚合器
过滤器聚合器决定了如何组合参数中的过滤器。可供选择的两个值是 "任意 "和 "全部"。全部 "值表示所有筛选器必须有一条记录,该记录才能包含在结果中。任意 "值表示至少有一个筛选器必须匹配一条记录,结果中才会包含该记录。默认值为 "全部",与是否设置参数无关。
示例我们在查询参数中设置了一系列筛选器,但我们只需要其中一个筛选器为真,记录就会与我们的请求相匹配。查询参数的语法如下:

多个过滤器
在某些情况下,您可能需要在表中检查多个筛选器。在这种情况下,可以在过滤器对象中添加多个过滤器。如下所示
filters=[{"field": "maytq\_scrap\_count", "arg":15, "functionType": "greaterThan"},{"field": "maytq\_scrap\_reason", "arg": "scratch", "functionType": "equal"}]]