

A ação de acionamento Extrair texto da imagem extrai texto de uma imagem com base em uma consulta. Outra maneira de descrever isso é "OCR (reconhecimento óptico de caracteres) baseado em consulta" ou "Extrair texto de uma imagem solicitando-o".
O acionador sempre retornará apenas o texto que está de fato presente na imagem. Ele não acrescentará informações ou interpretações adicionais. Isso o torna muito eficiente na transferência de dados do mundo físico para o digital.
Exemplos de casos de uso:
- Ingerir dados de um formulário de pedido proveniente de um fornecedor externo. Esqueça a transferência manual daquele número de pedido de 14 caracteres de uma fatura de fornecedor para o seu WMS. Combine um aplicativo simples e o "Extract Text from Image" para extrair esses dados em segundos.
- Digitalize formulários em papel. Os dados contidos nos viajantes de papel existentes são ainda mais valiosos quando podem ser acessados nos aplicativos da Tulip. As ações "Extrair texto da imagem" são um ótimo mecanismo para fazer a ponte entre o mundo físico e o digital.
- Trabalhe com textos em idiomas estrangeiros para seus operadores, de forma confiável. O mundo da manufatura é global. Dê aos seus operadores superpoderes combinando as ações de acionamento "Extrair texto da imagem" e "Traduzir" para transformar informações em papel em algo em que seus operadores possam agir.
Exemplo de acionador
Use um aplicativo móvel para tirar uma foto de uma etiqueta em um produto para obter o número do lote.
| Imagem | Acionador | Resultado |
|---|---|---|
| image.png{height="" width="400"} | image.png{height="" width="400"} | 11EP8F4WA58CCX |
Extrair valor da imagem
Entradas e saídas
A ação de acionamento tem duas entradas, Imagem de entrada e Consulta, e uma saída, o texto extraído.
Entrada: Imagem de entrada
Essa é a imagem da qual o texto deve ser extraído. Ela pode vir do widget de entrada da câmera, da Tulip Vision ou de sistemas externos.
| Tipo de dados suportado | |
|---|---|
| Entrada | URL da imagem |
Entrada: Consulta
Esta é a consulta usada para extrair o texto da imagem ou do documento.
Práticas recomendadas de consulta:* Sempre que possível, use palavras do documento. Isso é particularmente útil para acrônimos e abreviações (por exemplo, SN, ID, SSN, número do lote, etc.). As ações de acionamento de extração de texto suportam consultas menos complexas do que as ações de acionamento de Resposta à pergunta dos dados/documento. * Ex. Ótima entrada: "Quem é o fornecedor?" * Ex. Entrada ruim: "Especificar o local das informações também pode ajudar (por exemplo, "Qual é o número de referência na parte inferior?")
| Tipo de dados suportado | |
|---|---|
| Entrada | Texto |
Saída: Extracted Text (Texto extraído)
Este é o texto que foi extraído da imagem com base na consulta.
| Tipo de dados suportado | |
|---|---|
| Saída | Texto |
Extrair valores de imagem/documento
Extracting values from documents is a relatively slow operation. We limit documents to 10 pages to limit execution time.
Extract Values from Image/Document (Extrair valores da imagem/documento) funciona da mesma forma que Extract value from image (Extrair valor da imagem), mas suporta uma matriz de perguntas. Isso será significativamente mais eficiente do que executar a ação de acionamento Extrair valor da imagem.
Entrada: Imagem/Documento de entrada
Essa é a imagem da qual o texto deve ser extraído. Pode vir do widget de entrada da câmera, da Tulip Vision ou de sistemas externos. Para arquivos, pode ser definida estaticamente, entrada com o widget de entrada de arquivo ou arquivos de referência armazenados em tabelas.
| Tipo de dados suportado | |
|---|---|
| Entrada | URL da imagem |
Entrada: Consulta
Esta é a consulta que é usada para extrair o texto da imagem. Deve ser uma matriz/lista de valores de texto.
| Tipo de dados suportado | |
|---|---|
| Entrada | Lista de texto |
Saída: Extracted Text (Texto extraído)
Esse é o texto que foi extraído da imagem com base na consulta.
| Tipo de dados suportado | |
|---|---|
| Saída | Matriz de objetos. Cada elemento terá um atributo "Pergunta" e "Resposta". |
Extrair todo o texto da imagem/documento
Em alguns casos, o paradigma chave:valor das ações de acionamento de extração de valor não faz sentido para o seu caso de uso. A leitura de todos os dados de uma imagem oferece flexibilidade quase infinita em relação aos problemas que podem ser resolvidos pelo copiloto. As ações de acionamento "Extrair todo o texto" proporcionam essa flexibilidade.
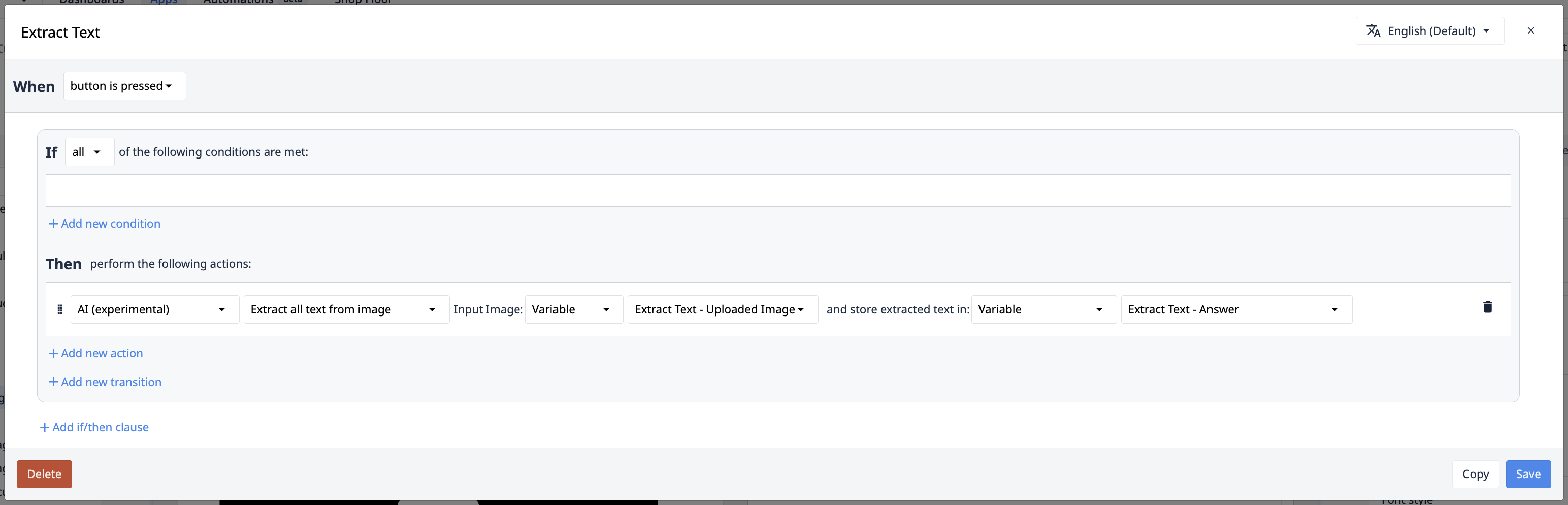
Entrada: Imagem/Documento de entrada
Essa é a imagem da qual o texto deve ser extraído. Ela pode vir do widget de entrada da câmera, do Tulip Vision ou de sistemas externos. Para arquivos, pode ser definida estaticamente, entrada com o widget de entrada de arquivo ou arquivos de referência armazenados em tabelas.
| Tipo de dados suportado | |
|---|---|
| Entrada | URL da imagem ou URL do arquivo |
Saída: Texto extraído
Este é todo o texto encontrado na respectiva imagem ou documento. Os documentos retornarão uma matriz de dados, com cada item representando o texto de uma página do documento fornecido.
| Tipo de dados suportado | |
|---|---|
| Saída | (para imagens) Texto. (para documentos) Lista de texto |
Casos extremos
Nenhuma imagem de entrada e/ou nenhuma consulta fornecida
Se nenhuma imagem de entrada ou nenhuma consulta for fornecida para a ação de acionamento, o aplicativo mostrará o seguinte erro de sistema*:Your Input or Query is empty*
Isso acontece em todos os casos a seguir:* A imagem de entrada e/ou a entrada de consulta não têm um valor atribuído. Isso é equivalente a "nulo".* A consulta tem uma cadeia de caracteres vazia atribuída.
Nenhum resultado para a consulta
Se não for possível encontrar nenhum resultado para a consulta, a ação do acionador retornará um texto vazio.
Limites
The following languages are the only languages supported for documents where values are being extracted: English, Spanish, Italian, Portuguese, French, German.
Atualmente, existem os seguintes limites para os acionadores "Extrair texto da imagem". Esses limites são rastreados em nível de instância. Caso esses limites tenham sido excedidos, a ação do acionador "Extrair texto da imagem" falhará.