содержание x
- Первая фаза.
- Здание
- Дизайн приложений
- Повышение ценности бизнеса с помощью исследований пользователей
- Лучшие практики проектирования приложений
- Кредо решения проблемы тюльпанов
- Композитные и монолитные архитектуры Обновление
- How to Design a Tulip Solution
- Как создавать композитные приложения
- Как разработать эффективный макет базы
- Лучшие практики присвоения имен элементам в Tulip
- Как добавить фигуры в шаги приложения
- Редактор приложений
- Знакомство с редактором приложений Tulip
- Создание нового приложения Tulip
- Как использовать сочетания клавиш в редакторе и проигрывателе приложений
- Многоязычная функция в Tulip
- Шаги
- Виджет
- Что такое виджет?
- Виджеты ввода
- Встроенные виджеты
- Виджеты с кнопками
- Как настроить виджеты
- Добавление виджетов ввода в шаги Обновление
- Что такое виджет интерактивной таблицы?
- Product Docs Template
- Как вставлять видео
- Как встроить аналитику в приложение
- Работа с файлами
- Динамическое заполнение виджетов Single или Multiselect
- Как использовать виджет флажка
- Как добавить виджет штрих-кода
- Как добавить виджет сетки в шаг
- Как копировать/вставлять содержимое в приложениях и между приложениями
- Как добавить виджет датчика на свой шаг
- Обзор пользовательских виджетов Обновление
- Создание формы подписи Шаг
- Проверка достоверности данных с помощью виджетов ввода Обновление
- Обзор виджета истории записей
- Технические детали шагов формы
- Как добавить изображения в приложение
- Как использовать виджет электронной подписи
- Форматирование чисел в приложениях Обновление
- Innesco
- Что такое триггеры?
- Триггеры ступенчатого уровня
- Триггеры уровня приложений
- Триггеры виджетов
- Руководство по переходам между приложениями
- Capture App Screenshot
- Триггеры таймера
- Как добавить триггеры для устройств
- Как добавить триггеры с условиями (утверждения If/Else)
- Список действий и переходов в редакторе триггеров
- Каковы 10 наиболее распространенных триггеров?
- Как установить цвет виджета с помощью триггера
- Как отправлять электронные письма
- Как настроить пользователей Tulip для получения SMS-уведомлений
- Как печатать шаги из триггера
- Как использовать редактор выражений в редакторе приложений
- Технические детали редактора выражений
- Полный список выражений в редакторе приложений
- Использование выражений времени суток
- Типовые выражения
- Использование выражений с массивами и объектами
- Работа со временем в триггерах
- Поддерживаемые пользовательские форматы времени
- Как заполнить приложение
- Как сканировать штрих-коды и QR-коды с помощью камеры устройства
- Как добавить регулярное выражение в триггер
- Использование информации о приложении в приложениях Tulip
- Как вызвать функцию коннектора с помощью триггеров
- Переменная
- Решение проблем
- Дати (индуистская богиня)
- Разъем
- Что такое коннекторы?
- Как создать коннектор
- Введение в хосты коннектора Tulip
- Как запустить функцию коннектора в нескольких средах
- Создание моментальных снимков коннектора
- Понимание массивов и объектов в выходных данных функций коннектора
- Отображение интерактивных списков записей таблицы или вывод коннектора в приложениях
- Поиск и устранение неисправностей разъемов
- Совместное использование разъемов в рабочих пространствах
- Разъем Управление входным кодированием
- Как создать тестовую базу данных для функции коннектора
- Как установить быстроразъемные соединения
- HTTP-коннекторы
- SQL-коннекторы
- MQTT-соединения
- Интеграция разъемов
- Анализы
- Что такое анализ?
- Введение в Analytics Builder
- Как создать новый анализ
- Обзор типов дисплеев Обновление
- Типы шаблонов, объяснение
- Как использовать универсальный шаблон
- Форматирование чисел в аналитике
- Введение в слои диаграммы Обновление
- Что такое диаграмма управления?
- Оповещения для контрольных диаграмм
- Как встроить аналитику в приложение
- Как анализировать данные из нескольких приложений
- Использование машинных данных в редакторе аналитики
- Понимание диапазонов дат
- Список полей в контекстной панели аналитики
- Как использовать редактор выражений в редакторе аналитики
- Технические детали редактора выражений
- Полный список выражений в редакторе аналитики
- Как изменить аналитику приложений
- Что такое слой прогноза?
- Пример анализа
- Как рассчитать выход по первому проходу с помощью анализа чисел
- Как создать аналитику на основе таблиц
- Как анализировать контрольные листы проверки качества с помощью анализа "множественных переменных"
- Как сравнить дефекты по типу и по дням с помощью поля "Сравнить по"
- Как просмотреть статистику времени цикла по пользователям с помощью табличного анализа
- Как построить диаграмму Парето для типичных дефектов
- Как создать первую приборную панель цеха
- Как обмениваться аналитическими данными или информационными панелями
- Как создавать информационные панели
- Vision
- Начало работы с Vision
- Vision Centre
- Функции Tulip Vision
- Рекомендации и ограничения по сканированию штрихкодов Vision
- Использование детектора цвета
- Использование детектора изменений
- Использование джиг-детектора
- Использование виджета камеры Vision в приложениях
- Использование функции моментального снимка в Vision
- Использование детекторов матриц и штрихкодов
- Использование детектора оптического распознавания символов (OCR)
- Использование снимка экрана в качестве источника изображения для камеры
- Tulip Vision Integrationen
- Решение проблем с глазами
- Мониторинг оборудования
- Введение в мониторинг оборудования
- Как настроить вашу первую машину
- Как использовать машинные выходы в триггерах
- Как создать свой первый источник данных OPC UA
- Как создать свой первый MQTT-коннектор
- Как добавить виджет машины в приложение
- Как подготовить машины к подключению к Tulip
- Как добавить атрибуты машины, причины простоя и состояния
- Запись в атрибуты машины с помощью протоколов OPC UA/MQTT Обновление
- Использование пограничных устройств для запуска хоста коннектора On Prem Connector
- Использование Edge MC для запуска OPC UA
- Как использовать API атрибутов машины
- Как настроить типы машин
- Как добавлять и настраивать машины
- Как создать свой первый машинный триггер
- Рекомендации по архитектуре машинного мониторинга с помощью Tulip
- Регулируемые отрасли
- Основы создания приложений GxP
- Лучшие практики создания приложений GxP
- Краткое описание возможностей Tulip в области GxP
- Сбор данных по GxP
- Исправления в данных о процессах и их обзор
- Функциональность паузы и возобновления
- Использование виджета истории записей для просмотра изменений в записях таблицы
- Как экспортировать данные приложения в CSV
- Проверка данных на соответствие требованиям GxP
- Проверка достоверности данных с помощью виджетов ввода Обновление
- Настройка ролей пользователей Обновление
- Как использовать виджет электронной подписи
- Второй пилот на передовой
- Использование и цены Frontline Copilot
- Виджет чата для операторов
- Страница настроек Frontline Copilot
- Tulip AI Composer
- Перевести действие триггера
- Извлечение текста из изображения Триггерное действие Обновление
- Ответ на вопрос из триггерных действий с данными/документами
- Классифицировать действие триггера
- Речевой ввод
- Чат с таблицами
- Часто задаваемые вопросы по управлению Frontline Copilot
- Автоматизация
- Начало работы с автоматизациями
- Обзор редактора автоматизаций
- Как настроить автоматизацию по расписанию
- Как использовать версии автоматизаций
- Как использовать историю выполнения автоматизаций
- Пределы автоматизации
- Решение для управления запасами с автоматизацией
- Предупреждение о зацикливании в автоматизациях
- Экспорт в импорте
- Дизайн приложений
- Выполнение приложений
- Как использовать проигрыватель "Тюльпан
- Как запустить приложение в Tulip Player Обновление
- Выбор между приложениями Tulip Web Player и Tulip Player
- Как переключаться между несколькими учетными записями Tulip
- Как использовать Tulip Player на Apple iOS и iPadOS
- Языки, поддерживаемые в Tulip
- How to access your Tulip Player/Instance in an iFrame
- Как запускать приложения Tulip на разных устройствах
- Как устранить неполадки с проигрывателем Tulip Player
- Рекомендуемые устройства для запуска Tulip Player Обновление
- Как перезапустить Tulip Player, если экран погас
- Как экспортировать данные приложения в CSV
- Управление
- Конфигурация экземпляра Tulip
- Управление пользователями
- Введение: Управление пользователями
- Добавление и управление пользователями
- Обновление полей отдельных пользователей и операторов Tulip из приложений
- Настройка ролей пользователей Обновление
- Создание и управление группами пользователей
- Авторизация и управление доступом с помощью SAML
- Как добавить RFID-карту нового оператора с помощью RFID-считывателя
- Управление приложениями
- Интро: Управление приложениями
- Обзор публикации приложений
- Добавление и управление приложениями
- Создание и управление версиями приложений
- Настройка утверждений для ваших приложений
- Изменение разрешений на редактирование отдельных приложений
- Восстановление версии приложения для разработки из опубликованной версии
- Сравните версии приложений
- Как восстановить архивированные приложения
- Медицинский менеджмент
- Управление рабочим пространством
- Управление игроками
- Linux Player
- Характеристики игроков по платформам Обновление
- Поведение при выходе игрока из системы
- Как скрыть меню разработчика в Tulip Player
- Как отключить автоматические обновления для Tulip Player
- Разрешение ошибок резервной базы данных
- Использование Tulip Player с разными учетными записями Windows
- Корпоративные развертывания Tulip Player
- Обзор станций и интерфейсов Обновление
- Как устранить неполадки с проигрывателем Tulip Player
- Developers
- Connect to Software
- Connectors
- Что такое коннекторы?
- Как создать коннектор
- Введение в хосты коннектора Tulip
- Конфигурация и технические детали OAuth2.0
- Как запустить функцию коннектора в нескольких средах
- Создание моментальных снимков коннектора
- Понимание массивов и объектов в выходных данных функций коннектора
- Разъем Управление входным кодированием
- Как создать и настроить функцию HTTP-коннектора
- Как форматировать выходные данные HTTP-коннектора
- Использование HTTP-коннекторов в приложениях
- Как написать функцию коннектора SQL
- Обзор функций MQTT
- Как создать свой первый MQTT-коннектор
- Руководство по интеграции экосистем
- Интеграция с Amazon Bedrock
- Интеграция с AWS - получение всех таблиц Tulip и запись в S3
- Интеграция с AWS - отправка данных в AWS через API-шлюз и Lambda
- Интеграция с AWS - получение данных из таблиц Tulip
- AWS Integration - Fetch All Tulip Tables in Lambda Function
- Пример сценария ETL Glue для загрузки данных таблицы Tulip
- Интеграция с IoT Sitewise
- Бережливое ежедневное управление с AWS
- Интеграция машинного обучения в Microsoft Azure
- Интеграция с Microsoft Fabric
- Интеграция Rockwell FactoryTalk Optix
- Интеграция Snowflake с Fabric - получение таблиц Tulip в Snowflake
- Connectors
- Connect to Hardare
- Edge Devices
- Борде И.О.
- Рэнд MC
- Машинный комплект
- Пасарела IO
- Объявление об окончании продаж шлюза ввода-вывода
- Настройка шлюза ввода-вывода Tulip
- Как зарегистрировать шлюз ввода/вывода
- Сброс шлюза ввода/вывода к заводским настройкам
- Как включить удаленную поддержку шлюза ввода/вывода
- Как использовать аналоговые входы на шлюзе ввода/вывода
- Как использовать универсальный драйвер последовательного интерфейса на шлюзе ввода/вывода
- Технические характеристики шлюза ввода/вывода Tulip
- Fabrik-Kit
- Краткое руководство по эксплуатации заводского комплекта
- Информация о материалах и закупках заводского комплекта
- Настройка световых лент Edge IO
- Испытание блока датчика прерывистого света
- Как настроить ножную педаль в Tulip
- Модульные тесты датчиков температуры и влажности
- Как включить устройства из заводского комплекта в приложения
- Начальная установка комплекта светильников "Тюльпан
- Как использовать набор для подсветки тюльпанов
- Подключение USB-устройств заводского комплекта (штрих-код, ножная педаль, температура/влажность)
- Настройка датчика прерывистого луча
- Испытание блока светового комплекта
- Технические характеристики комплекта Tulip Light Kit
- Сборка светового стека
- Управление периферийными устройствами
- Как включить HTTPS на устройстве Edge
- Как настроить портал устройств
- Как управлять пограничными устройствами в Tulip
- Поддерживаемые версии микропрограммного обеспечения
- Как управлять автоматическими обновлениями устройств Edge
- Как настроить параметры сети на устройстве Tulip Edge
- Как настроить интерфейс LAN пограничного устройства
- Как устройства Tulip Edge получают свой IP-адрес
- Как настроить параметры SNMP для пограничных устройств
- Как узнать версию ОС устройства Edge
- Часто задаваемые вопросы об устройстве Tulip Edge Device
- Портал HTTPS для пограничных устройств
- Тематические исследования для терминального оборудования
- Пограничные устройства и FlowFuse
- Как включить и настроить MQTT-брокер Edge Device
- Как настроить мост MQTT на пограничном устройстве
- Использование Edge MC для запуска OPC UA
- Как использовать GPIO на Edge IO
- Использование Node-RED с Edge MC
- Использование Node-RED с Edge IO
- Как: Использование последовательного интерфейса с Edge IO
- Использование пограничных устройств для запуска хоста коннектора On Prem Connector
- Обмен данными с машинами с помощью коннектора Edge MC's Connector Host & Node-RED
- Что можно сделать с помощью Tulip + IoT
- Устранение неисправностей устройств Tulip Edge
- Совместимые устройства
- Список устройств Plug And Play, которые работают с Tulip
- Создание и поддержка драйверов устройств
- Поддержка драйверов устройств в Tulip
- Как настроить сканер штрих-кодов
- Использование драйвера последовательного интерфейса
- Как интегрировать принтер Zebra с Tulip
- Использование драйвера сетевого принтера Zebra
- Использование драйвера принтера этикеток Zebra серии GK
- Использование драйвера USB-бокса
- Использование драйвера Cognex In-Sight 2000
- Как настроить Cognex и Tulip
- Использование драйвера рН-метра MT SevenExcellence
- Использование драйвера АЦП общего назначения
- Использование драйвера термометра Omega HH806
- Использование драйвера цифрового штангенциркуля
- Как настроить температурный пистолет General TS05 Bluetooth
- Использование TCP-драйвера Cognex DataMan
- Настройка приемника Mitutoyo U-WAVE для Windows Tulip Player
- Использование драйвера шкалы Brecknell PS25
- Использование драйвера RFID
- Использование драйвера Kolver EDU 2AE/TOP/E
- Использование драйвера ножной педали USB
- Использование драйвера открытого протокола Torque
- Использование драйвера USB-шкалы Dymo M10
- Использование драйвера Cognex In-Sight
- Использование драйвера Telnet
- Использование драйвера ввода/вывода Generic
- Как настроить контроллер крутящего момента Kolver
- Использование многоканального калиперного драйвера Insize
- Использование драйвера USB-весов Dymo S50
- Конфигурация Zebra Android DataWedge
- Использование цифрового штангенциркуля Mitutoyo с U-волновым драйвером Mitutoyo
- Как добавить весы Ohaus и хранить результаты в переменной
- Модульные тесты датчиков температуры и влажности
- Troubleshoot
- Нодо-Россо
- Обзор Node-RED
- Инструкции
- Обновление Node-RED
- Отправка данных из Node-RED в Tulip с помощью узлов Tulip Обновление
- Отправка сообщений из Tulip в Node-RED
- Использование Node-RED с API Tulip
- Как: Использование последовательного интерфейса в Node-RED
- Импорт потоков Tulip Node-RED
- Как: Использование последовательного интерфейса с Edge IO
- Тематические исследования
- Как настроить устройства Modbus
- Как настроить устройства Banner PICK-IQ с помощью Edge IO
- Как отправлять данные на машины с пограничных устройств с помощью Node-RED и меток Tulip
- Обмен данными с машинами с помощью коннектора Edge MC's Connector Host & Node-RED
- Подключение датчика 4-20 мА с помощью Edge IO и Node-RED
- Управление состояниями машины и количеством деталей с помощью Edge IO и Node-RED
- Подключение аналогового осциллографа с помощью Edge IO и Node-RED
- Подключение проводных фиджетов к Edge MC и Node-RED
- Edge Devices
- Написание многократно используемых компонентов
- Работа с API
- Edge Driver SDK
- Connect to Software
- Техническая и ИТ-документация
- Расписание мероприятий по техническому обслуживанию Обновление
- Как получить поддержку Tulip Обновление
- ИТ-инфраструктура
- Путеводитель по Tulip IT
- Настройка списка разрешенных IP-адресов
- Обзор вариантов обеспечения безопасности Tulip
- Руководство по информационной безопасности Tulip Обновление
- Введение в хосты коннектора Tulip
- Tulip & Device Architecture
- Поддержка версий хоста локального коннектора Новые функции
- Включение ротации журналов для существующего локального контейнера Connector Host
- Рекомендации по архитектуре машинного мониторинга с помощью Tulip
- Подробная информация о виртуальной машине Tulip On-Premise
- Компоненты и сетевая диаграмма платформы Tulip
- Развертывание Tulip в AWS GovCloud
- Как использовать прокси-сервер с Tulip Player в Windows
- Обзор локальных узлов коннекторов
- Сетевые требования для развертывания Tulip Cloud Обновление
- Форма W-9 для тюльпанов
- Каковы политика и инфраструктура кибербезопасности компании Tulip?
- LDAP/SAML/SSO
- Как пользоваться партнерским порталом Tulip
- Гиды
- На пути к цифровой трансформации
- Use Cases by Solution
- Примеры
- Как получить информацию о рабочих заказах по рабочим станциям в режиме реального времени
- Учебник по применению 5S-аудита
- Как создать автоматизированное приложение для создания отчетов об отклонениях
- Как спланировать первое приложение для фронтальных операций
- Как отслеживать аудиты оборудования в таблице
- Как автоматизировать заказы на выполнение работ в приложении для фронтальных операций
- Как использовать производственные приложения в условиях высокой проходимости
- Как создать цифровое приложение с рабочими инструкциями
- Как отслеживать генеалогию продукта с помощью таблиц
- Как добавить весы Ohaus и хранить результаты в переменной
- Как сделать вычет из таблицы инвентаризации по завершении операции
- Как использовать "шаблон пользовательского интерфейса" рабочих инструкций
- Как создать матрицу навыков с помощью пользовательских полей
- Как создать таблицу спецификации материалов (BOM)
- Как управлять запасами с помощью таблиц
- Как передавать динамические данные между несколькими приложениями с помощью пользовательских полей
- Как перемещаться между несколькими приложениями, создав "маршрутное приложение"
- 📄 Отслеживание заказов
- 📄 Возможность отслеживания неисправностей
- Библиотека
- Использование библиотеки Tulip Обновление
- Laboratory Operation App Suite
- Библиотечные фонды
- Библиотечные приложения
- Учебные примеры
- Функциональные примеры
- Функциональный пример Andon
- Функциональный пример инспекции
- Функциональный пример данных Tulip Data
- Функциональный пример Duro PLM
- Technicon - Универсальные роботы Функциональный пример
- Объединенный производственный центр - функциональный пример
- Пример контрольной диаграммы
- Фотогалерея
- Модульный тест AI - вопросы и ответы по документу
- Решения для применения
- Пакет прикладных программ для CMMS
- Zerokey solutions
- Наглядность результатов
- Пакет документов для подачи заявки на электронную декларацию на партию товара (eBR)
- CAPA Lite от PCG
- 5 Почему устранение причин с помощью искусственного интеллекта
- Простой отчет о дефектах с помощью искусственного интеллекта
- Построитель бизнес-кейсов
- Совещание для начинающих сменщиков
- Kanban App Suite
- Простая приборная панель OEE
- Решение Arena BOM
- Комплект приложений для управления оборудованием
- Простой контрольный список
- Пакет управления контрольными списками
- Простое решение для управления посещаемостью
- Приложения для библиотеки Pack & Ship
- Управление CAPA
- Приложение для мобильных камер
- Калькулятор OEE
- Почасовая таблица производственных показателей
- Обратная промывка материала
- Приборная панель событий качества
- Применение первого прохода по урожайности
- От пикировки к свету
- Учебные решения
- Инвентаризация цифровых систем
- Отслеживание местоположения с помощью зрения
- Управление доступом к цифровым системам
- Управление материальными ресурсами
- Менеджер по инструментам и активам
- Качественное управление событиями
- Ступенчатое опережение с датчиком прерывистого света
- Цифровой секундомер
- Контрольный список аудита
- Приложение Katana ERP
- Базовая оценка высокого уровня
- Управление спецификациями
- Менеджер по инцидентам в области безопасности
- Composable Lean
- Composable Mobile
- Как подать заявку
- Пакет приложений eDHR
- Шаблон для обучения
- Комплекс приложений для управления качественными событиями
- Приложение для создания шаблонов пакетной упаковки
- Шаблон пользовательского интерфейса с макетом приборной панели
- Панель мониторинга оборудования
- Шаблон для отслеживания дефектов
- Конфигурация цвета
- Пример рабочей инструкции
- Шаблон дизайна
- Управление обучением
- Типовые рабочие инструкции
- Шаблон рабочей инструкции
- Шаблон пик-листа
- Основные шаблоны для создания приложений Tulip
- Панель управления потоками путешественников и материалов
- Шаблон для отслеживания заказов
- Учебные примеры
- Компостируемый МЭС
- MES-система для фармацевтического сектора.
- Коннекторы и модульные тесты
- Тест на тему "Планеус Обновление
- Разъем COPA-DATA Новые функции
- Veeva Connector
- Коннектор Inkit
- Коннектор MRPeasy
- Oracle Fusion Connector
- Коннектор LabVantage и модульное тестирование
- Коннектор чата Google
- Коннектор Salesforce
- Обзор Litmus
- Коннектор eMaint
- Коннектор eLabNext
- Коннектор Acumatica ERP
- Разъем CETEC
- Разъем PagerDuty
- Интеграция NiceLabel
- Обзор интеграции Aras
- Интеграция SDA
- Тест группы Nymi Band
- Интеграция арены Обновление
- Модульные тесты сканера штрих-кода
- Модульные тесты педалей
- Начало работы с Tulip на гарнитуре RealWear
- Разъем для подключения к воздушному столу
- Коннектор Shippo
- Интеграция с барменом
- SAP S/4 HANA Cloud Connector
- Модульные тесты RFID-сканера
- Коннектор Jira
- Тестирование устройства для печати этикеток Zebra
- Коннектор Google Translate
- MSFT Power Automate
- Коннектор OpenAI
- Коннектор календаря Google
- Модульный тест API Tulip
- Тестирование модулей Duro PLM
- Модульное тестирование HiveMQ
- Интеграция с NetSuite
- Тестирование модулей Cognex
- Интеграция с PowerBI Desktop
- Испытание устройства ProGlove
- Интеграция Fivetran
- Интеграция ParticleIO
- Коннектор Google Drive
- Коннектор "Снежинка Обновление
- Коннектор SAP SuccessFactors
- ZeroKey Integration
- Коннектор геокодов Google
- Коннектор Google Sheets
- Как интегрировать Tulip со Slack
- Тест модуля HighByte Intelligence Hub
- Юнит-тест LandingAI
- Тестирование устройства LIFX (беспроводные светильники)
- Коннектор календаря Microsoft
- M365 Dynamics F&O Connector
- Коннектор Microsoft Outlook
- Коннектор Microsoft Teams
- Подключите Microsoft Graph API к Tulip с помощью Oauth2
- Коннектор Microsoft Excel
- Приложения и коннектор NetSuite
- Разъем OpenBOM
- Модульные тесты весов
- Коннектор InfluxDB
- Коннектор Augury
- Коннектор ilert
- Разъем Schaeffler Optime
- MongoDB Atlas Connector
- Коннектор MaintainX
- Twilio Connector
- Коннектор SendGrid
- Коннектор Solace
- Как разрабатывать приложения Tulip для гарнитуры RealWear
- OnShape Connector
- Настраиваемые виджеты
- Пользовательский виджет планирования Новые функции
- Виджет временной шкалы
- Виджет просмотра дерева json
- Виджет управления задачами Kanban
- Виджет значка
- Продвинутый виджет таймера
- Пользовательский виджет сегментированной кнопки
- Пользовательский виджет Dynamic Gauge
- Виджет закусочной
- Тест блока детектора изменений
- Цветовой индикатор состояния Тест устройства
- Проверка длины входного сигнала Тест блока
- Модульное тестирование пользовательского виджета калькулятора
- Модульный тест виджета аннотации изображений
- Виджеты приборной панели Lean
- Тест блока Looper
- Тест блока секундомера
- Тест блока ввода номера
- Тест блока номерной панели
- Радиальные датчики
- Пошаговое тестирование модулей меню
- Виджет SVG
- Тест блока ввода текста
- Инструментальный совет Тест блока
- Инструкции по работе Точки ухода Единичный тест
- Написанное модульное тестирование виджета электронной подписи
- Модульный тест программы просмотра ZPL
- Виджет простого линейного графика
- Пользовательский виджет "Полки
- Виджет слайдера
- Пользовательский виджет NFPA Diamond
- Пользовательский виджет Pass - Fail
- Пользовательский виджет Simpler Timer
- Виджеты интеграции присутствия Nymi
- Автоматизация
- Check Expired Training
- Оповещение о событиях и эскалация: Управление просроченными событиями
- Почасовое уведомление о состоянии производства
- Обновление информации о состоянии оборудования для технического обслуживания
- Сброс состояния оборудования
- Сброс состояния калибровки
- Напоминание о проверке состояния машины
- Автоматизация обновления таблицы инвентаризации
- Автоматизация коннектора Slack
- Устройство для проверки количества деталей


Как использовать общую модель данных
Вводный текст
Вы нашли это резюме полезным?
Спасибо за ваш отзыв
Руководство по соблюдению общей модели данных и примеры ее создания.
Что такое общая модель данных?
Приложения можно объединять для решения конкретных задач, связывая производственные процессы с помощью таблиц в общей модели данных Tulip для дискретной продукции или общей модели данных для фармацевтической промышленности. В отличие от традиционных моделей данных, основанных на зависимостях, составная общая модель данных Tulip позволяет добавлять таблицы со временем в зависимости от конкретного случая.
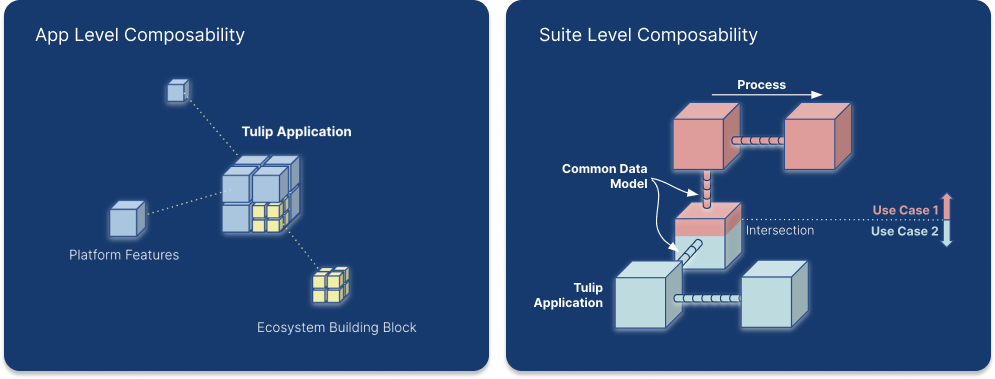
Общая модель данных представляет собой набор стандартизированных и расширяемых схем данных. Эти предопределенные схемы охватывают различные типы данных, включая операционные артефакты, физические артефакты, справочные материалы и журналы событий. Представляя широко используемые понятия и действия, такие как заказы на выполнение работ и подразделения, эти схемы облегчают создание, сбор и анализ данных. Такая стандартизация помогает упростить работу с данными в различных системах.
Общая модель данных в системе Composability
Таблицы Tulip Tables играют важнейшую роль в обработке потоков данных и поддержании связи между приложениями. Они содержат информацию, которая отображается в приложениях, а приложения создают, обновляют и удаляют записи в таблицах. Если несколько приложений используют одни и те же таблицы, они могут взаимодействовать друг с другом через таблицы.
Например, менеджер создает рабочий заказ в одном приложении, а оператор выполняет этот заказ в другом приложении или наборе приложений.
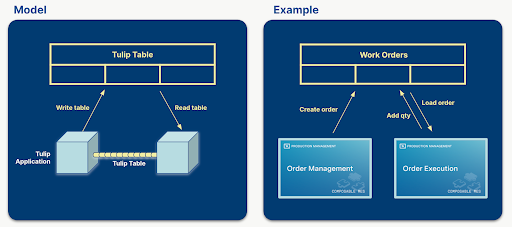
При разработке решения для конкретной задачи определение таблиц, которые будут использоваться, является одним из наиболее важных шагов. Логичный выбор таблиц может привести к созданию более простых, многократно используемых и композитных приложений. Если в таблицах хранится нужное количество данных, конструктор приложений может уменьшить количество используемых переменных, что делает приложение менее сложным и легко настраиваемым. Если приложения в рамках решения используют один и тот же набор таблиц, приложения становятся взаимозаменяемыми или композитными, без необходимости перепроектировать одно или другое приложение.
Лучшие практики
Note
To understand tables that comprise a common data model, it's important to know the Best Practices for Storing Data in Tulip.
Таблицы Tulip должны в первую очередь следовать модели Digital Twin, то есть таблицы должны как можно точнее отражать физический завод или цех. Исторические данные приложения должны быть ограничены записями о завершении производства, а таблицы не должны использоваться для хранения основных данных или дублирования данных из записей о завершении производства или внешних записей.
Основные типы таблиц
В идеале таблицы должны представлять физические и эксплуатационные артефакты.
Эти таблицы всегда будут включать поле Status, которое будет регулярно обновляться приложениями.
На диаграмме ниже показаны полные таблицы в общей модели данных и таблицы, которые следует использовать для дискретного производства и фармацевтики.
Вот разбивка всех типов таблиц в Общей модели данных:
Физические артефакты
Физические артефакты - это материальные объекты на вашем предприятии или компоненты, которые используются или производятся в процессе работы. Когда состояние физического артефакта меняется или обновляется, это изменение отражается в записи (например, изменение статуса).
Существует две категории физических артефактов:
1. АктивыК активамотносятся компоненты, которые оснащают, содержат или выполняют процесс, такие как: * Оборудование * Весы * Места.
2. МатериалыМатериалы- это предметы, используемые или создаваемые в процессе, такие как: * Инвентарные предметы * Единицы * Партии
Операционные артефакты
Оперативные артефакты - это материальные или нематериальные элементы или компоненты, которые обеспечивают или поддерживают операции.
Существует три категории операционных артефактов:
1. ЗадачиЗадачивключают в себя процесс, поддающийся действию, например: * результаты проверок * карточки Канбан.
2. СобытияСобытиявключают в себя нечто произошедшее, например: * Дефекты * Исправления
3. ЗаказыЗаказысодержат информацию о товарах или услугах, например: * Заказы на выполнение работ * Заказы на обработку
Вторичные (расширенные) типы таблиц
Бывают случаи, когда необходимо отступить от лучших практик. В более сложных обстоятельствах - и как можно реже - вам может понадобиться использовать следующие два вторичных типа таблиц:
- Журнал
- Ссылка .
Данные в этих таблицах, скорее всего, будут статичными и не будут обновляться (именно поэтому предпочтительнее хранить эти типы данных либо в записях завершения, либо в исходной, внешней системе).
:::(Error)Secondary table types do not fit within a Digital Twin model and should only be considered by advanced users. You should only include these table types once you've gone through the Solution Design process and exhausted all other options. Secondary table types should NEVER serve as the foundation for an app solution.
:::
Журналы
Журналы событий - это информация, которую можно найти и определить в процессе производства. Их часто можно найти во внешних системах, таких как ERP. Поскольку исторические данные традиционно отслеживаются через App Completion и хранятся в Completion Records, использовать таблицу Log нужно ТОЛЬКО в том случае, если:* Вам нужно выделить определенные данные из записей завершения для целей визуализации* Вам нужно использовать эти данные в вычислениях, в частности в запросах и агрегатах.
Примеры:
- Примечания и комментарии
- Записи родословной
- История деятельности станции
- Результаты инспекции
Вы НЕ должны обращаться к таблицам журналов для:* Исторических записей* Прослеживаемости
Ссылки
Ссылки - это общие учетные записи между приложениями. Это похоже на концепцию записи о завершении, за исключением того, что она разделяется между приложениями и делает доступными запросы к таблицам, Aggregation и изменяемость таблиц Tulip.
По возможности данные следует получать в режиме реального времени непосредственно из первоисточника - например, ERP - через HTTP-коннектор. Использование справочной таблицы может потребоваться в некоторых случаях, например:* Временно, при установлении соединения с ERP.* Если внешняя система содержит ограниченные справочные данные, которые необходимо дополнить с помощью Tulip.
Ваш подход будет меняться со временем, по мере того как решения будут совершенствоваться, а системы становиться более интегрированными и тесно связанными.
Примеры:
- Определения материалов
- Билль о материалах
Создайте свою собственную общую модель данных
Пример общей модели данных Tulip предназначен для того, чтобы стать отправной точкой для построения вашей модели данных. Однако все процессы и решения различны, и, как и приложения, модель данных может быть изменена по мере необходимости.
Небольшие изменения включают добавление и удаление полей из таблиц. В некоторых случаях (особые процессы, несколько таблиц, необходимых для одного и того же случая использования) требуются серьезные изменения. Это можно сделать, заменив одну или несколько таблиц из загруженной модели данных или вставив дополнительные таблицы.
Планирование общей модели данных
- Определите физические и операционные артефакты вашего процесса
- Найдите соответствующие таблицы для каждого артефакта
- Изучите типы данных, которые будут собираться приложениями, и ссылки, которые необходимо использовать.
Дальнейшее чтение
Table Aggregation
Aggregations are calculations on top of table data, this can include things like the average value of a column within a Tulip Table.
Была ли эта статья полезной?
Спасибо за ваш отзыв! Наша команда свяжется с Вами
Как мы можем улучшить эту статью?
Ваш отзыв
Комментарий
Комментарий (Необязательный)
Количество символов : 500
Пожалуйста, введите Ваш комментарий
Отправить по электронной почте (Необязательный)
Отправить по электронной почте
Пожалуйста, введите действительный адрес электронной почты
