
Guidance for adhering to a Common Data Model and examples of how to create one.
What is a Common Data Model?
Designing a robust, scalable data model is one of the most difficult challenges in building a production system. The Common Data Model (CDM) provides guidance to ensure your digital transformation scales from day one.
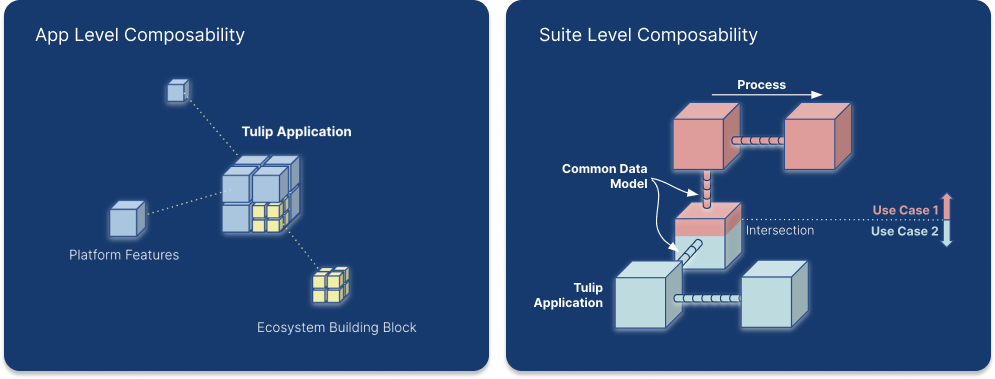
Applications can be combined to solve use cases, connecting across manufacturing processes using tables in the Tulip Common Data Model. Unlike traditional data models that rely on dependencies, Tulip's composable Common Data Model allows tables to be added over time on a case by case basis.
A Common Data Model provides a collection of standardized and expandable data schemas. These predefined schemas cover various types of data, including operational artifacts, physical artifacts, reference materials, and logs of events. By representing widely used concepts and activities, such as Work Orders and Units, these schemas make it easier to create, compile, and analyze data. This standardization helps streamline data handling across different systems.
Examples
Common Data Model in Composability
Tulip Tables play a crucial role in handling data flows and maintaining the connection between applications. They contain information that is displayed in applications and applications are creating, updating and deleting Table Records. If multiple applications are using the same tables, they can communicate with each other through tables.
For example, a manager creates a work order in one app and an operator executes that work order in another app or set of apps.
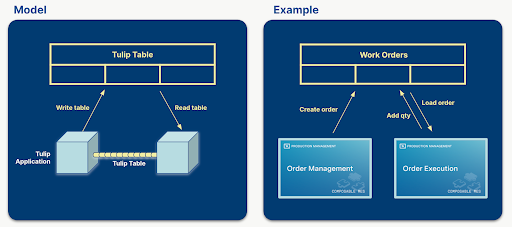
When designing a solution for a given problem, defining the tables that are going to be used is one of the most important steps. Choosing tables logically can result in simpler, more reusable, and composable applications. If the right amount of data is stored in tables, the app builder can reduce the number of app variables used, making the application less complex and easier to customize. If the applications within a solution use the same set of tables, the apps become interchangeable or composable, without having to redesign one or the other application.
Base Table Version
The Base Table Version of the Common Data Model is the foundational structure that defines the essential, system wide attributes of an entity. It includes only the minimal set of universally required fields shared across all processes.
Its purpose is to provide a reusable, stable foundation for data management. It acts as the single source of truth and can be expanded through extensions without modifying or duplicating the original schema.
Table Extensions
Table extensions provide a modular way to enhance an existing table by adding domain specific fields without altering its core schema. When an extension is imported, its fields are automatically merged into the corresponding existing table instead of creating a new one.
This approach keeps Tulip tables clean, modular, and highly adaptable. By storing extensions in separate workspaces, the core tables remain lightweight while still supporting both simple and complex deployment needs.
Table Kits
A Table Kit is a single downloadable app that contains only pre-structured, interconnected data tables for specific manufacturing use cases. Table Kits provide the data foundation to build your custom workflows without any pre-built user interface or processes.
Available Table Kits include:
- Tulip Common Data Model Base Kit: The base for any discrete manufacturing use case
- Production Management Kit: Manage shop floor operations with tables for Units, Orders, Events, and Stations
- Production Starter Kit: Jumpstart digital production workflows with tables for Orders, Units, and Stations
- Quality Kit: Pre-built data structures for inspections, samples, units, equipment, and defects
- Quality Dashboard Kit: Ready to use tables for building dynamic Quality Dashboards
- Material Traceability Kit: End to end material visibility with tables for Units, Orders, BOM, and Material Definitions
- Inventory Management Kit: Manage inventory with location and stock level tracking tables
Build your own Common Data Model
Tulip's Common Data Model is designed to be a starting point to build your data model. However, all processes and solutions are different and, like applications, the data model can be customized as needed.
Smaller changes include adding and removing fields from the tables. In some cases (special processes, multiple tables needed for the same use case) major changes are required. This can be done by substituting one or more tables from the downloaded data model or inserting additional tables.
Plan a Common Data Model
- Define the artifacts of your process
- Find the respective tables for each artifact
- Explore the types of data to be collected by the applications and the references that need to be used
Further Reading
For questions or to share your approach, visit the Tulip Community.
.gif)