Streamline fetching data from Tulip to AWS for broader analytics and integrations opportunities
Purpose
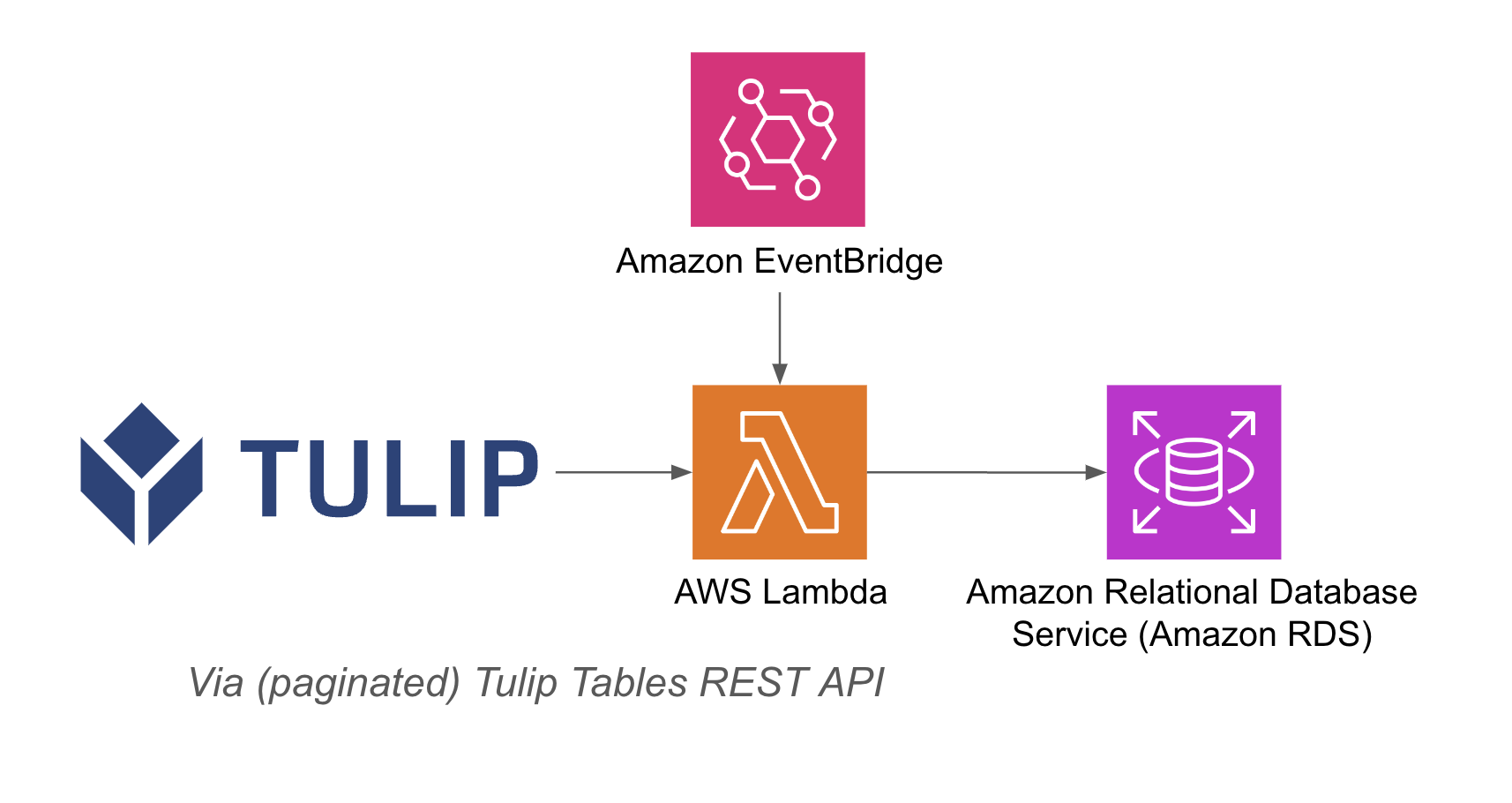
This guide walks through step by step how to fetch all Tulip Tables data AWS via a Lambda function.
This goes beyond the basic fetch query and iterates through all tables in a given instance; this can be great for a weekly ETL job (Extract, Transform, Load)
The lambda function can be triggered via a variety of resources such as Event Bridge timers or an API Gateway
An example architecture is listed below:
Setup
This example integration requires the following:
- Usage of Tulip Tables API (Get API Key and Secret in Account Settings)
- Tulip Table (Get the Table Unique ID
High-level steps:
- Create an AWS Lambda function with the relevant trigger (API Gateway, Event Bridge Timer, etc.)
- Fetch the Tulip table data with the example below
import json
import pandas as pd
import requests
from sqlalchemy import create_engine
import os
def lambda_handler(event, context):
# initialize db
host = os.getenv('host')
user = os.getenv('username')
password = os.getenv('password')
db = os.getenv('database')
engine_str = f'postgresql://{user}:{password}@{host}/{db}'
engine = create_engine(engine_str)
api_header = {'Authorization' : os.getenv('tulip_api_basic_auth')}
instance = os.getenv('tulip_instance')
base_url = f'https://{instance}.tulip.co/api/v3'
get_tables_function = '/tables'
r = requests.get(base_url+get_tables_function, headers=api_header)
df = pd.DataFrame(r.json())
# Function to convert dictionaries to strings
def dict_to_str(cell):
if isinstance(cell, dict):
return str(cell)
return cell
# query table function
def query_table(table_id, base_url, api_header):
offset = 0
function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all'
r = requests.get(base_url+function, headers=api_header)
df = pd.DataFrame(r.json())
length = len(r.json())
while length > 0:
offset += 100
function = f'/tables/{table_id}/records?limit=100&offset={offset}&includeTotalCount=false&filterAggregator=all'
r = requests.get(base_url+function, headers=api_header)
length = len(r.json())
df_append = pd.DataFrame(r.json())
df = pd.concat([df, df_append], axis=0)
df = df.apply(lambda row: row.apply(dict_to_str), axis=1)
return df
# create function
def write_to_db(row, base_url, api_header):
table = row['label']
id = row['id']
df = query_table(id, base_url, api_header)
df.to_sql(table,engine, if_exists='replace', index=False)
print(f'wrote {table} to database!')
# iterate through all tables:
df.apply(lambda row: write_to_db(row, base_url, api_header), axis=1)
return { 'statusCode': 200, 'body': json.dumps('wrote to db!')}
- The trigger can run on a timer or triggered via a URL
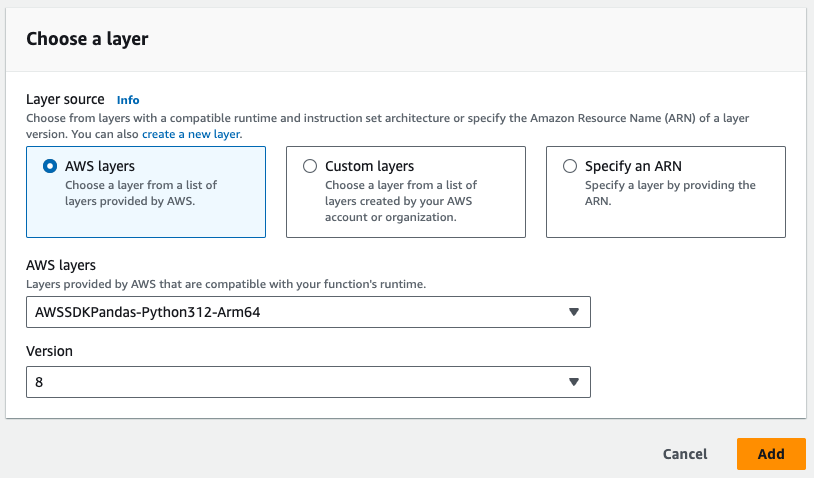
- Note the Pandas layer required in the image below
Use Cases and Next Steps
Once you have finalized the integration with lambda, you can easily analyze the data with a sagemaker notebook, QuickSight, or a variety of other tools.
1. Defect prediction
- Identify production defects before they happen and increase right first time.
- Identify core production drivers of quality in order to implement improvements
2. Cost of quality optimization
- Identify opportunities to optimize product design without impact customer satisfaction
3. Production energy optimization
- Identify production levers to optimal energy consumption
4. Delivery and planning prediction and optimization
- Optimize production schedule based on customer demand and real time order schedule
5. Global Machine / Line Benchmarking
- Benchmark similar machines or equipment with normalization
6. Global / regional digital performance management
- Consolidated data to create real time dashboards