

A Szöveg kivonása képből kivonja a szöveget egy képből egy lekérdezés alapján. Egy másik módja ennek leírására a "lekérdezés alapú OCR (optikai karakterfelismerés)" vagy "Szöveg kivonása egy képből kérdezéssel".
A trigger mindig csak olyan szöveget ad vissza, amely valóban jelen van a képen. Nem ad hozzá további információkat vagy értelmezést. Ez teszi nagyon hatékonnyá az adatoknak a fizikai világból a digitális világba történő átviteléhez.
Példa felhasználási esetek:
- Egy külső szállítótól érkező megrendelőlap adatainak bevitele. Felejtse el a 14 karakteres rendelési szám kézi átvitelét a szállítói számláról a WMS-be, kombináljon egy egyszerű alkalmazást és az "Extract Text from Image" (Szöveg kivonása képből), hogy másodpercek alatt megkapja ezeket az adatokat.
- Digitalizálja a papíralapú nyomtatványokat. A meglévő papíralapú utazókon szereplő adatok még értékesebbek, ha a Tulip alkalmazásokon belül elérhetők. A "Szöveg kivonása képből" művelet nagyszerű mechanizmus a fizikai és a digitális világ összekapcsolására.
- Dolgozzon megbízhatóan az üzemeltetői számára idegen nyelvű szöveggel. A gyártási világ globális, adjon szuperképességeket az operátorainak a "Szöveg kivonása képből" és a "Fordítás" kiváltó művelet kombinálásával, hogy a papír alapú információkat olyanná alakítsa, amivel az operátorai tudnak cselekedni.
Trigger példa
Egy mobilalkalmazás segítségével készítsen képet egy termék címkéjéről, hogy megkapja a tételszámot.
| Kép | Trigger | Eredmény |
|---|---|---|
| image.png{height="" width="400"} | image.png{height="" width="400"} | 11EP8F4WA58CCX |
Érték kivonása a képből
Bemenetek és kimenetek
A kiváltó műveletnek két bemenete van, a bemeneti kép és a lekérdezés, és egy kimenete, a kinyert szöveg.
Bemenet: Bemeneti kép
Ez az a kép, amelyből a szöveget ki kell vonni. Ez származhat a kamera bemeneti widgetjéből, a Tulip Visionből vagy külső rendszerekből.
| Támogatott adattípus | |
|---|---|
| Bemenet | Kép URL |
Bemenet: Lekérdezés:
Ez az a lekérdezés, amely a szöveg kinyerésére szolgál a képből vagy dokumentumból.
A lekérdezés legjobb gyakorlatai:* Ha lehetséges, használjon szavakat a dokumentumból. Ez különösen hasznos a rövidítések és a rövidítések esetében (pl. SN, ID, SSN, tételszám stb.). A szövegkivonat kiváltó műveletek kevésbé összetett lekérdezéseket támogatnak, mint a Kérdésre adott válasz az adatokból/dokumentumból kiváltó műveletek. * Pl. Nagyszerű bemenet: "Ki a szállító?" * Pl. Rossz bemenet: "* Az információ helyének meghatározása is segíthet (pl. "Mi a hivatkozási szám az alján?").
| Támogatott adattípus | |
|---|---|
| Bevitel | Szöveg |
Kimenet: Szöveg: Kivont szöveg
Ez az a szöveg, amelyet a lekérdezés alapján kivontak a képből.
| Támogatott adattípus | |
|---|---|
| Kimenet | Szöveg |
Értékek kivonása a képből/dokumentumból
Extracting values from documents is a relatively slow operation. We limit documents to 10 pages to limit execution time.
Az Értékek kivonása képből/dokumentumból ugyanúgy működik, mint az Érték kivonása képből, de támogatja a kérdések tömbjét. Ez lényegesen nagyobb teljesítményt nyújt, mint a képből értéket kivenni kiváltó művelet futtatása.
Bemenet: Input Image/Document
Ez az a kép, amelyből a szöveget ki kell vonni. Ez származhat a kamera bemeneti widgetjéből, a Tulip Visionből vagy külső rendszerekből. Fájlok esetében ez statikusan beállítható, a fájl-bemeneti widget segítségével adható meg, vagy a Tables-ben tárolt fájlokra hivatkozhat.
| Támogatott adattípus | |
|---|---|
| Bemenet | Kép URL címe |
Bemenet: Lekérdezés:
Ez az a lekérdezés, amely a kép szövegének kinyerésére szolgál. Ennek szövegértékek tömbjének/listájának kell lennie.
| Támogatott adattípus | |
|---|---|
| Bemenet: | Szöveglista |
Kimenet: Szöveg
Ez az a szöveg, amelyet a lekérdezés alapján kivontak a képből.
| Támogatott adattípus | |
|---|---|
| Kimenet | Objektumtömb. Minden elemhez tartozik egy "Kérdés" és egy "Válasz" attribútum. |
Minden szöveg kivonása a képből/dokumentumból
Bizonyos esetekben az értékkivonat-indító műveletek kulcs:érték paradigmájának nincs értelme az Ön felhasználási eseteiben. Az összes adat kiolvasása egy képből szinte végtelen rugalmasságot biztosít a copilot által kezelhető problémák tekintetében. A "Minden szöveg kivonása" kiváltó művelet biztosítja ezt a rugalmasságot.
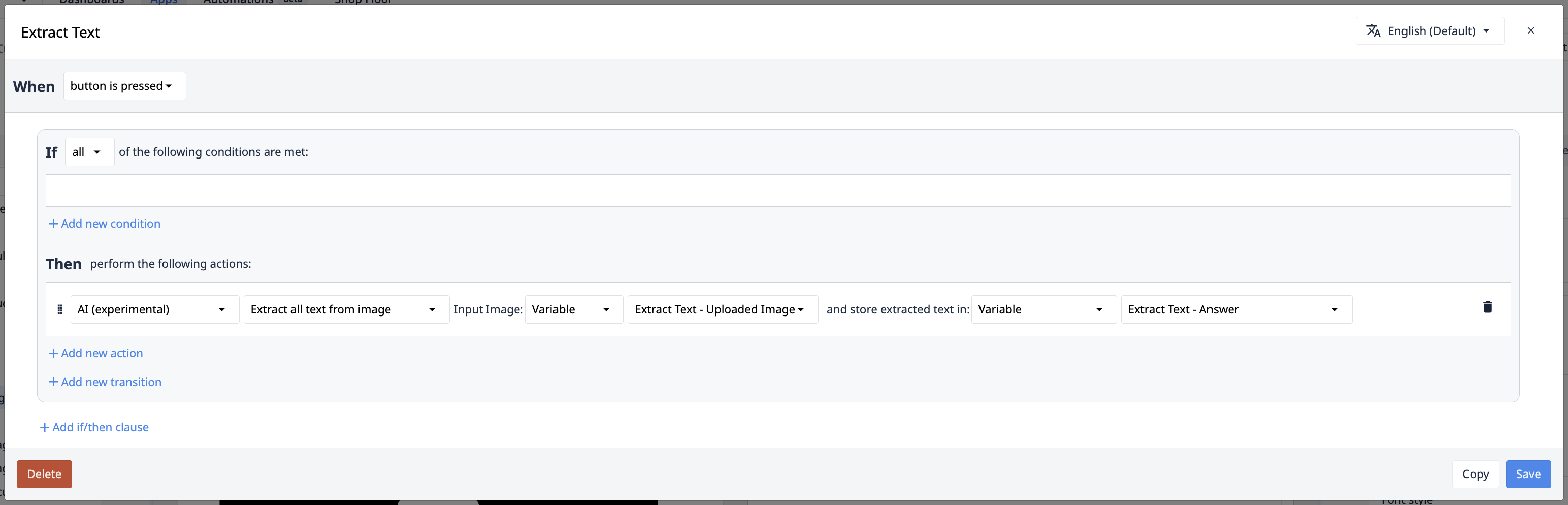
Input: Input Image/Dokumentum
Ez az a kép, amelyből a szöveget ki kell vonni. Ez származhat a kamera bemeneti widgetből, a Tulip Visionből vagy külső rendszerekből. Fájlok esetében ez statikusan beállítható, a fájlbeviteli widget segítségével, vagy a Tables-ben tárolt referenciafájlok segítségével.
| Támogatott adattípus | |
|---|---|
| Bemenet | Kép URL vagy fájl URL |
Kimenet: Kivont szöveg
Az adott képen vagy dokumentumban található összes szöveg. A Documents egy adattömböt ad vissza, amelynek minden egyes eleme a megadott dokumentum egy oldalának szövegét jelenti.
| Támogatott adattípus | |
|---|---|
| Kimenet | (képek esetében) Szöveg. (dokumentumok esetében) Szöveglista |
Éles esetek
Nincs bemeneti kép és/vagy nincs lekérdezés
Ha a kiváltó művelethez nincs bemeneti kép vagy lekérdezés megadva, az alkalmazás a következő rendszerhibát jeleníti meg*: Az Ön bemenete vagy lekérdezése üres.*
Ez a következő esetek mindegyikében előfordul:* A bemeneti kép és/vagy a lekérdezés bemenetéhez nincs hozzárendelve érték. Ez a "null"-nak felel meg.* A lekérdezéshez üres karakterláncot rendeltek.
Nincs eredmény a lekérdezéshez
Ha a lekérdezéshez nem találtak eredményt, a kiváltó művelet üres szöveget ad vissza.
Korlátok
The following languages are the only languages supported for documents where values are being extracted: English, Spanish, Italian, Portuguese, French, German.
Jelenleg a következő korlátozások léteznek a "Szöveg kivonása képből" kiváltókhoz. Ezeket a korlátokat példányszinten követi a rendszer. Abban az esetben, ha ezeket a határokat túllépik, a "Szöveg kivonása képből" kiváltó művelet sikertelen lesz.