
Fonctions courantes du connecteur SQL
Cet article décrit comment écrire quelques fonctions SQL couramment utilisées dans Tulip Connectors.
Avant de lire ce guide, consultez notre autre tutoriel pour créer votre première fonction de connecteur SQL dans Tulip.
Vous trouverez ci-dessous quelques fonctions de connecteur SQL simples et couramment utilisées que vous pouvez utiliser dans vos requêtes SQL :
Déclaration SELECT :
Considérez un scénario dans lequel vous aimeriez voir les détails d'un ordre de travail particulier qui est stocké dans votre base de données MES/ERP. L'instruction SELECT peut nous aider dans cette tâche :
SELECT * FROM table_in_votre_base_de_données
Cette instruction renvoie toutes les lignes et colonnes de votre table.
Vous pouvez renvoyer une seule ligne ou plusieurs lignes. Si vous souhaitez retourner une seule ligne, ajoutez des conditions ou des limites à votre requête. Les entrées de type tulipe sont couramment utilisées dans ce cas. Dans l'exemple ci-dessous, work_order_number est une entrée de fonction Tulip.
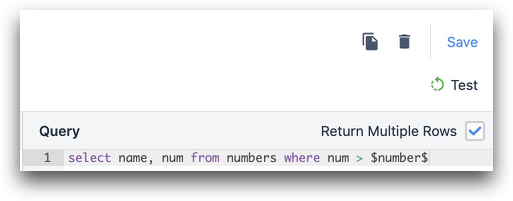
SELECT * FROM table_dans_votre_base_de_données WHERE column_1 = $numéro_de_commande_de_travail$.
Si vous souhaitez renvoyer plusieurs lignes, assurez-vous de cocher la case "Renvoyer plusieurs lignes".
Renvoi des données
Si les noms des colonnes de la base de données correspondent aux noms des sorties que vous avez définis dans la fonction du connecteur, Tulip associera automatiquement les résultats de la requête aux sorties de la fonction. Exemple : La sortie de Tulip est output_1 et la colonne de la base de données est également output_1
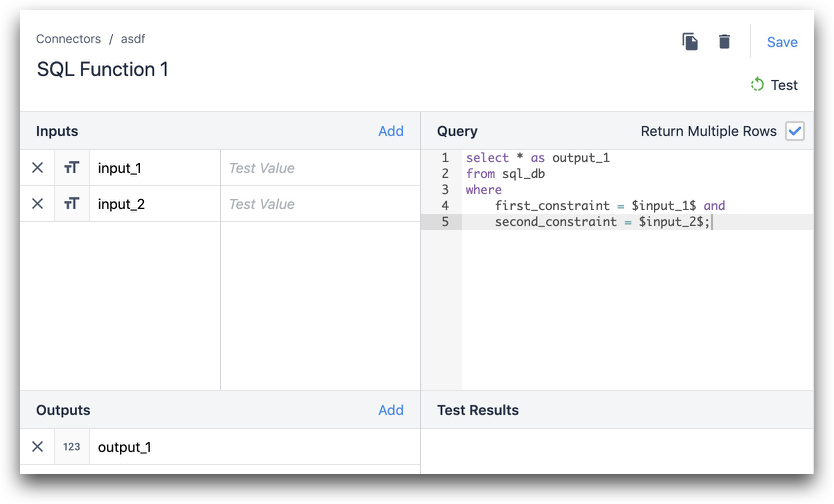
Si les noms des colonnes de votre base de données diffèrent de ceux que vous souhaitez utiliser dans Tulip, vous devez utiliser un alias pour faire l'association correcte entre les deux.
Dans l'exemple ci-dessous, column_1 provient de la base de données et output_1 est la sortie de Tulip.
SELECT column_1 as output_1 FROM table_in_your_database where first_constraint = $input_1$ and second_constraint = $input_2$ ;
Déclaration INSERT :
Considérons un scénario dans lequel vous souhaiteriez insérer dans votre MES/ERP des données provenant d'une application Tulip. Vous utiliserez une simple fonction INSERT pour réaliser cette tâche. Voici un exemple de ce à quoi ressemble cette fonction en SQL :
INSERT INTO table_in_your_database (username, user_id, product_id) VALUES ($username$, $user_id$, $product_id$)
Décomposons maintenant chaque partie de cette fonction :
Identifiez la table dans votre base de données
INSERT INTO table_in_votre_base_de_données
Choisissez les colonnes de votre base de données
(nom d'utilisateur, id_utilisateur, id_produit)
Définir les valeurs à partir de Tulip
VALUES ($username$, $user_id$, $product_id$)
Déclaration UPDATE :
Considérons un scénario dans lequel vous voudriez mettre à jour votre MES/ERP avec des données provenant d'une application Tulip, en utilisant un bon de travail comme clé. Vous utiliserez la fonction UPDATE, comme indiqué ci-dessous :
UPDATE table_in_your_database SET column_1 = $input_1$, column_2 = $input_2$ WHERE work_order = $work_order$.
Décomposons maintenant chaque partie de cette fonction :
Identifiez la table dans votre base de données
UPDATE table_in_votre_base_de_données
Définir les colonnes à mettre à jour avec les données de Tulip
SET column_1 = $input_1$, column_2 = $input_2$.
Utiliser l'ordre de travail comme condition
WHERE ordre_de_travail = $ordre_de_travail$.
Pour en savoir plus
Vous avez trouvé ce que vous cherchiez ?
Vous pouvez également vous rendre sur community.tulip.co pour poser votre question ou voir si d'autres personnes ont rencontré une question similaire !