

Wskazówki dotyczące przestrzegania wspólnego modelu danych i przykłady jego tworzenia.
Czym jest wspólny model danych?
Aplikacje można łączyć w celu rozwiązywania przypadków użycia, łącząc procesy produkcyjne za pomocą tabel w Tulip Common Data Model for Discrete{target=_blank} lub Common Data Model for Pharma. W przeciwieństwie do tradycyjnych modeli danych, które opierają się na zależnościach, komponowalny wspólny model danych Tulip umożliwia dodawanie tabel w miarę upływu czasu w zależności od przypadku.
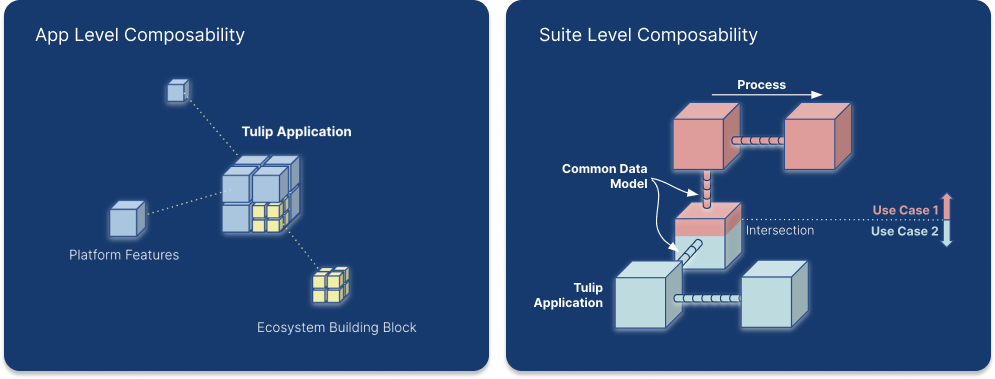
Common Data Model zapewnia zbiór znormalizowanych i rozszerzalnych schematów danych. Te predefiniowane schematy obejmują różne typy danych, w tym artefakty operacyjne, artefakty fizyczne, materiały referencyjne i dzienniki zdarzeń. Reprezentując szeroko stosowane koncepcje i działania, takie jak zlecenia pracy i jednostki, schematy te ułatwiają tworzenie, kompilowanie i analizowanie danych. Ta standaryzacja pomaga usprawnić obsługę danych w różnych systemach.
Wspólny model danych w komplementarności
Tabele Tulip odgrywają kluczową rolę w obsłudze przepływów danych i utrzymywaniu połączenia między aplikacjami. Zawierają informacje, które są wyświetlane w aplikacjach, a aplikacje tworzą, aktualizują i usuwają rekordy tabeli. Jeśli wiele aplikacji korzysta z tych samych tabel, mogą one komunikować się ze sobą za pośrednictwem tabel.
Na przykład menedżer tworzy zlecenie pracy w jednej aplikacji, a operator wykonuje to zlecenie w innej aplikacji lub zestawie aplikacji.
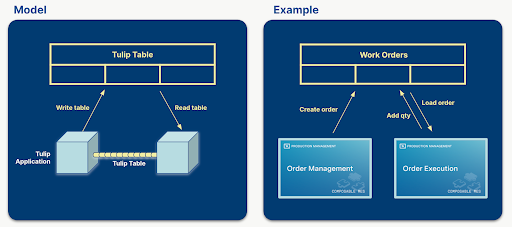
Podczas projektowania rozwiązania dla danego problemu, zdefiniowanie tabel, które będą używane jest jednym z najważniejszych kroków. Logiczny wybór tabel może skutkować prostszymi, bardziej wielokrotnego użytku i komponowalnymi aplikacjami. Jeśli odpowiednia ilość danych jest przechowywana w tabelach, kreator aplikacji może zmniejszyć liczbę używanych zmiennych aplikacji, czyniąc aplikację mniej złożoną i łatwą do dostosowania. Jeśli aplikacje w ramach rozwiązania korzystają z tego samego zestawu tabel, aplikacje stają się wymienne lub komponowalne, bez konieczności przeprojektowywania jednej lub drugiej aplikacji.
Najlepsze praktyki
To understand tables that comprise a common data model, it's important to know the Best Practices for Storing Data in Tulip.
Tabele Tulip powinny być przede wszystkim zgodne z modelem Digital Twin, co oznacza, że tabele powinny jak najdokładniej odzwierciedlać fizyczny zakład lub halę produkcyjną. Dane historyczne aplikacji powinny być ograniczone do Completion Records, zapewniając, że tabele nie są używane do przechowywania danych głównych lub duplikatów danych z Completion Records lub rekordów zewnętrznych.
Podstawowe typy tabel
Najlepiej byłoby, gdyby tabele reprezentowały fizyczne i operacyjne artefakty.
Tabele te zawsze będą zawierać pole Status, które będzie regularnie aktualizowane przez aplikacje.
Poniższy diagram przedstawia pełne tabele we Wspólnym Modelu Danych oraz tabele, których należy używać w przypadku produkcji dyskretnej i zastosowań farmaceutycznych.
Poniżej znajduje się zestawienie wszystkich typów tabel we Wspólnym Modelu Danych:
Fizyczne artefakty
Fizyczne artefakty to namacalne obiekty w zakładzie lub komponenty, które są używane lub produkowane podczas operacji. Gdy stan fizycznego artefaktu zmienia się lub aktualizuje, zmiana ta jest odzwierciedlana w rekordzie (np. zmiana statusu).
Istnieją dwie kategorie artefaktów fizycznych:
1. ZasobyZasobyobejmują komponenty, które wyposażają, zawierają lub działają w procesie, takie jak: * Urządzenia * Wagi * Lokalizacje
2. MateriałyMateriałyobejmują elementy używane lub tworzone w procesie, takie jak: * Pozycje magazynowe * Jednostki * Partie
Artefakty operacyjne
Artefakty operacyjne to materialne lub niematerialne elementy lub komponenty, które umożliwiają lub wspierają operacje.
Istnieją trzy kategorie artefaktów operacyjnych:
1. ZadaniaZadaniaobejmują proces, który można wykonać, np: * Wyniki inspekcji * Karty Kanban
2. ZdarzeniaZdarzeniaobejmują coś, co się wydarzyło, np: * Wady * Korekty
3. ZamówieniaZamówieniazawierają informacje o towarach lub zobowiązaniach, takie jak: * Zlecenia pracy * Zlecenia przetwarzania
Dodatkowe (zaawansowane) typy tabel
Są chwile, kiedy może być konieczne rozważenie złamania najlepszych praktyk. W bardziej zaawansowanych okolicznościach - i tak oszczędnie, jak to możliwe - może być konieczne użycie następujących dwóch drugorzędnych typów tabel:
- Dziennik
- Odniesienie
Dane w tych tabelach będą prawdopodobnie statyczne i nie będą aktualizowane (dlatego preferowane jest przechowywanie tego typu danych w rekordach uzupełniania lub w oryginalnym, zewnętrznym systemie).
:::(Error)Secondary table types do not fit within a Digital Twin model and should only be considered by advanced users. You should only include these table types once you've gone through the Solution Design process and exhausted all other options. Secondary table types should NEVER serve as the foundation for an app solution.
:::
Dzienniki
Dzienniki zdarzeń to informacje, które można wyszukać i które definiują coś w produkcji. Często można je znaleźć w systemach zewnętrznych, takich jak ERP. Ponieważ dane historyczne są tradycyjnie śledzone przez App Completion i przechowywane w Completion Records, tabeli Log należy używać TYLKO wtedy, gdy:* trzeba oddzielić określone dane od rekordów ukończenia w celu wizualizacji* trzeba użyć tych danych w obliczeniach, w szczególności w zapytaniach i agregacjach.
Przykłady:
- Notatki i komentarze
- Rekordy genealogiczne
- Historia aktywności stacji
- Wyniki inspekcji
NIE należy korzystać z tabel dziennika w celu uzyskania:* Zapisów historycznych* Identyfikowalności
Odniesienia
Referencje są księgami współdzielonymi między aplikacjami. Jest to podobne do koncepcji rekordu ukończenia, z wyjątkiem tego, że jest on współdzielony między aplikacjami i udostępnia zapytania do tabel, Aggregation i zmienność tabel Tulip.
Tam, gdzie to możliwe, dane powinny być pobierane w czasie rzeczywistym bezpośrednio z oryginalnego źródła - takiego jak ERP - za pośrednictwem konektora HTTP. Może zaistnieć potrzeba użycia tabeli referencyjnej w skrajnych przypadkach, takich jak:* Tymczasowo, podczas ustanawiania połączenia z ERP.* Jeśli system zewnętrzny zawiera ograniczone dane referencyjne, które muszą zostać rozszerzone o Tulip.
Podejście będzie ewoluować wraz z upływem czasu, w miarę jak rozwiązania będą dojrzewać, a systemy staną się bardziej zintegrowane i ściśle powiązane.
Przykłady:
- Definicje materiałów
- Zestawienie materiałów
Zbuduj swój własny wspólny model danych
Przykładowy Wspólny Model Danych Tulip został zaprojektowany jako punkt wyjścia do zbudowania własnego modelu danych. Jednak wszystkie procesy i rozwiązania są różne i, podobnie jak aplikacje, model danych można dostosować w razie potrzeby.
Mniejsze zmiany obejmują dodawanie i usuwanie pól z tabel. W niektórych przypadkach (specjalne procesy, wiele tabel potrzebnych do tego samego przypadku użycia) wymagane są większe zmiany. Można to zrobić, zastępując jedną lub więcej tabel z pobranego modelu danych lub wstawiając dodatkowe tabele.
Planowanie wspólnego modelu danych
- Zdefiniuj fizyczne i operacyjne artefakty procesu.
- Znajdź odpowiednie tabele dla każdego artefaktu
- Zbadaj typy danych, które mają być gromadzone przez aplikacje i odniesienia, które muszą być używane.