
In this guide, you will learn:
- When to store data in Tulip vs an external system
- How to pull data from other systems
- What you need to integrate a system with Tulip
Operations often pull data from multiple sources, in Tulip and external. For external data sources, you’ll need to connect via Tulip.
Establishing secure data connections may require IT personnel.
When to store data in Tulip vs an external system
In Tulip, you can store data in two places:
- Tables
- Completions
Tulip data (e.g.process data, work-instructions, equipment) directly updates from your digital operations.
But what about data you reference in production that is stored elsewhere? This can include:
- ERP/WMS Systems
- Legacy MES
- Databases
- PLM (e.g. for BOM)
- Quality Management System (QMS)
You can interact with external data in various ways, depending on what you use the data for (i.e. reading and writing data to API/SQL database or viewing management data for production reference).
A single source of truth is an essential component to accurate, real-time data. A source of truth ensures that data is not duplicated or represented in multiple places.
Both Tulip data and external data are respective sources of truth, and niether should be substituted or replicated:
- An external system provides clear requirements, business metrics, or customer data for digital workflow context
- Tulip data contains operational and process data for real-time reporting
This diagram shows the separation of data from Tulip and an ERP:
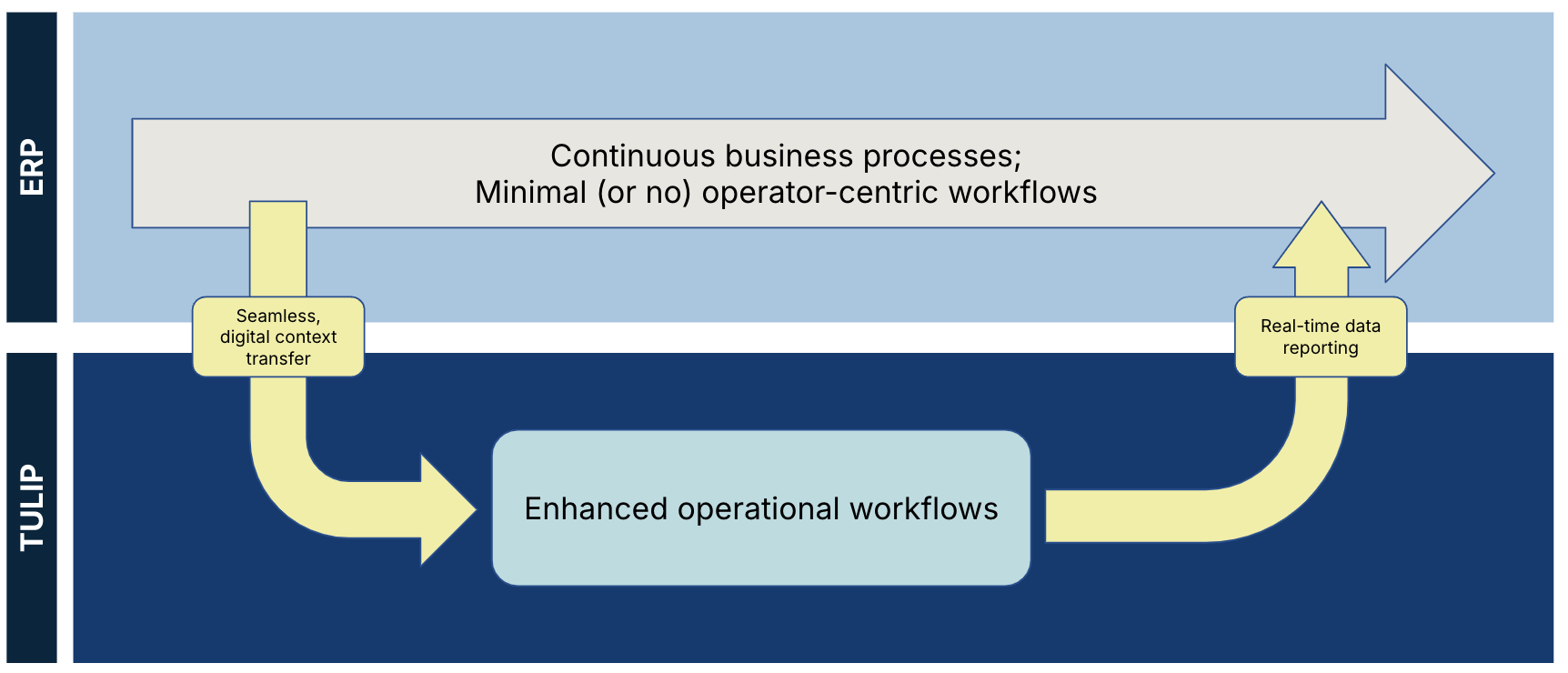
You should only use data from external sources on an as-needed basis. This practice means that another system can provide contextual information for production while Tulip data enhances information from an external source.
How do you know if you should use external data?
- Are you getting minimum value from the solution without integration?
- Are you able to integrate quickly (less than a month)?
Integrations should unlock a tier of value, but they aren’t typically essential for potential value.
Example: Work orders from an ERP
- Work orders are stored in an ERP
- A Tulip management app retrieves work order from ERP
- Management app creates a record of the work order in a Tulip table to store production data
- Work instructions and assembly apps capture production data in the Work order table and compliant process data in completions
Open Ecosystem
An open ecosystem leverages multuple, connected solutions to meet an organization's unique needs. Rather than using one system for everything, Tulip's open ecosystem approach prioritizes Composability over top-down control.
The diagram below shows how Tulip's digital capabilities integrate with other systems.
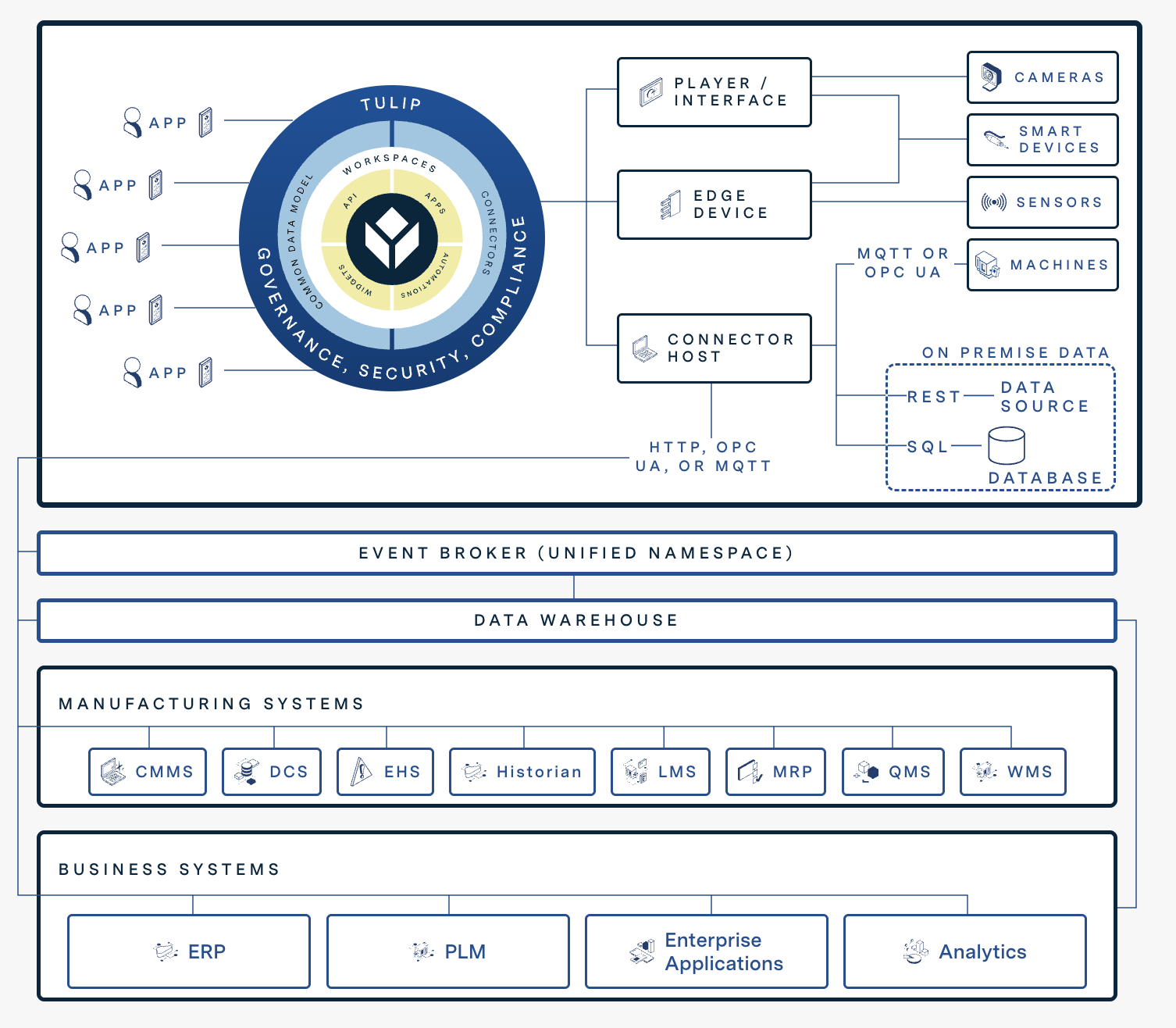
System Integration
System integrations typically do not need to be in the first step when deploying. Tulip recommends you first build your minimal valuable product without a system integration, then make adjustments as needed. This is because system integrations can take up to several months to set up.
A system integration with Tulip usually involves 3 factors:
- The abilities and parameters of the system itself
- The complexity of your company’s IT environment
- Your IT team’s capabilities for working with the system
Integrations are not all or nothing – you should focus on defining the minimal data needed to provide operational context in an app.
The diagram below shows a typical ERP integration with Tulip:
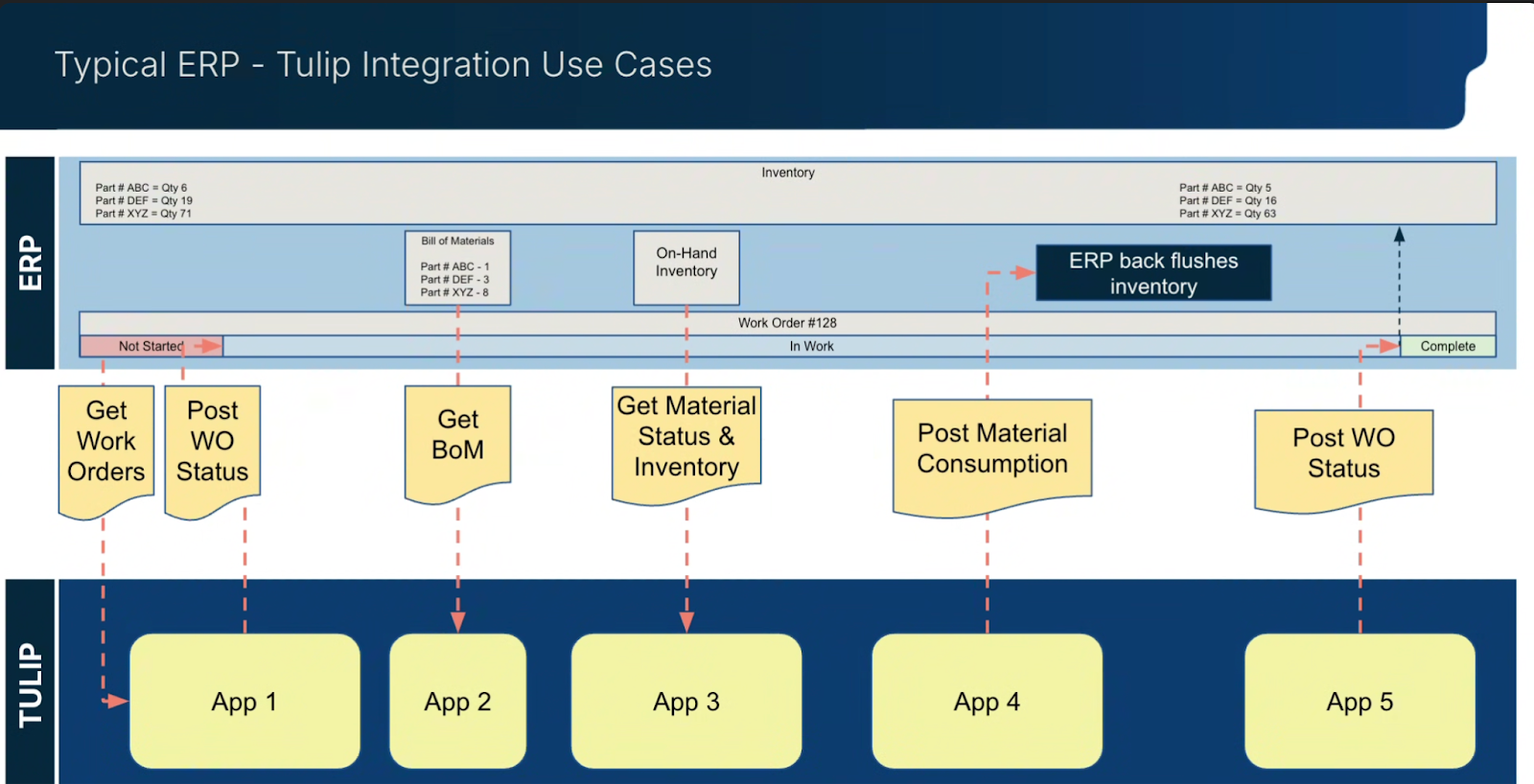
Learn more about how to plan an integration here.
Integration data flow
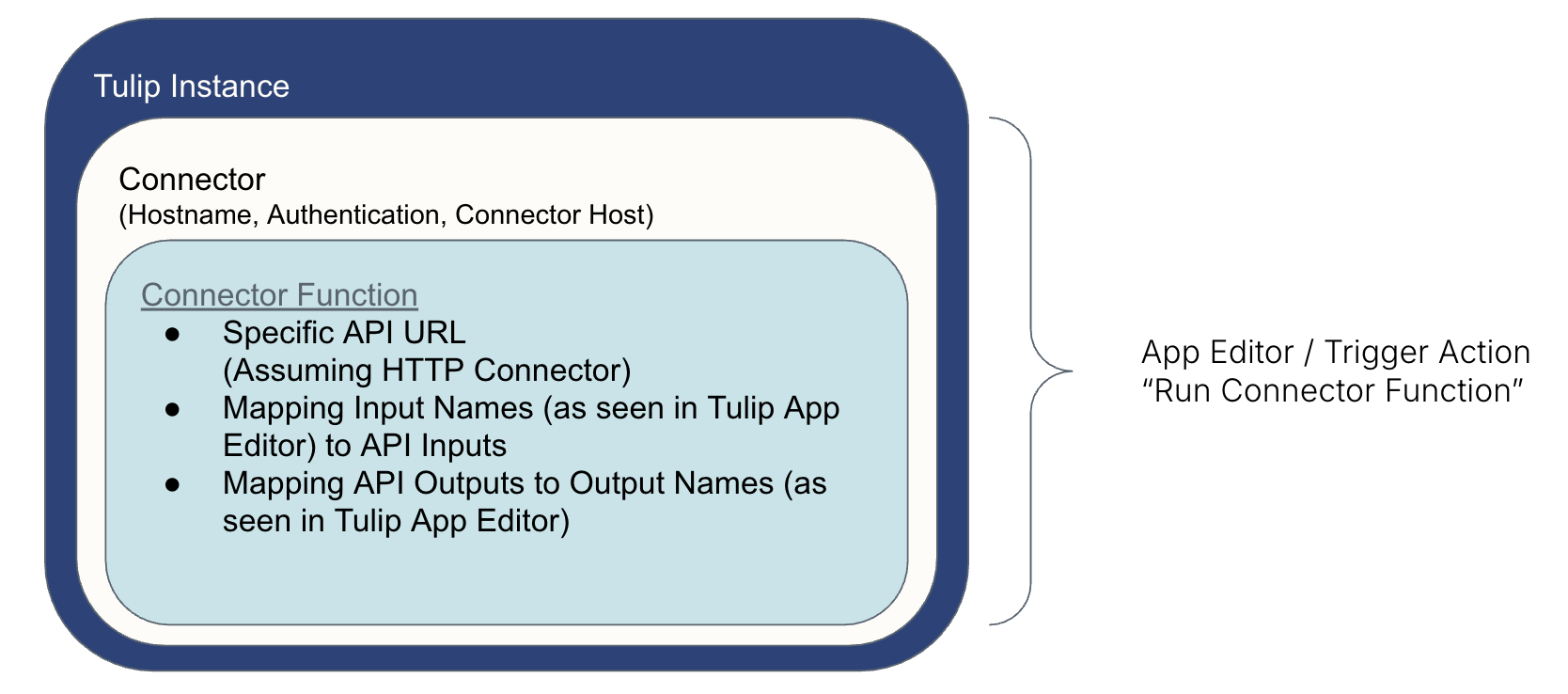
The way Tulip “talks” to an external system is with the following set up:
- A Connector uses secure parameters to get “access” to the system
- A Connector Function commands the information to/from the system
- A trigger action (created in the App Editor) runs the connector function (ex. on a button press)
How do you connect to a system?
Let’s explore and break down the features that make these connections possible.
Connectors
Connectors are Tulip’s framework for creating connections between Tulip and third party systems. They’re powerful integrations for viewing, managing, and interacting with data from external systems in applications.
What to use connectors for
Connectors are how Tulip talks to external systems. The tools in your stack and the degree of integration required in your applications determines how you use connectors.
Some use-cases for connectors include:
- Getting information from a Source of Truth (e.g. Work Orders from your ERP)
- Posting Material Consumption (e.g. to your ERP)
- Sending a Slack message
How connectors work
Connectors establish a connection between Tulip and a third-party system. They handle the direction and authentication which allows data to transact.
The transaction of data is made possible through a Connector Host. Connector hosts allow Tulip to connect with external systems, acting as a direct link between the two. Tulip provides a Cloud Connector Host for use, but you can also use an on-premise connector host.
Learn more about connector hosts here.
While the connector host establishes the connection, Connector Functions make your connectors do things including pulling information, writing to tables, and editing existing data. Connector functions request actions to the third party system which goes through the connector host.
You can also set modifications to your function, such as query parameters and responses, which dictate the data that is returned. While prior knowledge of JSON is not required, familiarity with aspects such as Dot Notation and general data structure are useful to better understand your connector functions.
Types of Connectors
In order to understand the different systems you can connect to, it's important to note that there are three different types of connectors which extract information from different sources:
HTTP
HTTP connectors access data from external APIs. They are the most commonly used connector. HTTP Connectors can interface with most types of HTTP APIs, including REST and SOAP.
HTTP connector functions can make the following types of API Call:
- GET
- HEAD
- POST
- PUT
- BATCH
- DELETE
SQL
SQL connectors access data from external databases. With a SQL connector you can alter tabled data, retrieve data, and manipulate an existing data set.
Tulip supports the following SQL connectors:
- Microsoft SQL Server
- PostgreSQL
- MySQL
- Oracle
Access HTTP and SQL connectors through the Connectors page in your instance.
MQTT
Connect to MQTT brokers for machine monitoring. Tulip can natively publish data from its product to your MQTT broker, integrating seamlessly into a Unified Namespace or enterprise event bus.
The following fields can be defined for an MQTT connector function:
- Quality of Service
- Topic
- Retain Message
- Payload
- User Defined Inputs
Edge Connectivity
Some of these machines include Edge Devices, which you can read about here:
Table API
Using connectors, a Tulip app can initiate an HTTP or SQL query. With the Tulip API, you can communicate with and integrate Tulip from external systems. This API works by bringing data into Tulip from another system and allowing you to write to those other systems.
The Table API has various capabilities, including:
- Update a Table Record
- Create a Table
- Find the counts of table records
The Tulip API currently only works with Tulip Tables. To use the Table API, you must have a basic understanding of how APIs work.
Access Tulip API documentation here.
To practice using the Table API, take the Tulip University course: Feature Deep Dive: Table API.
Next Steps
Learn more about integrations and start connecting:
Did you find what you were looking for?
You can head over to community.tulip.co to post your question or see if others have faced a similar question!

.gif)