

Действие триггера Extract Text from Image извлекает текст из изображения на основе запроса. Другой способ описать это действие - "OCR (оптическое распознавание символов) на основе запроса" или "Извлечение текста из изображения по запросу".
Триггер всегда будет возвращать только тот текст, который действительно присутствует на изображении. Он не будет добавлять к нему дополнительную информацию или интерпретировать его. Это делает его очень мощным инструментом для переноса данных из физического мира в цифровой.
Примеры использования:
- Получение данных из формы заказа от внешнего поставщика. Забудьте о ручном переносе 14-значного номера заказа из счета-фактуры поставщика в вашу WMS, используйте простое приложение и "Извлечение текста из изображения", чтобы получить эти данные за считанные секунды.
- Оцифруйте бумажные формы. Данные, содержащиеся в существующих бумажных бланках, становятся еще более ценными, когда к ним можно получить доступ в приложениях Tulip. Действия "Извлечь текст из изображения" - отличный механизм, позволяющий соединить физический и цифровой мир.
- Надежная работа с текстом на языках, чуждых вашим операторам. Мир производства глобален, дайте своим операторам суперспособности, объединив действия "Извлечь текст из изображения" и "Перевести", чтобы превратить бумажную информацию в то, что ваши операторы могут использовать.
Пример триггера
С помощью мобильного приложения сфотографируйте этикетку на продукте, чтобы узнать номер партии.
| Изображение | Триггер | Результат |
|---|---|---|
| image.png{height="" width="400"} | image.png{height="" width="400"} | 11EP8F4WA58CCX |
Извлечение значения из изображения
Входы и выходы
Действие триггера имеет два входа, входное изображение и запрос, и один выход, извлеченный текст.
Вход: Входное изображение
Это изображение, из которого должен быть извлечен текст. Оно может быть получено из виджета ввода камеры, Tulip Vision или внешних систем.
| Поддерживаемый тип данных | |
|---|---|
| Вход | URL-адрес изображения |
Ввод: Запрос
Это запрос, который используется для извлечения текста из изображения или документа.
Лучшие практики запросов:* По возможности используйте слова из документа. Это особенно полезно для аббревиатур и сокращений (например, SN, ID, SSN, Lot No. и т. д.). Действия триггера "Извлечь текст" поддерживают менее сложные запросы, чем действия триггера "Ответить на вопрос из данных/документа". * Ex. Отличный ввод: "Кто поставщик?" * Ex. Плохой ввод: "Как вы думаете, кто мог прислать это нам? "* Указание местоположения информации также может помочь (например, "Какой номер ссылки внизу?").
| Поддерживаемый тип данных | |
|---|---|
| Ввод | Текст |
Выходные данные: Извлеченный текст
Это текст, который был извлечен из изображения на основе запроса.
| Поддерживаемый тип данных | |
|---|---|
| Выходные данные | Текст |
Извлечение значений из изображения/документа
Extracting values from documents is a relatively slow operation. We limit documents to 10 pages to limit execution time.
Функция Extract Values from Image/Document работает так же, как Extract value from image, но поддерживает массив вопросов. Это будет значительно производительнее, чем выполнение триггера извлечения значения из изображения.
Вход: Входное изображение/документ
Это изображение, из которого должен быть извлечен текст. Оно может быть получено из виджета ввода камеры, Tulip Vision или внешних систем. Для файлов это значение может задаваться статически, вводиться с помощью виджета ввода файлов или ссылаться на файлы, хранящиеся в таблицах.
| Поддерживаемый тип данных | |
|---|---|
| Вход | URL-адрес изображения |
Ввод: Запрос
Это запрос, который используется для извлечения текста из изображения. Это должен быть массив/список текстовых значений.
| Поддерживаемый тип данных | |
|---|---|
| Вход | Список текстов |
Выходные данные: Извлеченный текст
Это текст, который был извлечен из изображения на основе запроса.
| Поддерживаемый тип данных | |
|---|---|
| Выходные данные | Массив объектов. Каждый элемент будет иметь атрибуты "Вопрос" и "Ответ". |
Извлечение всего текста из изображения/документа
В некоторых случаях парадигма ключ:значение в действиях триггера извлечения значения не имеет смысла для вашего случая использования. Чтение всех данных из изображения обеспечивает практически безграничную гибкость в решении проблем, которые может решить copilot. Триггерные действия "Извлечь весь текст" обеспечивают такую гибкость.
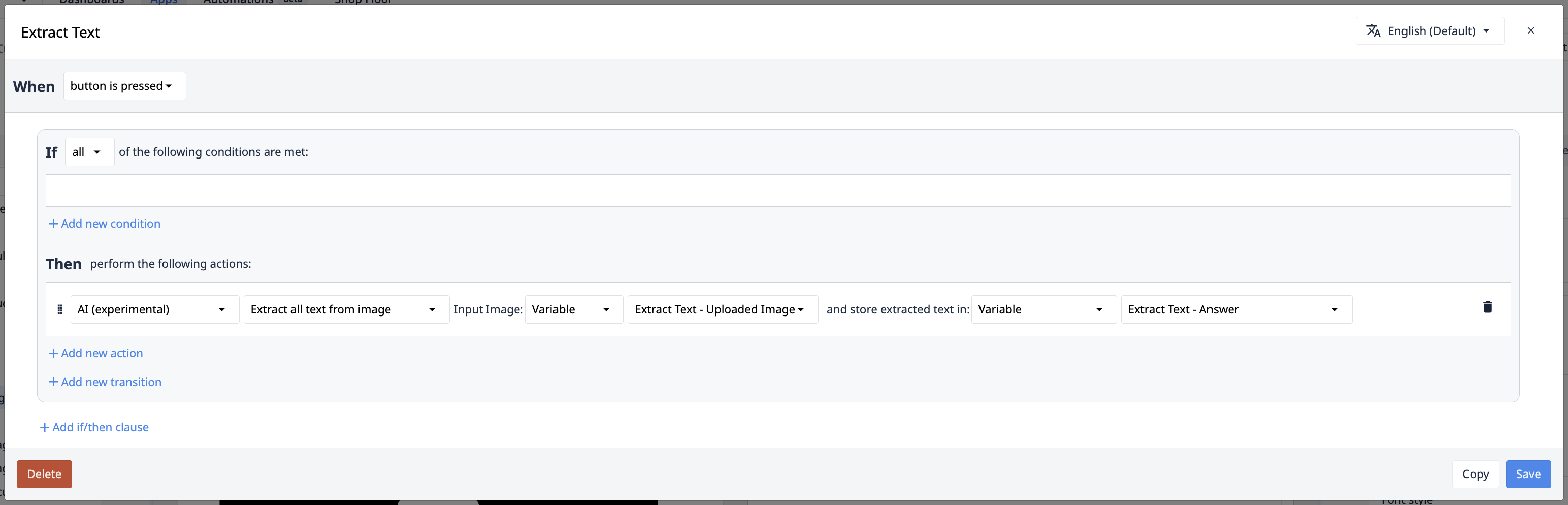
Вход: Входное изображение/документ
Это изображение, из которого должен быть извлечен текст. Оно может быть получено из виджета ввода камеры, Tulip Vision или внешних систем. Для файлов это значение может задаваться статически, вводиться с помощью виджета ввода файлов или ссылаться на файлы, хранящиеся в таблицах.
| Поддерживаемый тип данных | |
|---|---|
| Вход | URL-адрес изображения или URL-адрес файла |
Выходные данные: Извлеченный текст
Это весь текст, найденный на соответствующем изображении или документе. Документы возвращают массив данных, каждый элемент которого представляет собой текст с одной страницы предоставленного документа.
| Поддерживаемый тип данных | |
|---|---|
| Выходные данные | (для изображений) Текст. (для документов) Список текстов |
Краевые случаи
Не предоставлено входное изображение и/или запрос
Если в действии триггера нет входного изображения или запроса, приложение выдаст следующую системную ошибку*:Your Input or Query is empty*
Это происходит во всех следующих случаях:* Входному изображению и/или запросу не присвоено значение. Это эквивалентно значению "null".* Запросу присвоена пустая строка.
Нет результата для запроса
Если для запроса не было найдено результатов, триггерное действие вернет пустой текст.
Лимиты
The following languages are the only languages supported for documents where values are being extracted: English, Spanish, Italian, Portuguese, French, German.
В настоящее время для триггеров "Извлечение текста из изображения" существуют следующие ограничения. Эти лимиты отслеживаются на уровне экземпляра. В случае превышения этих лимитов действие триггера "Извлечение текста из изображения" завершится неудачей.