Query Tulip Tables with a Glue ETL Script to simplify moving data from Tulip to Redshift (Or other data clouds)
Purpose
This script provides a simple starting point for querying data on Tulip Tables and moving to Redshift or other Data Warehouses
High-level Architecture
This high-level architecture can be used to query data from Tulip's Tables API and then saved to Redshift for further analytics and processing.
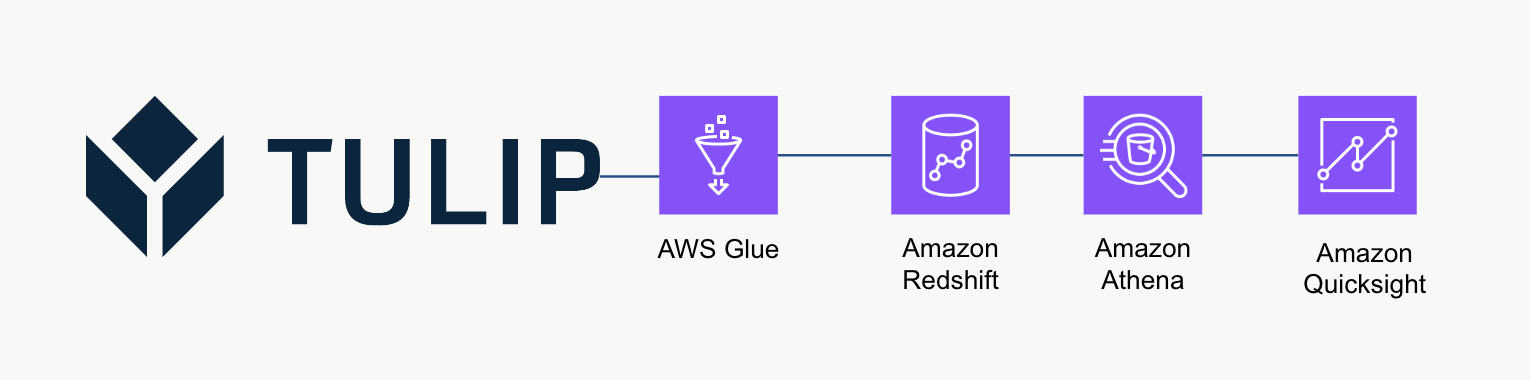
Example Script
The example script below shows how to query a single Tulp Table with Glue ETL (Python Powershell) and then write to Redshift. NOTE: For scaled production use cases, writing to a temporary S3 bucket and then copying the bucket contents to S3 is recommended instead. Additionally, the credentials are saved via AWS Secrets Manager.
import sys
import pandas as pd
import numpy as np
import requests
import json
import boto3
from botocore.exceptions import ClientError
from sqlalchemy import create_engine
import sqlalchemy as sa
from sqlalchemy.engine.url import URL
import psycopg2
from datetime import datetime
import logging
logger = logging.getLogger()
table_id = 'aKzvoscgHCyd2CRu3_DEFAULT'
def get_secret(secret_name, region_name):
# Create a Secrets Manager client
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name
)
try:
get_secret_value_response = client.get_secret_value(
SecretId=secret_name
)
except ClientError as e:
# For a list of exceptions thrown, see
# https://docs.aws.amazon.com/secretsmanager/latest/apireference/API_GetSecretValue.html
raise e
return json.loads(get_secret_value_response['SecretString'])
redshift_credentials = get_secret(secret_name='tulip_redshift', region_name='us-east-1')
api_credentials = get_secret(secret_name='[INSTANCE].tulip.co-API-KEY', region_name='us-east-1')
# build SQL engine
url = URL.create(
drivername='postgresql',
host=redshift_credentials['host'],
port=redshift_credentials['port'],
database=redshift_credentials['dbname'],
username=redshift_credentials['username'],
password=redshift_credentials['password']
)
engine = sa.create_engine(url)
header = {'Authorization' : api_credentials['auth_header']}
base_url = 'https://william.tulip.co/api/v3'
offset = 0
function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all'
r = requests.get(base_url+function, headers=header)
df = pd.DataFrame(r.json())
length = len(r.json())
while length > 0:
offset += 100
function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all'
r = requests.get(base_url+function,
headers=header)
length = len(r.json())
df_append = pd.DataFrame(r.json())
df = pd.concat([df, df_append], axis=0)
# capture date-time stamp
now = datetime.now()
df['datetime_updated'] = now
# write to Redshift
df.to_sql('station_activity_from_glue', engine, schema='product_growth', index=False,if_exists='replace')
Scale Considerations
Consider using S3 as an intermediary temporary storage to then copy data from S3 to Redshift instead of writing it directly to Redshift. This can be more computationally efficient.
Additionally, you can also use metadata to write all Tulip Tables to a Data Warehouse instead of one-off Tulip Tables
Finally, this example script overwrites the entire table each time. A more efficient method would be to update rows modified since the last update or query.
Next Steps
For further reading, please check out the Amazon Well-Architected Framework. This is a great resource for understanding optimal methods for data flows and integrations