
This feature is only available on "Enterprise" plans and above.
Diagrama de exportação e importação
Abaixo está o fluxo de transferência completo para tabelas, consultas e agregações da Tulip. Este documento fornecerá uma explicação detalhada desse fluxo.
Campos de usuário personalizados e tabelas de atividade de máquina
O fluxo descrito abaixo também se aplica à forma como as tabelas de campos de usuário personalizados e as tabelas de campos de atividade da máquina são exportadas e importadas.
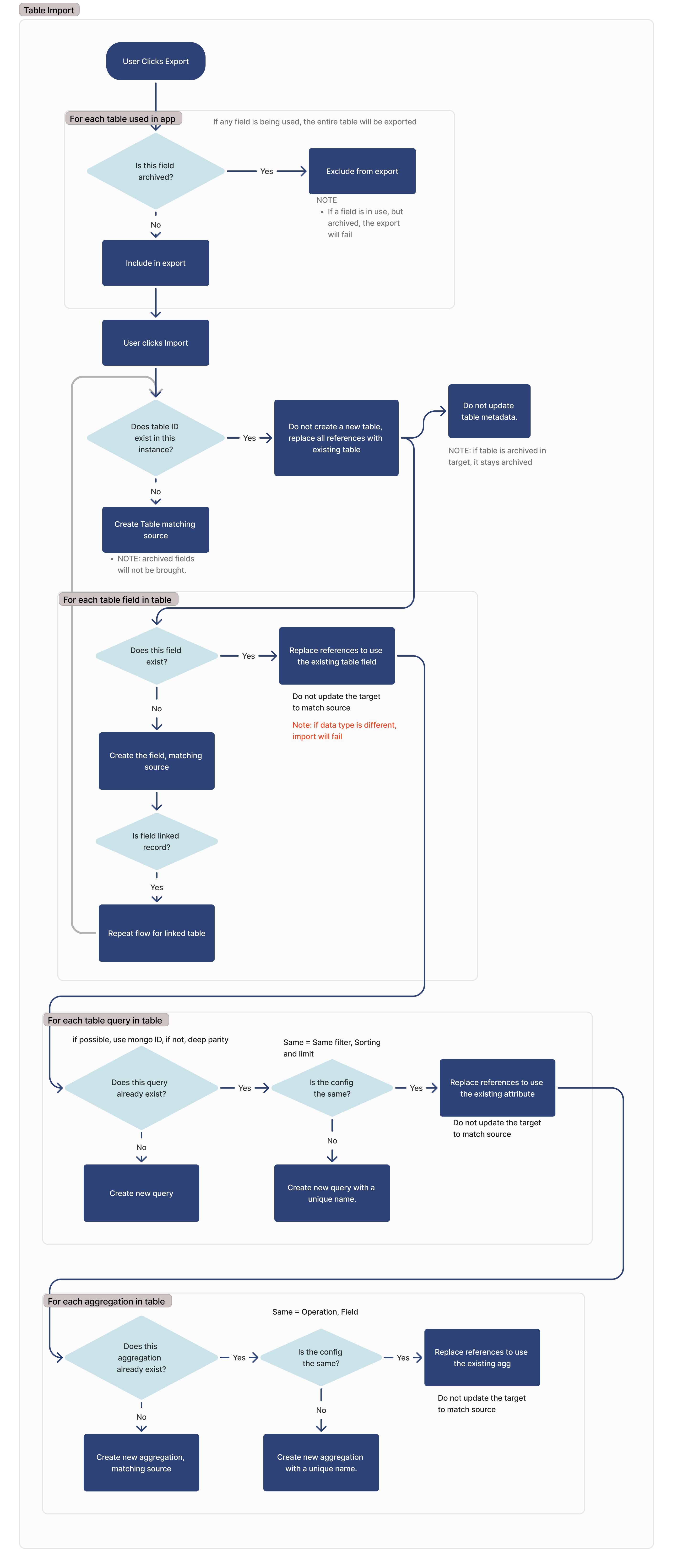
Exportação
Durante o processo de exportação, o aplicativo ou a automação exportada informará todas as tabelas em uso nesse aplicativo. Uma tabela é considerada em uso se qualquer uma das seguintes condições for atendida:
- Mostrada em um widget "Table Record" (Registro de tabela)
- Usada em um widget de entrada
- Exibida em uma tabela interativa
- Usada em um acionador
- Usada em uma ação de automação
- Usado em um bloco de eventos de automação
- Usado em um filtro para uma consulta de tabela, tabela interativa ou widget de análise
- Usado como uma entrada ou saída para um widget personalizado
Se um campo estiver arquivado, ele não será exportado. Se um campo estiver arquivado, mas em uso, a exportação falhará.
Importar
Archived table fields will not be exported, and any references to those fields within applications will need to be remapped on import.
Localizar uma mesma tabela
Para identificar tabelas correspondentes na importação, procuramos IDs correspondentes. Se for encontrada uma tabela com o mesmo ID, não criaremos uma nova tabela e usaremos a existente.
Se a tabela no site de importação estiver arquivada, ela permanecerá arquivada.
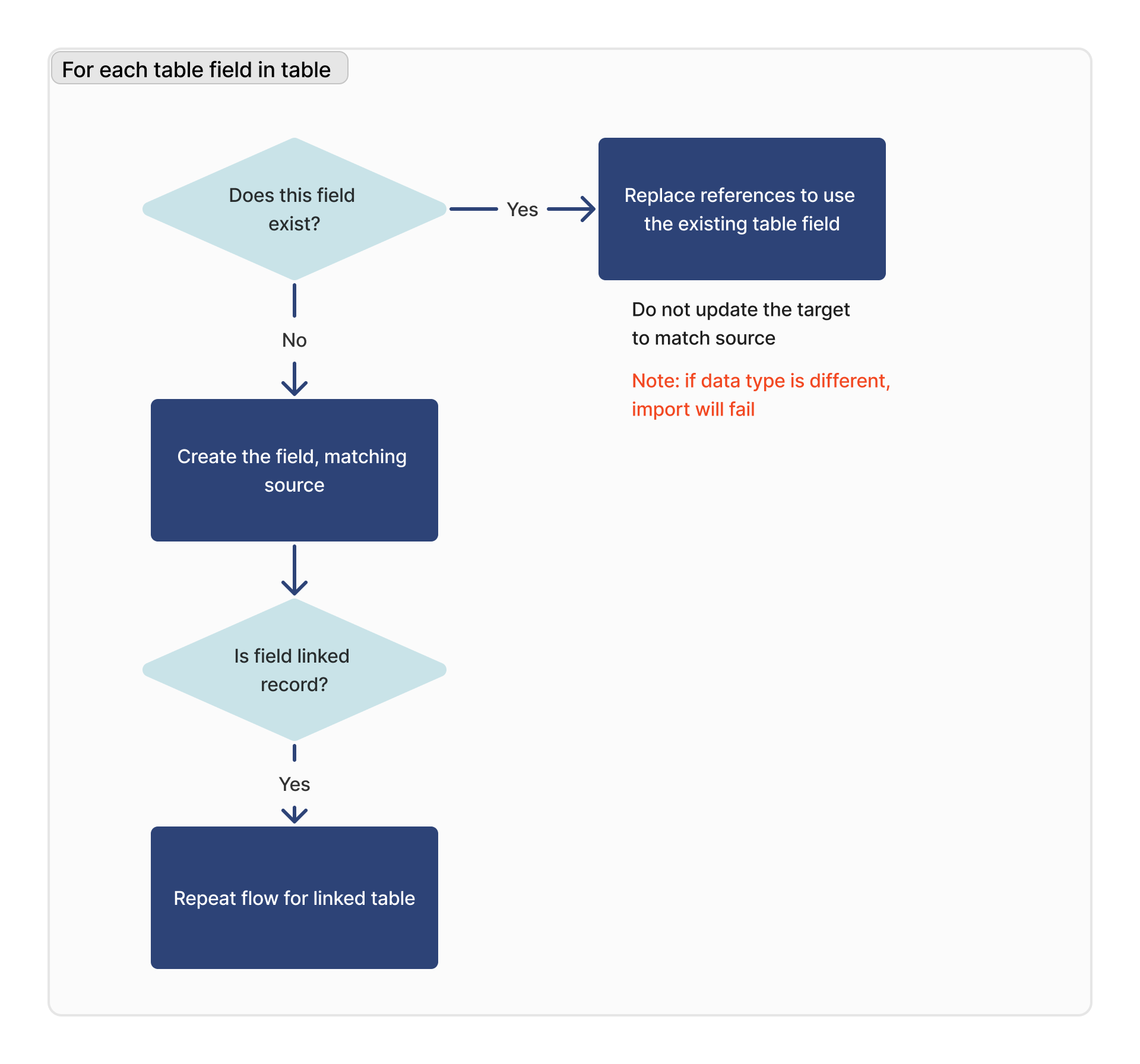
Para cada campo da tabela
Para cada campo da tabela, procuramos um campo correspondente com base no ID da coluna desse respectivo campo.
Se o tipo de dados do campo correspondente for diferente, a importação falhará.
Se o campo for um campo de registro vinculado, a tabela vinculada será adicionada à lista de dependências para a importação, e esse fluxo será repetido para essa tabela.
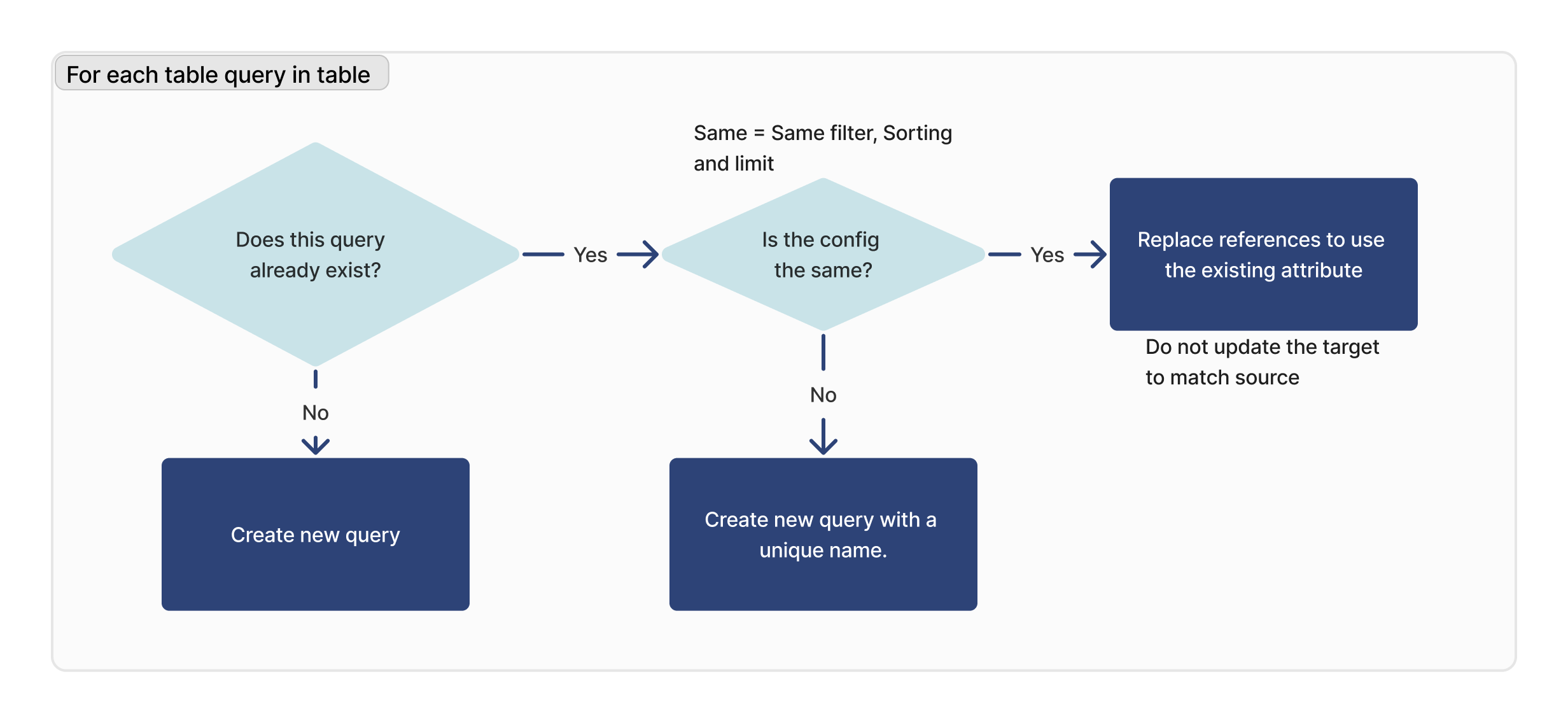
Para cada consulta
Para cada consulta na tabela importada, verificamos se essa consulta existe. Se for encontrado um ID correspondente, verificaremos se a configuração é idêntica (limite, classificação e filtragem) entre o destino e a origem.
Se não for possível encontrar uma consulta correspondente, será criada uma nova consulta. Se for encontrada uma consulta correspondente, mas ela não for idêntica à instância de destino, será criada uma nova consulta com um novo nome.
Observação: isso não se aplica a campos de usuário personalizados ou a tabelas de atividade de máquina.
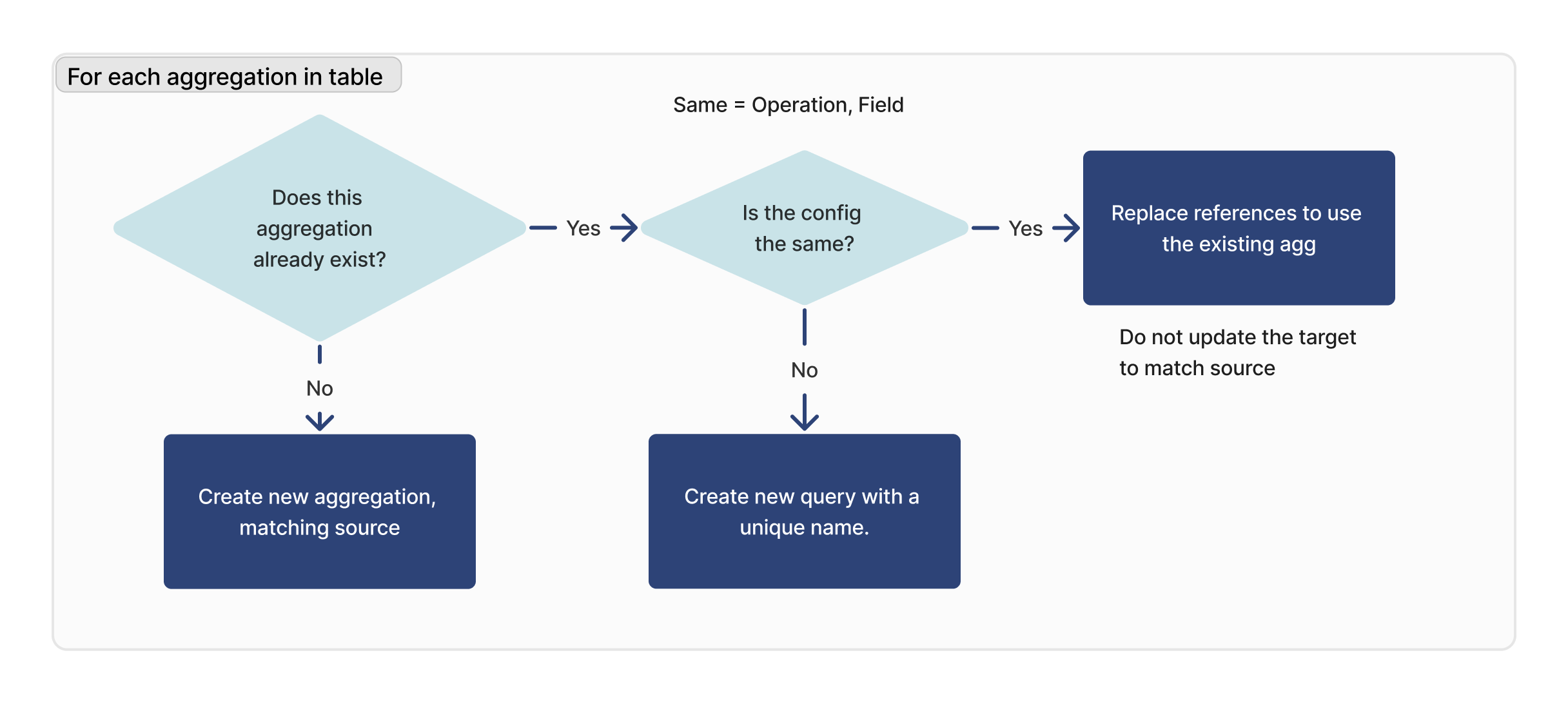
Para cada agregação
Para cada agregação na tabela importada, verificamos se essa consulta existe. Se for encontrado um ID correspondente, verificaremos se a configuração é idêntica (operação, campo) entre o destino e a origem.
Se não for possível encontrar uma consulta correspondente, será criada uma nova consulta. Se for encontrada uma consulta correspondente, mas ela não for idêntica à instância de destino, será criada uma nova consulta com um novo nome.
Observação: isso não se aplica a campos de usuário personalizados nem a tabelas de atividades da máquina.