How to Use a Common Data Model
- 07 Oct 2024
- 6 Minutes to read
- Contributors


- Print
How to Use a Common Data Model
- Updated on 07 Oct 2024
- 6 Minutes to read
- Contributors
- Print
Article summary
Did you find this summary helpful?
Thank you for your feedback
Guidance for adhering to a Common Data Model and examples of how to create one.
What is a Common Data Model?
Applications can be combined to solve use cases, connecting across manufacturing processes using tables in the Tulip Common Data Model for Discrete or Common Data Model for Pharma. Unlike traditional data models that rely on dependencies, Tulip’s composable Common Data Model allows tables to be added over time on a case-by-case basis.
A Common Data Model provides a collection of standardized and expandable data schemas. These predefined schemas cover various types of data, including operational artifacts, physical artifacts, reference materials, and logs of events. By representing widely used concepts and activities, such as Work Orders and Units, these schemas make it easier to create, compile, and analyze data. This standardization helps streamline data handling across different systems.
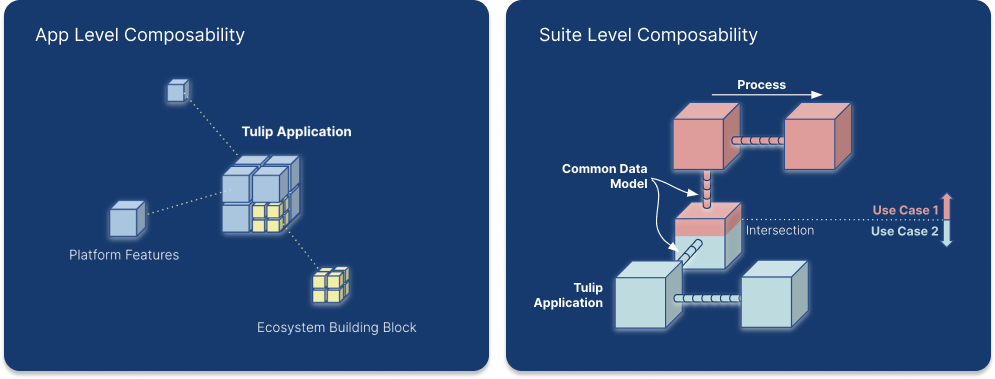
Common Data Model in Composability
Tulip Tables play a crucial role in handling data flows and maintaining the connection between applications. They contain information that is displayed in applications and applications are creating, updating and deleting Table Records. If multiple applications are using the same tables, they can communicate with each other through tables.
For example, a manager creates a work order in one app and an operator executes that work order in another app or set of apps.
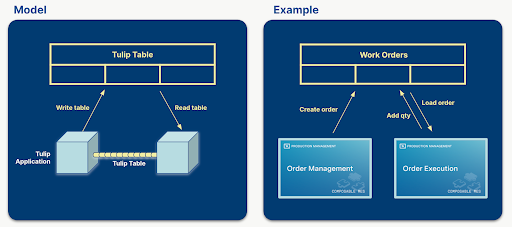
When designing a solution for a given problem, defining the tables that are going to be used is one of the most importance steps. Choosing tables logically can result in a simpler, more reusable, and composable applications. If the right amount of data is stored in tables, the app builder can reduce the number of used app variables, making the application less complex and easy to customize. If the applications within a solution are using the same set of tables, the apps become interchangeable or composable, without having to redesign one or the other application.
Best Practices
Note
To understand tables that comprise a common data model, it's important to know the Best Practices for Storing Data in Tulip.
Tulip Tables should primarily follow the Digital Twin model, meaning tables should reflect the physical plant or shop floor as strictly as possible. Historical app data should be confined to Completion Records, ensuring tables are not used to store master data or duplicate data from Completion Records or external records.
Primary Table Types
Ideally, tables should represent physical and operational artifacts.
These tables will always include a Status field that will be regularly updated by apps.
The diagram below shows the full tables in the Common Data Model and which tables to use for discrete manufacturing and pharma use cases.
Here is a breakdown of all the tables types in the Common Data Model:
Physical Artifacts
Physical artifacts are tangible objects in your facility or components that are used or produced during operations. When a physical artifact's state changes or updates, this change is reflected in the record (e.g. status change).
There are two categories of physical artifacts:
1. Assets
Assets involve components that equip, contain, or perform in a process, such as:
- Equipments
- Scales
- Locations
2. Materials
Materials involve the items used or created in a process, such as:
- Inventory Items
- Units
- Batch
Operational Artifacts
Operational artifacts are tangible or intangible elements or components that enable or support operations.
There are three categories of operational artifacts:
1. Tasks
Tasks involve an actionable process, such as:
- Inspection Results
- Kanban Cards
2. Events
Events involve something that has happened, such as:
- Defects
- Corrections
3. Orders
Orders involve information about goods or engagements, such as:
- Work Orders
- Process Orders
Secondary (Advanced) Table Types
There are times when you may need to consider breaking best practices. For more advanced circumstances—and as sparingly as possible—you might need to use following two secondary table types:
- Log
- Reference
The data in these tables will likely be static and will not be updated (which is why it is preferred to keep these types of data either in completion records or in the original, external system).
Secondary table types do not fit within a Digital Twin model and should only be considered by advanced users. You should only include these table types once you've gone through the Solution Design process and exhausted all other options. Secondary table types should NEVER serve as the foundation for an app solution.
Logs
Event Logs are information that can be looked up and defines something in production. These are often found in external systems such as an ERP. Since historical data is traditionally tracked via App Completion and stored to Completion Records, you ONLY need to use a Log table if:
- You need to separate specific data from the completion records for visualization purposes
- You need to use this data in calculations, specifically queries and aggregations
Examples:
- Notes & Comments
- Genealogy Records
- Station Activity History
- Inspection Results
You should NOT turn to Log tables for:
- Historical records
- Traceability
References
References are shared ledgers between applications. This is similar to the concept of a completion record except that it is shared across applications and makes accessible Table Queries, Aggregations and the mutability of Tulip Tables.
Wherever possible, data should be fetched in real-time directly from the original source—such as an ERP—via an HTTP Connector. You may need to use a Reference table in fringe cases such as:
- Temporarily, while establishing connection to an ERP.
- If your external system contains limited reference data that needs to be augmented with Tulip.
Your approach will evolve over time as solutions mature and systems become more integrated and tightly coupled.
Examples:
- Material Definitions
- Bill of Materials
Build your own Common Data Model
Tulip’s example Common Data Model is designed to be a starting point to build your data model. However, all processes and solutions are different and, like applications, the data model can be customized as needed.
Smaller changes include adding and removing fields from the tables. In some cases (special processes, multiple tables needed for the same use case) major changes are required. This can be done by substituting one or more tables from the downloaded data model or inserting additional tables.
Plan a Common Data Model
- Define the physical and operational artifacts of your process
- Find the respective tables for each artifact
- Explore the types of data to be collected by the applications and the references that need to be used
Further Reading
.gif)
Was this article helpful?