
Közös SQL Connector funkciók
Ez a cikk leírja, hogyan írhatunk néhány gyakran használt SQL függvényt a Tulip Connectorokban.
Mielőtt elolvassa ezt az útmutatót, olvassa el a másik útmutatót az első SQL-csatlakozófüggvény létrehozásához a Tulipban.
Az alábbiakban felsorolunk néhány egyszerű és gyakran használt SQL Connector függvényt, amelyeket SQL lekérdezésekben használhat:
SELECT utasítás:
MES/ERP-adatbázisában tárolt egy adott MES/ERP-munkamegrendelés adatait szeretné megtekinteni. A SELECT utasítás segíthet ebben a feladatban:
SELECT * FROM table_in_a_adatbázisában_táblából
Ez az összes sort és oszlopot visszaküldi a táblázatából.
Visszaadhat egyetlen sort vagy több sort is. Ha egyetlen sort szeretne visszaadni, adjon feltételeket vagy korlátokat a lekérdezéshez. Ebben az esetben általában a tulipános bemeneteket használják. Az alábbi példában a work_order_number egy Tulip függvény bemenete.
SELECT * FROM table_in_a_adatbázisban WHERE column_1 = $work_order_number$
Ha több sort szeretne visszaadni, győződjön meg róla, hogy bejelölte a "Return Multiple Rows?" (Több sor visszaadása?) alatti négyzetet.
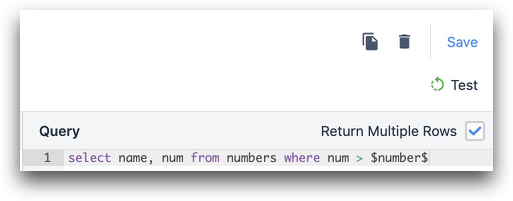
Adatok visszaküldése
Ha az adatbázis oszlopnevei megegyeznek a csatlakozófüggvényben definiált kimeneti nevekkel, a Tulip automatikusan hozzárendeli a lekérdezés eredményeit a függvény kimeneteihez. Példa: A Tulip kimenete output_1, és az adatbázis oszlopa szintén output_1.
Ha az adatbázisban lévő oszlopnevek eltérnek attól, amit a Tulipban szeretne használni, akkor alias használatával kell a kettő közötti megfelelő asszociációt létrehoznia.
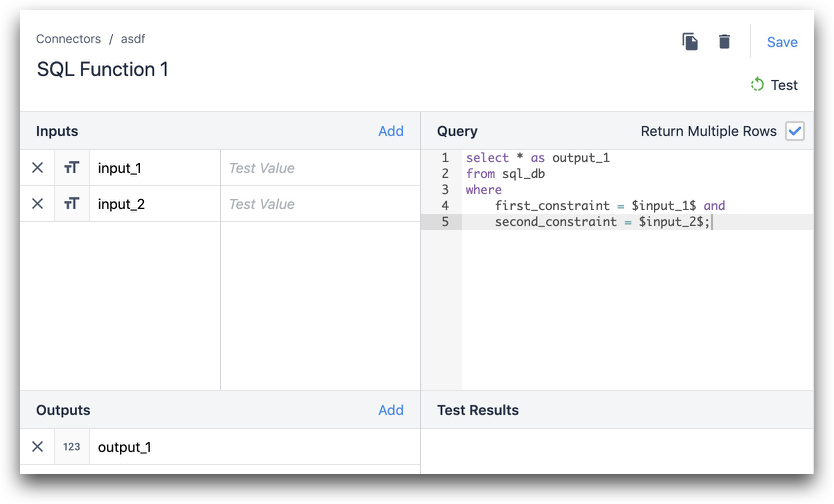
Az alábbi példában az oszlop_1 az adatbázisból származik, az output_1 pedig a Tulip kimenet.
SELECT column_1 as output_1 FROM table_in_a_adatbázisban, ahol első_korlátozás = $input_1$ és második_korlátozás = $input_2$;
INSERT utasítás:
Tekintsünk egy olyan forgatókönyvet, amelyben egy Tulip alkalmazásból származó adatokkal szeretne beilleszteni a MES/ERP-be. Egy egyszerű INSERT függvényt használna a feladat elvégzéséhez. Íme egy példa arra, hogyan néz ki ez a függvény SQL-ben:
INSERT INTO table_in_a_adatbázisban (username, user_id, product_id) VALUES ($username$, $user_id$, $product_id$)
Most pedig bontsuk le a függvény egyes részeit:
Az adatbázisban lévő tábla azonosítása
INSERT INTO table_in_a_adatbázisod_táblájába
Válassza ki az adatbázis oszlopait
(username, user_id, product_id)
Definiálja az értékeket a Tulipból
VALUES ($username$, $user_id$, $product_id$)
UPDATE utasítás:
Gondoljunk egy olyan forgatókönyvre, amelyben a MES/ERP rendszerét szeretné frissíteni a Tulip alkalmazásból származó adatokkal, egy munkamegrendelést használva kulcsként. Az UPDATE funkciót használná az alábbiakban bemutatott módon:
UPDATE table_in_a_adatbázisban SET column_1 = $input_1$, column_2 = $input_2$ WHERE work_order = $work_order$.
Most pedig bontsuk le ennek a függvénynek az egyes részeit:
Az adatbázisban lévő tábla azonosítása
UPDATE table_in_a_adatbázisodban
A Tulip adatokkal frissítendő oszlopok meghatározása
SET column_1 = $input_1$, column_2 = $input_2$
Használja feltételként a munkamegrendelést
WHERE munkarend = $munkarend$
További olvasmányok
Megtalálta, amit keresett?
A community.tulip.co oldalon is megteheti, hogy felteszi kérdését, vagy megnézheti, hogy mások is szembesültek-e hasonló kérdéssel!